
The series about the implementation of Big Data patterns continues. This time I will focus on a streaming pattern called fan-in ingress.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In the first section I will explain the general idea of fan-in pattern. Later I will show some important points to keep in mind during the implementation time. At the end, I will use Apache Spark and Apache Kafka to implement the fan-in ingress.
Fan-in ingress defined
Fan-in ingress data processing pattern is a method to consolidate the data coming from different sources and to sent so processed data to another place. You can think about it like about streams reduction because multiple streams are aggregated in fewer ones.
Actually, there are different ways to achieve that. The first one exposes a customer for each of reduced streams which will read the events and push them to another "reduced" stream. The following image shows that implementation:
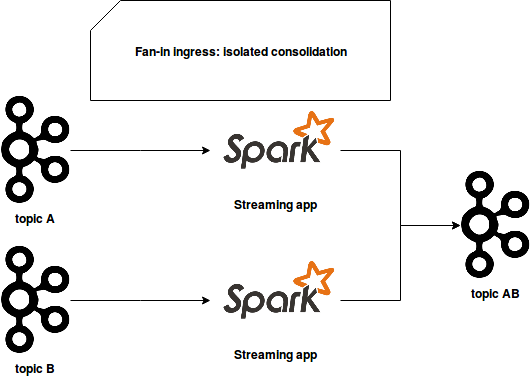
It separates the resources and different producer/consumer pairs. However, the drawback of that approach is that it works when the events concerning a specific entity are all included inside one stream. If it's not the case and the events must be grouped per entity (like customer id), there is another approach. It uses one common consumer that reads the events from different streams and aggregates the records of the same entity:
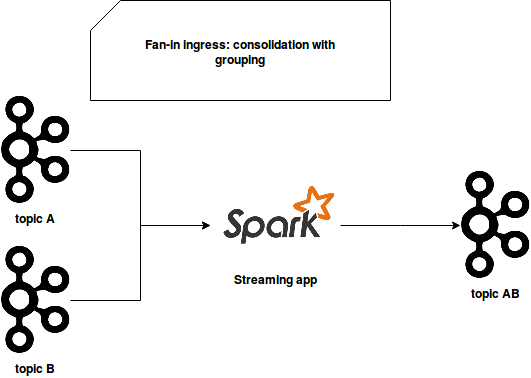
And that's the architecture I will analyze in this post.
Gotchas
However, dealing with multiple streaming sources inside one consumer is challenging. The isolation is broken and the failure of one stream can lead to the failure of the rest of streams. That's not really true for the first schema where one stream's failure won't impact the others.
Another complexity comes from the delivery semantics side. If you need a strong exactly-once delivery semantic, implementing it with multiple streams inside one consumer may be hard, at least when the streaming broker doesn't provide it. It's hard because you will group the events coming from different sources and send them to another stream. In such a case, it's very hard to figure out what has been delivered correctly and what not. Fortunately, modern streaming solutions like Apache Kafka provide the transactions, and therefore, the exactly-once semantic for read-process-write case (link in Read more section).
And finally, even though this approach is a pattern, it may not apply to all use cases. For instance, it will fit great for the situation where the events concerning a given entity are produced almost at the same time to different streams, for example when you have 2 streams of ad impressions and ad clicks. But if the opposite happens and, let's say, the events to consolidate are produced at big intervals, you will either send not consolidated events to the single stream or keep the events in memory during some long time before moving them to the next stage. But this technique introduces the latency which is not a something we want in the streaming pipelines.
Fan-in ingress example
I didn't write the previous section to say that the pattern is bad. I wanted simply to emphasize that it's not so easy as it looks at first glance. I will prove that in this part by making some short experience. The code used for it looks like in the following snippet:
object FanInIngressPattern {
val FailureFlag = true
val RunId = 1
val JsonMapper = new ObjectMapper()
JsonMapper.registerModule(DefaultScalaModule)
def main(args: Array[String]): Unit = {
println(s"Starting test at ${System.nanoTime()}")
// Start producing data
new Thread(DataProducer).start()
try {
val sparkSession = SparkSession.builder()
.appName("Spark-Kafka fan-in ingress pattern test").master("local[*]")
.getOrCreate()
val dataFrame = sparkSession.readStream
.format("kafka")
.option("kafka.bootstrap.servers", KafkaConfiguration.Broker)
.option("checkpointLocation", s"/tmp/checkpoint_consumer_${RunId}")
.option("client.id", s"client#${System.currentTimeMillis()}")
.option("subscribe", s"${KafkaConfiguration.IngressTopic1}, ${KafkaConfiguration.IngressTopic2}")
.load()
import sparkSession.implicits._
val query = dataFrame.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.groupByKey(row => row.getAs[String]("key"))
.mapGroups {
case (key, rows) => {
val ascOrderEvents = if (FailureFlag) {
rows.map(row => {
val inputMessage = JsonMapper.readValue(row.getAs[String]("value"), classOf[InputMessage])
inputMessage.value
})
} else {
rows.map(row => {
Try {
val inputMessage = JsonMapper.readValue(row.getAs[String]("value"), classOf[InputMessage])
inputMessage.value
}
})
.filter(triedConversion => triedConversion.isSuccess)
.map(jsonValue => jsonValue.get)
}
ConsolidatedEvents(key, ascOrderEvents.toSeq.sorted)
}
}.selectExpr("key", "CAST(ascOrderedEvents AS STRING) AS value")
.writeStream
.option("checkpointLocation", s"/tmp/checkpoint_producer_${RunId}")
.format("kafka")
.option("kafka.bootstrap.servers", KafkaConfiguration.Broker)
.option("topic", KafkaConfiguration.ConsolidatedTopic)
.start()
query.awaitTermination(TimeUnit.MILLISECONDS.convert(1, TimeUnit.MINUTES))
query.stop()
} catch {
case e: Exception => e.printStackTrace()
}
// Check what data was written
val consumer = new KafkaConsumer[String, String](KafkaConfiguration.CommonConfiguration)
import scala.collection.JavaConverters._
consumer.subscribe(Seq(KafkaConfiguration.ConsolidatedTopic).asJava)
def mapData(data: Iterator[ConsumerRecord[String, String]]): Seq[String] = {
data.map(record => record.value()).toSeq.toList
}
val data = consumer.poll(Duration.of(1, ChronoUnit.MINUTES))
val values = mapData(data.iterator().asScala)
val duplicatedEvents = values.groupBy(value => value)
.filter {
case (_, values) => values.size > 1
}
println(s"found duplicated events=${duplicatedEvents.mkString("\n")}")
}
}
case class ConsolidatedEvents(key: String, ascOrderedEvents: Seq[String])
case class InputMessage(value: String)
object DataProducer extends Runnable {
override def run(): Unit = {
val kafkaAdmin = AdminClient.create(KafkaConfiguration.CommonConfiguration)
println("Creating topics")
try {
val result = kafkaAdmin.createTopics(Seq(new NewTopic(KafkaConfiguration.IngressTopic1, 1, 1),
new NewTopic(KafkaConfiguration.IngressTopic2, 1, 1), new NewTopic(KafkaConfiguration.ConsolidatedTopic, 1, 1)).asJava)
result.all().get(15, TimeUnit.SECONDS)
} catch {
case e: Exception => {
// Check it but normally do not care about the exception. Probably it will be thrown at the second execution
// because of the already existent topic
e.printStackTrace()
}
}
val producer = new KafkaProducer[String, String](KafkaConfiguration.CommonConfiguration)
while (true) {
(0 to 2)foreach(id => {
val message = FanInIngressPattern.JsonMapper.writeValueAsString(InputMessage(s"n=${System.nanoTime()}"))
producer.send(new ProducerRecord[String, String](KafkaConfiguration.IngressTopic1, message))
})
(1 to 3)foreach(id => {
val message = if (FailureController.canFail()) {
"}"
} else {
FanInIngressPattern.JsonMapper.writeValueAsString(InputMessage(s"n=${System.nanoTime()}"))
}
producer.send(new ProducerRecord[String, String](KafkaConfiguration.IngressTopic2, s"key${id}", message))
})
producer.flush()
Thread.sleep(2000L)
}
}
}
object KafkaConfiguration {
val Broker = "171.18.0.20:9092"
val CommonConfiguration = {
val props = new Properties()
props.setProperty("bootstrap.servers", Broker)
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.setProperty("auto.offset.reset", "earliest")
props.setProperty("group.id", "standard_client")
props
}
val IngressTopic1 = s"ingress_topic_1_${FanInIngressPattern.RunId}"
val IngressTopic2 = s"ingress_topic_2_${FanInIngressPattern.RunId}"
val ConsolidatedTopic = s"consolidated_topic_${FanInIngressPattern.RunId}"
}
object FailureController {
private val CheckNumbers = new AtomicInteger(0)
def canFail(): Boolean = {
if (CheckNumbers.get() == 10 && FanInIngressPattern.FailureFlag) {
true
} else {
CheckNumbers.incrementAndGet()
false
}
}
}
The code is one of possible implementations of fan-in ingress pattern where some data is read from 2 Apache Kafka topics, grouped by some key, and written back to another topic as a consolidated entry. I use here Apache Spark Structured Streaming component and Apache Kafka. As it's stated in the documentation, Apache Kafka sink provides only at-least once guarantee. That's why during the test I will introduce an incorrectly formatted message in one topic to show what may happen because of the lack of isolation. To execute the code I will use the Bitnami's Kafka Docker image executed with docker-compose up command:
version: '3'
services:
zookeeper:
image: 'bitnami/zookeeper:latest'
networks:
kafka-ingress-network:
ipv4_address: 171.18.0.10
ports:
- '2181:2181'
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
volumes:
- 'zookeeper_data:/bitnami'
kafka:
image: 'bitnami/kafka:latest'
networks:
kafka-ingress-network:
ipv4_address: 171.18.0.20
ports:
- '9092:9092'
volumes:
- 'kafka_data:/bitnami'
environment:
- KAFKA_ZOOKEEPER_CONNECT=171.18.0.10:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://171.18.0.20:9092
- KAFKA_DELETE_TOPIC_ENABLE=true
volumes:
zookeeper_data:
driver: local
kafka_data:
driver: local
networks:
kafka-ingress-network:
driver: bridge
ipam:
driver: default
config:
- subnet: 171.18.0.0/16
You can find the results of my experience in the following screencast:
Unsurprisingly, after relaunching the code, the fan-in ingress code reprocessed already processed data. You can see that when the consumer prints the messages accumulated in the consolidated_data topic.
Fan-in ingress is one of messaging patterns that can be used to solve some problems in the data processing. However, working with it can be challenging because of different reasons. Broken isolation brings the risk that the unprocessable data from one source will break the whole processing. I illustrated that in the last section where after one failure, Structured Streaming Kafka sink got the duplicated messages after the restart. It's the point to keep in mind during the implementation of that pattern, even though very often rare duplicates shouldn't cause big problems.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Big Data patterns implemented - fan-in ingress here:
Related blog posts:
- Big Data patterns implemented - automated processing metadata insertion
- Big Data patterns implemented - automated dataset execution
I've just published a new article from #data patterns series. This time it's stream reduction with fan-in ingress pattern, so obviously I illustrated it with #ApacheSpark and #ApacheKafka example https://t.co/ERM1VubaIj
— Bartosz Konieczny (@waitingforcode) April 24, 2019