
Previously we learned how to control data quality with Delta Live Tables. Now, it's time to see an open source library in action, Spark Expectations.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Spark Expectations vs. Delta Live Tables expectations
After the previous blog post introducing Delta Live Tables expectations, a good start here is to compare what we learned last time with what we're going to learn now. Let's begin with the same entry point for both solutions, the decorator. As for DLT, Spark Expectations relies on a Python decorator to annotate the validated DataFrame. You'll find an example below with the @with_expectations decorator applied to a SparkExpectations instance:
from spark_expectations.core.expectations import SparkExpectations
spark_expectations = SparkExpectations(
product_id='user_account_staging_validation',
rules_df=rules_dataframe,
stats_table='dq_stats_table',
stats_table_writer=writer,
target_and_error_table_writer=writer
)
@spark_expectations.with_expectations(
target_table='user_account_staging',
write_to_table=True
)
def build_account_poland_gold_table_staging() -> DataFrame:
pass
After reading this snippet and without entering into implementation details, you should already notice some differences. First, there are some tables. You can see the parameters for a stats table or for a target table. Second, you can also see that the validation is made on top of Apache Spark's DataFrame and the job can run without writing the data to a table (write_to_table=True/False).
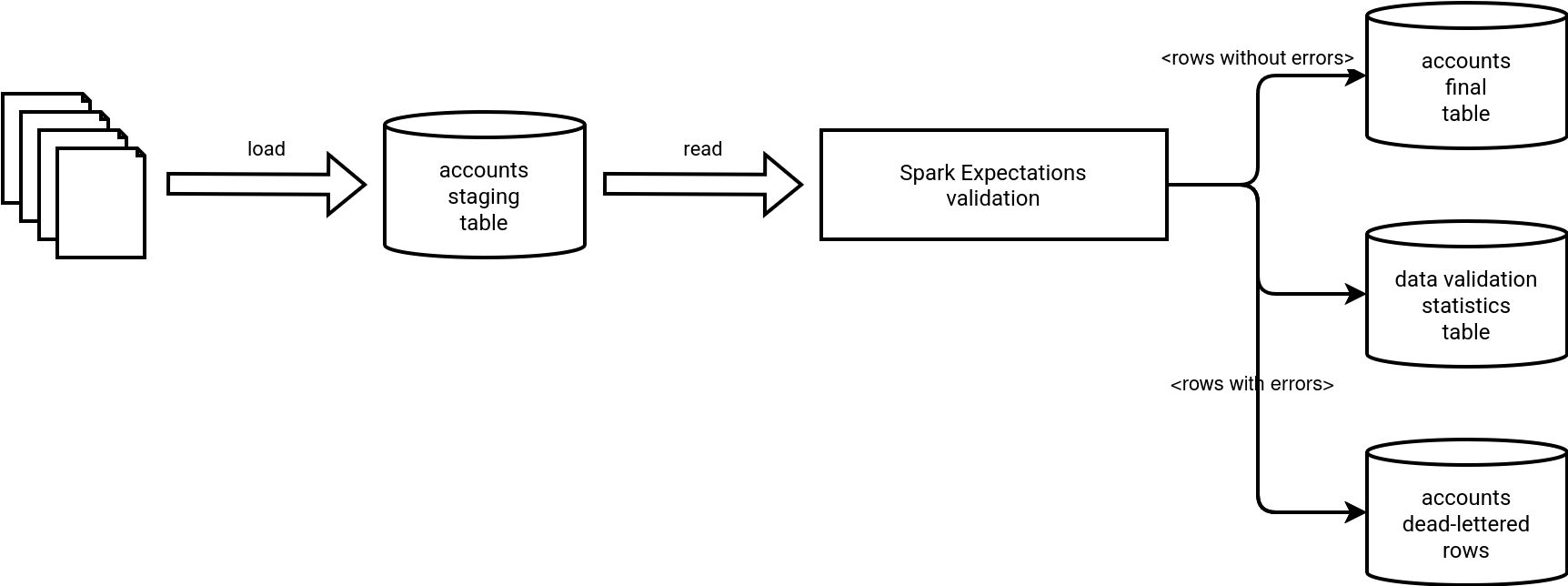
But this is only a high-level view. Spark Expectations is much more. The next picture comes from Spark Expectations repo and greatly illustrates all the capabilities of this library:
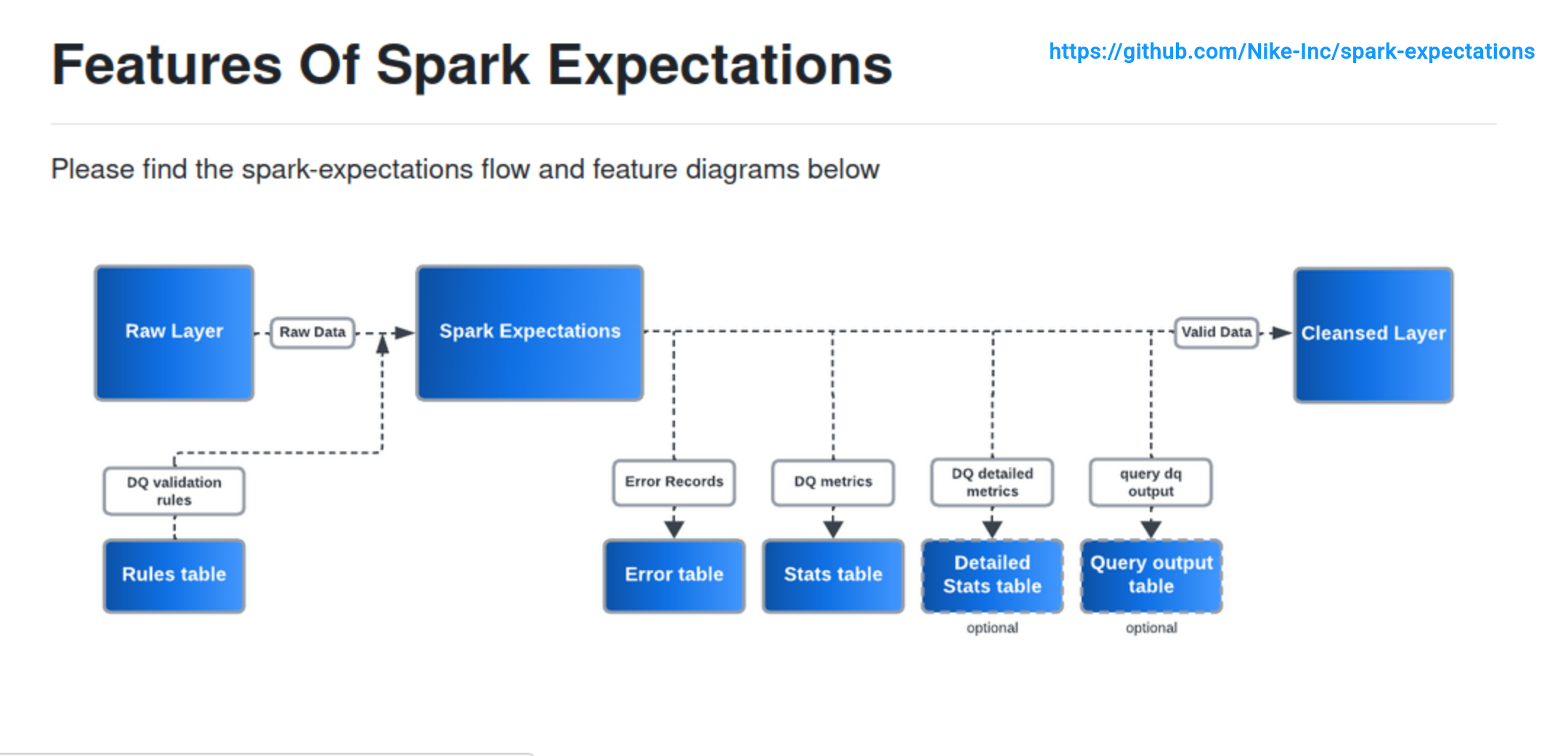
In a nutshell - because we're going to delve into those points later - the involved steps are:
- Definition of data quality rules (expectations). It can be a physical table in Unity Catalog but also anything else that you can read with Apache Spark, so for example a bunch of JSON files or a table in a relational database.
- Next, the expectations apply to the raw data via the Spark Expectations runner. Depending on how you configure the runner, you can benefit from automatic dead-lettering (Error table) and statistics (Stats table and Detailed Stats table).
- Finally, the valid data land to the Cleansed layer.
Configuring Spark Expectations
As you saw in our minimalistic example from the previous section, there are several configuration flags for the with_expectations decorator. To get a better idea what you can do, let's analyze the full signature of the function:
def with_expectations(
self,
target_table: str,
write_to_table: bool = False,
write_to_temp_table: bool = False,
user_conf: Optional[Dict[str, Union[str, int, bool]]] = None,
target_table_view: Optional[str] = None,
target_and_error_table_writer: Optional["WrappedDataFrameWriter"] = None,
) -> Any:
Even though the attributes are self-explanatory, let's explain each of them:
- target_table is the name of the table where the DataFrame returned by the decorated function will be written. However, the writing will only happen if you enable the write_to_table property. Otherwise, the validation will be performed on the in-memory DataFrame. This flag also defines the role of your function. If you disable the writing, your function will be a pure data quality check. In the opposite case, it'll be also responsible for materializing the validated data.
- Besides the target_table and write_to_table, write_to_temp_table is another dataset materialization configuration. If you enable this attribute, Spark Expectations will create a temporary table and use it as the data source for the data quality checks:
def with_expectations( # ... def wrapper(*args: tuple, **kwargs: dict) -> DataFrame: if write_to_temp_table: self.spark.sql(f"drop table if exists {table_name}_temp") # type: ignore source_columns = _df.columns self._writer.save_df_as_table(_df, f"{table_name}_temp", self._context.get_target_and_error_table_writer_config, ) _df = self.spark.sql(f"select * from {table_name}_temp") # type: ignore _df = _df.select(source_columns) - The next property, the target_table_view, is a good explanation for the internal execution details. After applying the row-level data quality checks, Spark Expectations creates a temporary view on top of the evaluated DataFrame. The name of the view is by default set to {target_table}_view but you can override it to make the aggregation-based data quality checks easier to understand.
- Last but not least, the target_and_error_table_writer defines a DataFrame writer. For example, if you needed to write the data in append-only mode to a Delta Lake table, you could create a writer like this:
append_only_writer = WrappedDataFrameWriter().mode("append").format("delta")
Before we go to the user configuration, we can define the data validation workflow. From the previously explained properties you can see the Spark Expectations supports both types of data quality checks; the ones we called last time row-based apply for each row of the input DataFrame, while the ones we considered as complex apply in two places. The first one is the input DataFrame so possibly the dataset with the data quality issues. The second place is the DataFrame without those data quality issues which is created after applying the row-level data quality rules.
💬 Why these different rules?
Ashok Singamaneni, principal data engineer at Nike and one of the core contributors to Spark Expectations, answered a few of my questions. Thank you, Ashok, for your time and interesting insights!
Why does Spark Expectation support the same data quality controls (aggregation and query) at different levels, once for the input DataFrame, once for the output DataFrame?
So, when I started SE - I wanted to have row_dq, agg_dq and query_dq. But when I thought about the order, and discussed with various teams - there could be usecases where [agg_dq and query_dq] can be run on the input dataframe or after row_dq where there might be drop in the records because of which [agg_dq and query_dq] can have varied results.
So the flow is like this:
[agg_dq, query_dq] -> row_dq -> [agg_dq, query_dq]
It is not mandatory to run [agg_dq, query_dq] two times, and can be configured in the rules definition.
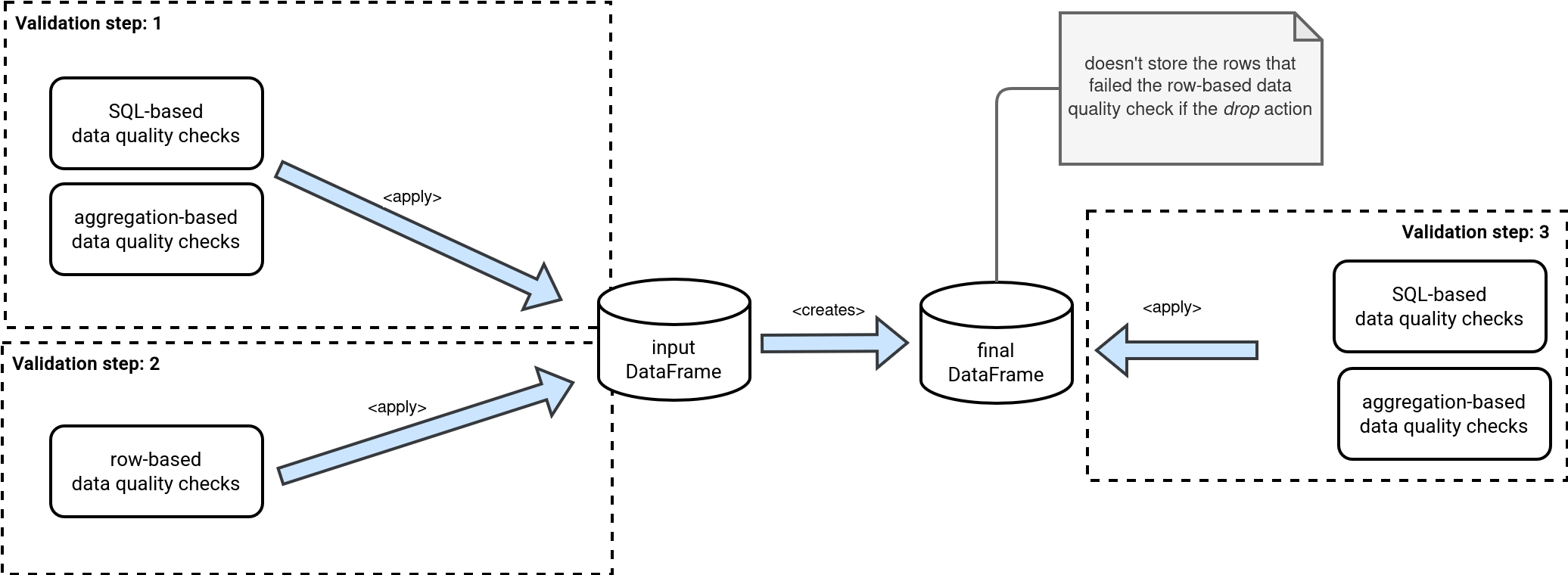
That's how the full workflow may look like. But you, as a user, can configure it and disable some of the steps with the following settings:
- source_agg_dq and source_query_dq to turn off a part or the full validation step 1
- _row_dq to disable the validation step 2
- target_agg_dq and target_query_dq to turn off a part or the full validation step 3. Please notice, both properties are not effective if the _row_dq is disabled. The goal of these target-related actions is to run the aggregation- and query-based data validation rules on top of the dataset without row-based data quality issues.
Put differently, the following will happen:
| Enabled flags | Behavior |
|---|---|
| source_agg_dq, source_query_dq, _row_dq, target_agg_dq, target_query_dq, write_to_table |
|
| source_agg_dq, source_query_dq, write_to_table |
|
| _row_dq, target_agg_dq, target_query_dq, write_to_table |
|
| target_agg_dq, target_query_dq, write_to_table |
|
User configuration
You should know now how to configure the validation workflow, but a few questions remain to answer. The first of them is how to be aware of the data validation results? Remember the user configuration from the previous section? Yes, that's where you can plug Spark Expectations to your alerting system, for example:
se_user_conf = {
user_config.se_notifications_enable_email: True
user_config.se_notifications_email_smtp_host: "waitingforcode.com",
user_config.se_notifications_email_smtp_port: 25,
user_config.se_notifications_smtp_password: "pass"
# ...
You'll find all supported properties in the spark_expectations.config.user_config.
Besides those email-related configuration, you can also set the following flags that impact the behavior of the validation process:
- se_enable_error_table defines whether Spark Expectations should write invalid records to an error table.
- enable_query_dq_detailed_result and enable_agg_dq_detailed_result enable detailed results for query- and aggregation-based rules to be captured to respective detailed_stats tables.
Validation rules
The last aspect to discover before we start playing with Spark Expectations are the validation rules. So far we have identified three types of validation rules that we called row-based, query-based, and aggregation-based.
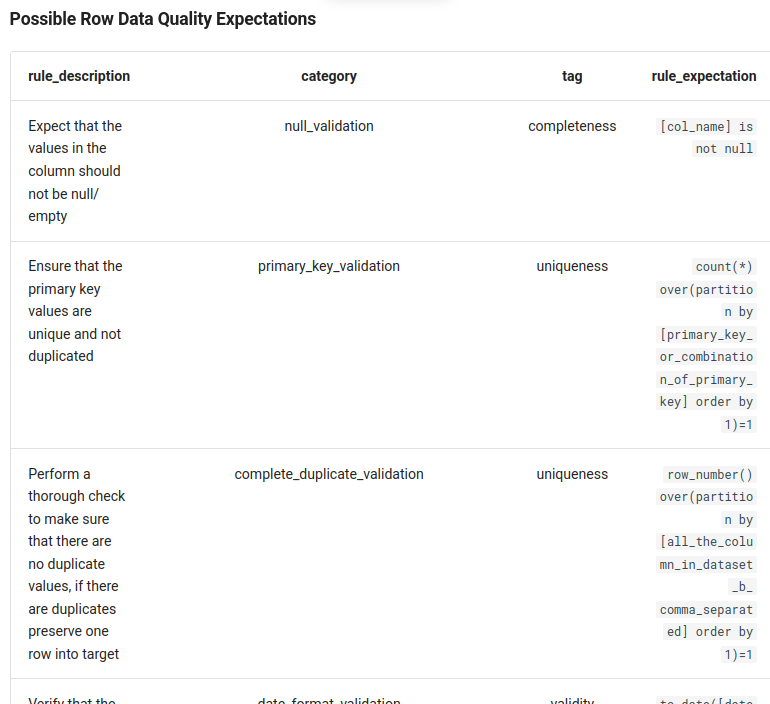
The row-based rules work at the row level and can check an expectation against one or multiple columns. The documentation provides pretty clear examples for them:
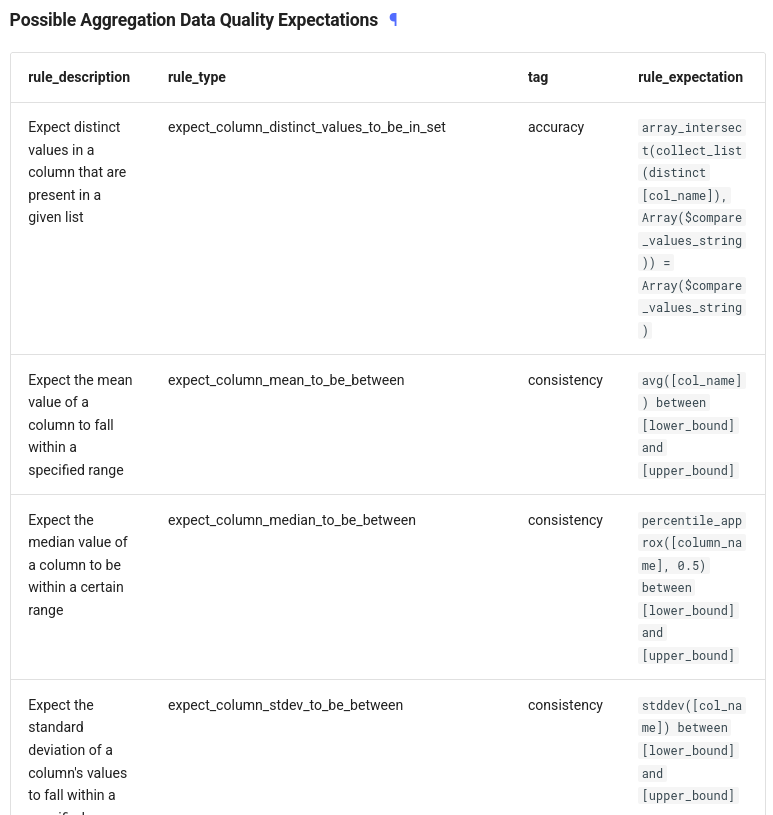
In addition to these simple rules, you can define the aggregation-based rules that, as the name indicates, rely on the aggregation expressions. Again, the documentation gives pretty good examples for them:
And finally, if you need a rule which is not covered by the two previous categories, you can define a query-based rule that simply runs a query on top of one or multiple tables, as per documentation:

In addition to the rule definition itself, each rule has other properties:
- the type of the rule that can be row_dq, agg_dq, or query_dq: rule_type
- source and final DataFrame validation flags: enable_for_source_dq_validation and enable_for_target_dq_validation
- behavior when the validation fails, can be ignore (do nothing), drop (remove the row), or fail (fail the validation job): action_if_failed
- notification configuration; if some rows are dropped from the dataset after validation and their number reaches error_drop_threshold, and the enable_error_drop_alert is enabled, a notification will be sent to the configured endpoint.
User account validation example
The goal of this part is to use a staging table to validate the dataset before overwriting the dataset currently exposed to the consumers by running similar data quality rules to the ones you saw in the aforementioned Delta Live Tables data quality blog post:
Let's begin with the data quality rules. Even though you can store them in a dedicated table or a file, we're going to keep this part simple and rely on the validation rules defined as an in-memory DataFrame:
# The full code is available on Github: https://github.com/bartosz25/spark-playground/tree/master/spark-expectations-demo
def get_rules_for_account() -> List[Row]:
rules_builder = DataQualityRulesBuilder('accounts')
return [
rules_builder.new_row_rule(column='id', failed_action='fail', expectation='id IS NOT NULL', name='id_defined'),
rules_builder.new_row_rule(column='creation_date', failed_action='fail', expectation='creation_date < NOW()', name='date_from_past'),
rules_builder.new_row_rule(column='email', failed_action='fail', expectation='email LIKE "%@%"', name='real_email'),
rules_builder.new_agg_rule(expectation='COUNT(id) > 4', failed_action='fail', name='correct_count'),
rules_builder.new_agg_rule(expectation='COUNT(DISTINCT(id)) > 3', failed_action='fail', name='correct_distinct_count'),
rules_builder.new_query_rule(expectation='''(SELECT COUNT(*) FROM accounts_staging a
LEFT ANTI JOIN account_types at ON at.name = a.account_type) = 0''', failed_action='fail', name='referential_check'),
rules_builder.new_query_rule(expectation='''(SELECT
SUM(rows_number_new) - SUM(rows_number_old) AS rows_difference
FROM (
SELECT COUNT(*) AS rows_number_new, 0 AS rows_number_old FROM accounts_staging
UNION ALL
SELECT 0 AS rows_number_new, COUNT(*) AS rows_number_old FROM accounts
)) >= 0
''', failed_action='fail', name='seasonality_check')
]
rules_dataframe = spark_session.createDataFrame(data=get_rules_for_account(), schema=get_rules_schema())
As you can see, there is validation on the individual rows, data integrity and seasonality checks, as well as an overall volume verification with an aggregation rule.
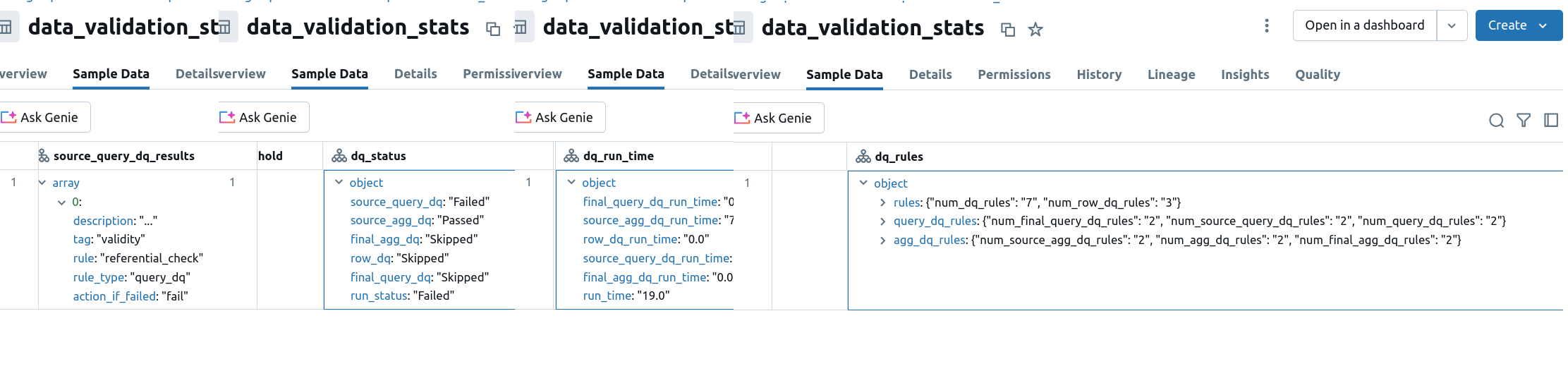
Next step consists on initializing the SparkExpectations within our Databricks job. The configuration references the rules DataFrame created before and a stats table that will be created by Spark Expectations to store some interesting details on the validation step:
delta_writer = WrappedDataFrameWriter().mode("overwrite").format("delta")
spark_expectations = SparkExpectations(
product_id=product_id_from_table_name('accounts'),
rules_df=rules_dataframe,
stats_table='data_validation_stats',
stats_table_writer=delta_writer,
target_and_error_table_writer=delta_writer,
stats_streaming_options={user_config.se_enable_streaming: False}
)
# disabled on purpose
user_conf = {
user_config.se_notifications_enable_email: False,
user_config.se_notifications_enable_slack: False,
}
After the SparkExpectations initialization, it's time to decorate the task that is going to run as part of Databricks Workflows:
def load_accounts_if_valid():
# setup part
@spark_expectations.with_expectations(
target_table='wfc_catalog.test_se.accounts',
write_to_table=True,
user_conf=user_conf,
target_table_view='accounts_staging'
)
def build_account_table():
spark_session.createDataFrame(data=[
Row(id=1, name='type a'), Row(id=2, name='type b'), Row(id=3, name='type c')
]).createOrReplaceTempView('account_types')
spark_session.createDataFrame(data=[
Row(id=1, name='account 1', email='email1@email', account_type='type a',
creation_date=datetime.datetime(2025, 1, 10, 14, 50), meta_dq_run_id=None, meta_dq_run_datetime=None),
Row(id=1, name='account 1', email='email1@email', account_type='type a',
creation_date=datetime.datetime(2025, 1, 10, 14, 50), meta_dq_run_id=None, meta_dq_run_datetime=None),
Row(id=2, name='account 2', email='email2@email', account_type='type b',
creation_date=datetime.datetime(2025, 1, 10, 11, 50), meta_dq_run_id=None, meta_dq_run_datetime=None),
Row(id=3, name='account 3', email='email3@email', account_type='type c',
creation_date=datetime.datetime(2025, 1, 10, 8, 50), meta_dq_run_id=None, meta_dq_run_datetime=None),
Row(id=4, name='account 4', email='email4@email', account_type='type XXXX',
creation_date=datetime.datetime(2025, 1, 9, 14, 50), meta_dq_run_id=None, meta_dq_run_datetime=None)
], schema='id INT, name STRING, email STRING, account_type STRING,
creation_date TIMESTAMP, meta_dq_run_id STRING,
meta_dq_run_datetime TIMESTAMP').createOrReplaceTempView('accounts_old')
df = spark_session.createDataFrame(data=[
Row(id=1, name='account 1', email='email1@email', account_type='type a',
creation_date=datetime.datetime(2025, 1, 10, 14, 50)),
Row(id=1, name='account 1', email='email1@email', account_type='type a',
creation_date=datetime.datetime(2025, 1, 10, 14, 50)),
Row(id=2, name='account 5', email='email2@email', account_type='type b',
creation_date=datetime.datetime(2025, 1, 10, 11, 50)),
Row(id=3, name='account 6', email='email3@email', account_type='type c',
creation_date=datetime.datetime(2025, 1, 10, 8, 50)),
Row(id=4, name='account 7', email='email3@email', account_type='type c',
creation_date=datetime.datetime(2050, 1, 10, 8, 50)),
Row(id=None, name='account None', email='email3@email', account_type='type c',
creation_date=datetime.datetime(2025, 1, 10, 8, 50)),
Row(id=111, name='account 111', email='email3@email', account_type='type XXXXXXXc',
creation_date=datetime.datetime(2025, 1, 10, 8, 50)),
], schema='id INT, name STRING, email STRING, account_type STRING, creation_date TIMESTAMP')
df.createOrReplaceTempView('accounts_staging')
return df
return build_account_table()
As you can see, the job defines some raw data breaking the data quality rules. As all the rules are configured with the fail flag, the validation job will fail and all failure details will be written to the stats table:

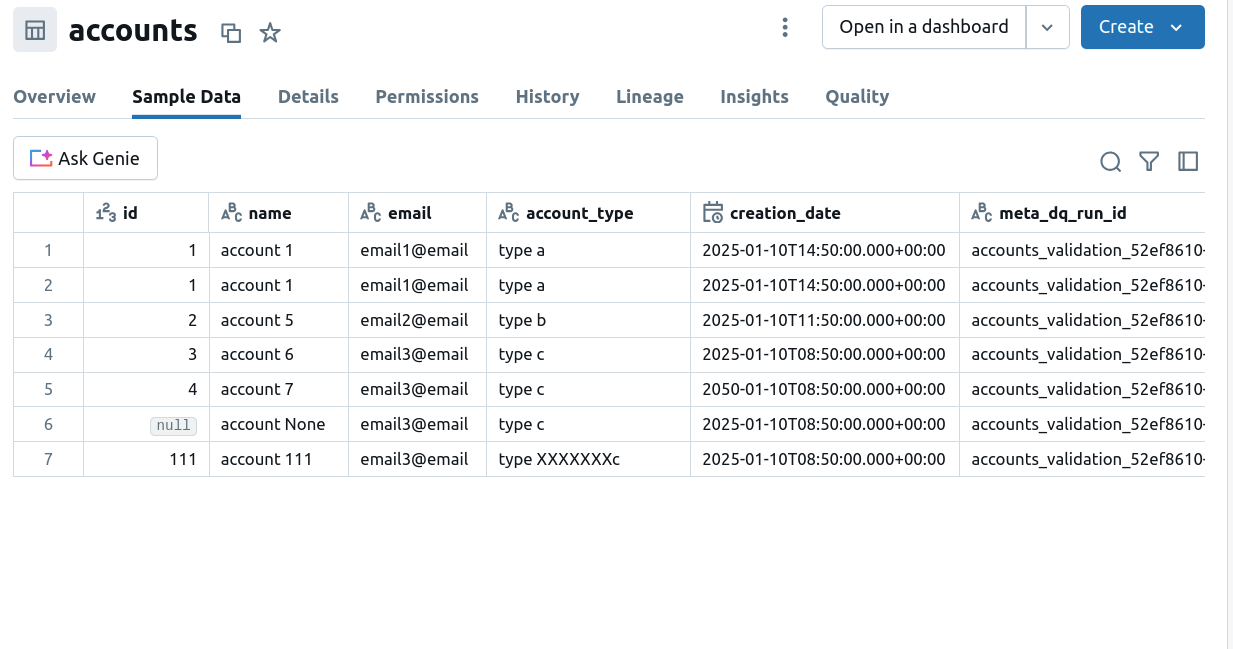
If instead of failing the data loading process you would like to see the data but annotated with the data quality issues, you can change the action_if_failed to 'ignore'. After executing the job, you should see the records correctly loaded to the output table with some extra columns referencing the data quality run:
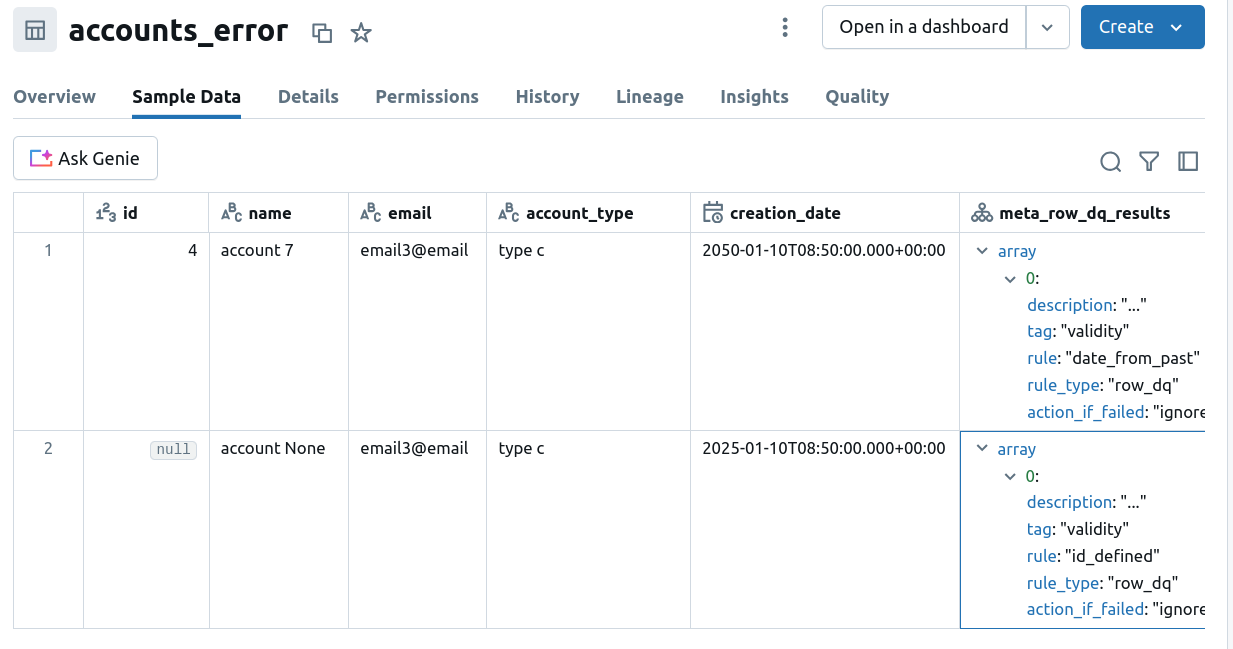
Besides, the rows not respecting the data quality rules will land in the errors table:
Finally, if we change the action_if_failed to 'drop', you'll still find the errors table with two invalid records. On another side, you will not see them in the output table since the configuration removes bad rows from the destination:
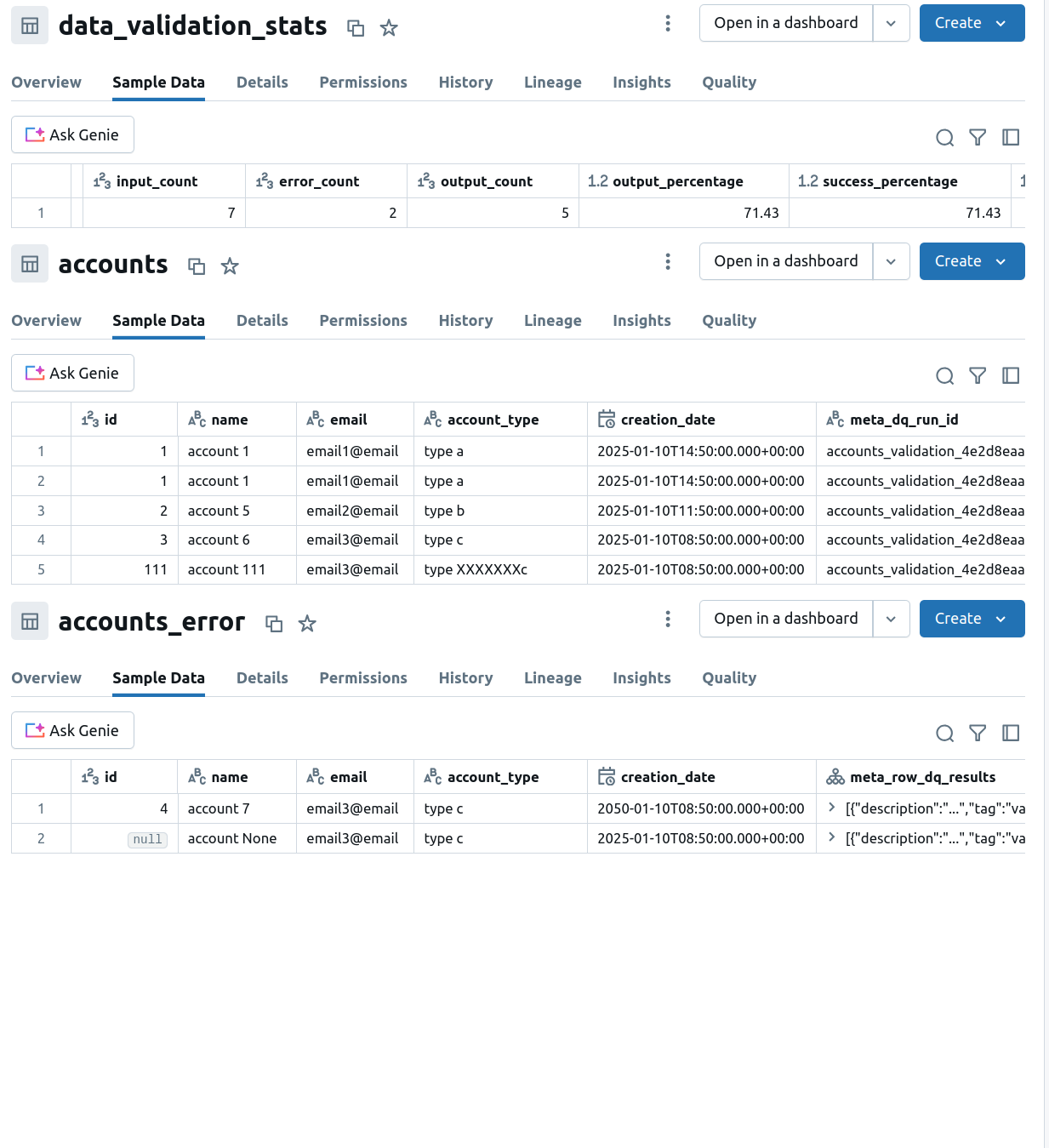
As you can notice, only the rows that failed the row data quality rules are excluded from the target table. It's not the case for the id 111 from our screenshot which breaks the referential integrity. However, as the check is defined as a query data quality rule, Spark Expectations doesn't know which is the particular row breaking it. Therefore, the library can't exclude it from the final output.
⚠ Databricks Serverless and Spark Expectations
Spark Expectations defines pyspark as required dependency. If you try to install the framework on Databricks Serverless, your runtime environment will try to install Open Source PySpark which is incompatible with the version running on Databricks. Consequently, your job won't start and will fail with the following exception instead:
run failed with error message Library installation failed: Library installation attempted on serverless compute and failed due to installing an incompatible package with the core packages. Error code: ERROR_CORE_PACKAGE_VERSION_CHANGE, error message: Python restart failed:
For that reason, you need to - at least for Spark Expectations 2.3.1 - use a cluster.
Pros and cons
| Pros | Cons |
|---|---|
| Flexibility that simplifies simple and complex rules definition, without requiring any extra structures to declare. | It can be tricky, especially the dependence between source, row, and final table validation rules. Some issues experience this, for example [BUG] query rule is skipped #44. Thankfully, the documentation gets better and better! |
| Open source, so if you are in trouble, you can reach out to the maintainers or directly see the code. | Even though the project is amazing from the end user perspective, it seems lacking some interest in the data community to collaborate on data quality best practices with a wider audience. |
| Native support for storing invalid records in a dead-letter table without you having to do any work. | Incompatibility with Databricks Serverless. The serverless environment simplifies a lot of work while setting Databricks jobs up. Unfortunately, Spark Expectations is not yet compatible with it. Knowing that you can use the clusters, it shouldn't be a blocker, though! |
| Native support for storing data validation results and data validation rules as tables which makes their exposition to the monitoring layer possible without a lot of effort. |
💬 What you might find in the next releases?
Ashok, if you could share a few words on the planned evolution of Spark Expectations like features, or things you are secretly working on at the moment?
1) We are working on an internal UI project to manage rules for SE, so even product, business and governance teams can collaborate and manage rules. We are envisioning Github as a backend to support CI/CD and ultimately engineers can test/validate in lower envs before moving to prod. I hope this goes good and ultimately becomes open source (secret :) )
2) Thinking of native support for YAML based rules configuration
3) Enhancing and optimizing SE for better streaming support
4) The community has been active over the last one and half years and improved SE to a great extent from its inception, with more community support - we can work on the long lasting important issues that will be beneficial for better reporting. Example: https://github.com/Nike-Inc/spark-expectations/issues/38
5) Lastly thanks to the community for contributing to new features and fixing many issues. Here is more to be done for improving the code base - https://github.com/Nike-Inc/spark-expectations/issues
I would be more than happy to tell you that Spark Expectations is the last data quality choice on Databricks. It's not the case because Databricks Labs released recently DQX that will be the topic of my next -and hopefully the last - blog post from the series!.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩