
Data quality is one of the key factors of a successful data project. Without a good quality, even the most advanced engineering or analytics work will not be trusted, therefore, not used. Unfortunately, data quality controls are very often considered as a work item to implement in the end, which sometimes translates to never.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This blog post starts a short series of articles about data quality on Databricks. The goal is to share with you different data quality implementation strategies. Hopefully, the articles will show that the data quality implementation can be included as a part of the business logic implementation process, either with native Databricks capability (Delta Live Tables), or some custom effort (Spark Expectations).
📌 Partners solutions
In this series I'm not going to delve into partner solutions. It's not because they're not reliable - I haven't tried them yet to be honest - but simply because I don't want to write next two months about data quality on Databricks ;) Hopefully, the topics that come next will be as exciting as the data quality. And do not forget, Apache Spark 4 is coming!
Delta Live Tables and data quality?
That might be your first question, how can a data ingestion framework be mentioned alongside the data quality? The answer is pretty simple; expectations. Whenever you create a Delta Live Table (DLT), you can decorate it with an expectation on the data quality. Depending on the language you use for DLT, the expectation is either a Python decorator (dlt.expect or a SQL constraint (CONSTRAINT ... EXPECT ... ).
🔔 Delta Lake constraints
If the CONSTRAINT keyword rings a bell, that's probably because of the same keyword used to define data controls on the Delta Lake columns. However, a DLT data quality expectation can apply to one or multiple columns which is not the case of the Delta Lake CONSTRAINT, reserved to the declaration column itself.
The simplest expectation applies to a column as it only validates the column value against the configured data quality rule. A simple nullability validator can be expressed like this:
import dlt # Databricks-specific
@dlt.table(name='blog_visits')
@dlt.expect("defined visit_id", "visit_id IS NOT NULL AND visit_id != ''")
The nice thing is that you can use SQL functions and expressions that many of you are familiar with. For example, if we wanted to validate visits to be defined only in the past we could do:
@dlt.expect("visit from the past", "visit_event_time < NOW()")
Another interesting example uses an if-else statement to perform a different validation depending on some condition. It can be useful to keep the validation alive in case of schema evolution. Below you can see a snippet that depending on the version_number field, checks for presence two different pairs of columns:
@dlt.expect("user id and session id defined", """
CASE
WHEN version_number = 'v1' THEN user_id != '' AND session_id != ''
WHEN version_number = 'v2' THEN user_id IS NOT NULL AND session_id IS NOT NULL
ELSE false
END
""")
Once you define the expectations, you can move on and configure the invalid records handling. Well, technically you have already done this and to understand why, let's move to the next section.
Expect, drop, or fail, thus the enforcement constraints
The data quality controls from our previous section are considered as warnings, i.e. the framework will keep the invalid records in the final table but it'll keep them in a separate table. Besides, DLT will generate statistics for the number of valid and invalid rows.
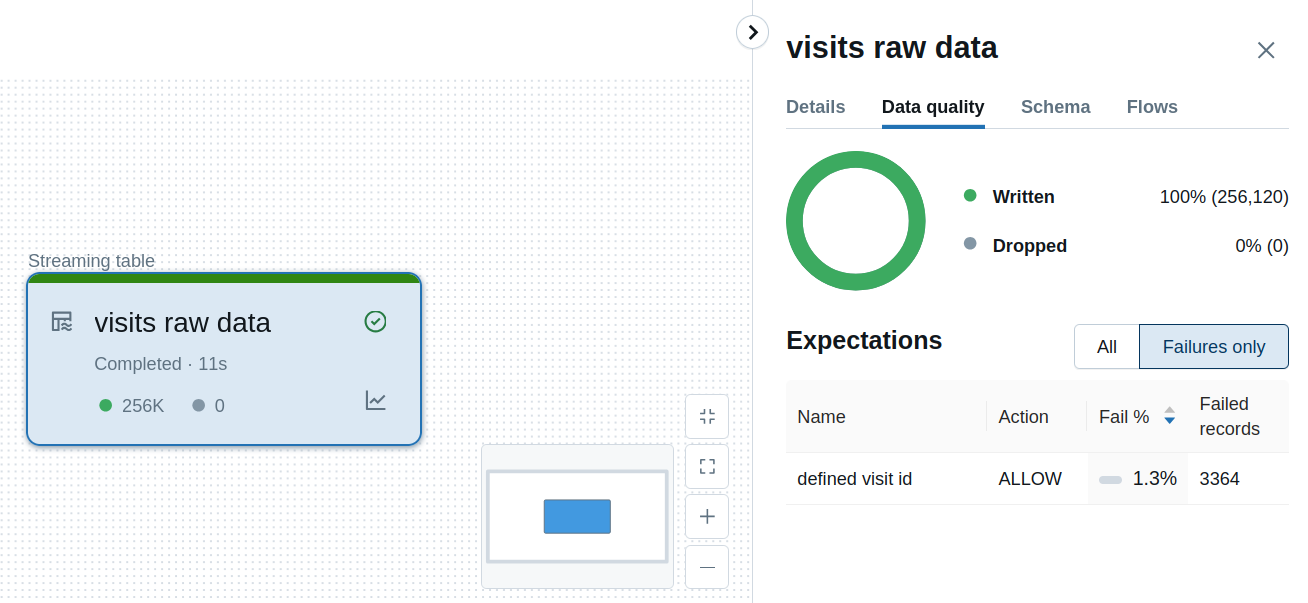
If your data quality rule cannot be a warning, you can decide to drop the invalid records from the final table. For that, you must replace the @dlt.expect by the @dlt.expect_or_drop decorator or CONSTRAINT ... EXPECT ... ON VIOLATION DROP ROW if you use SQL:
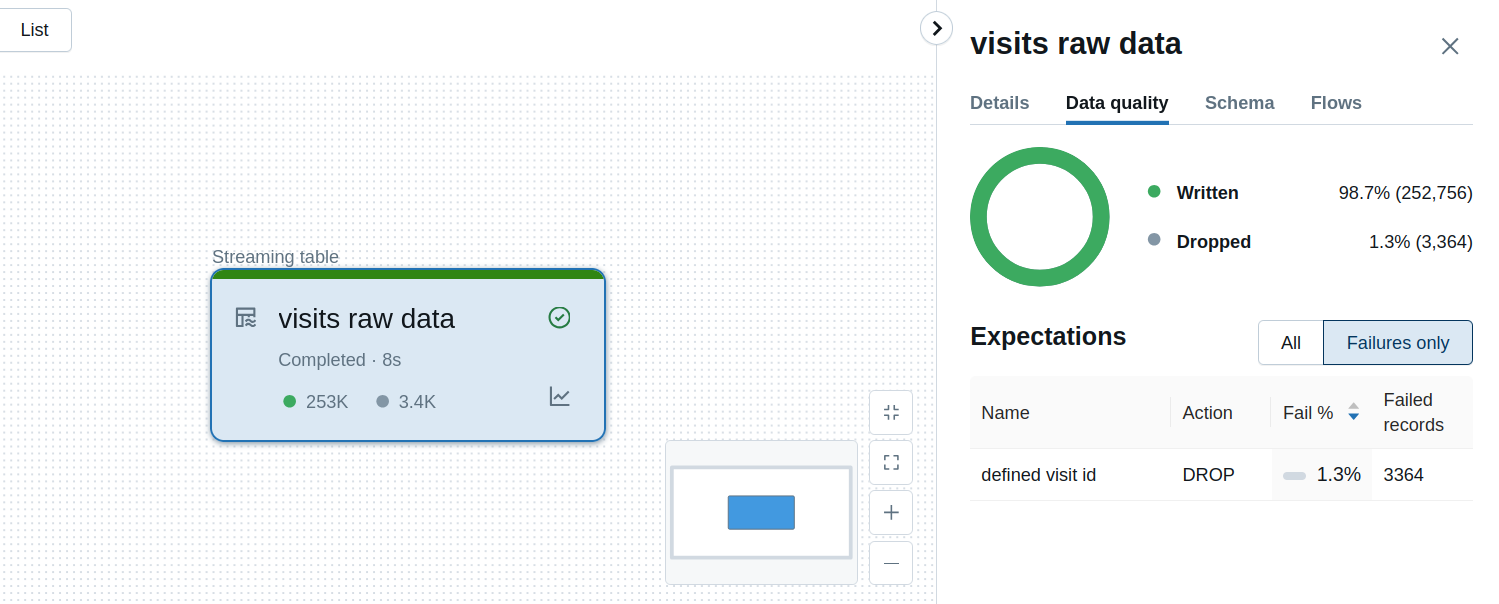
@dlt.expect_or_drop("defined visit id", "visit_id IS NOT NULL")
Below you can see what happens when you try to ingest some rows violating the defined visit id from the previous snippet:
Both warning and drop strategies are examples of a Defensive Programming approach where you build a system which is resilient against errors. However, it doesn't simplify understanding the issues and for sure, is less obvious to capture data problems than an Offensive Programming approach. In that alternative world you let your jobs fail as soon as possible, aka fail-fast approach. That's what the last DLT strategy does, it fails on invalid records. Again you need to use a different decorator which is @dlt.expect_or_fail, or ON VIOLATION FAIL clause on the constraint:
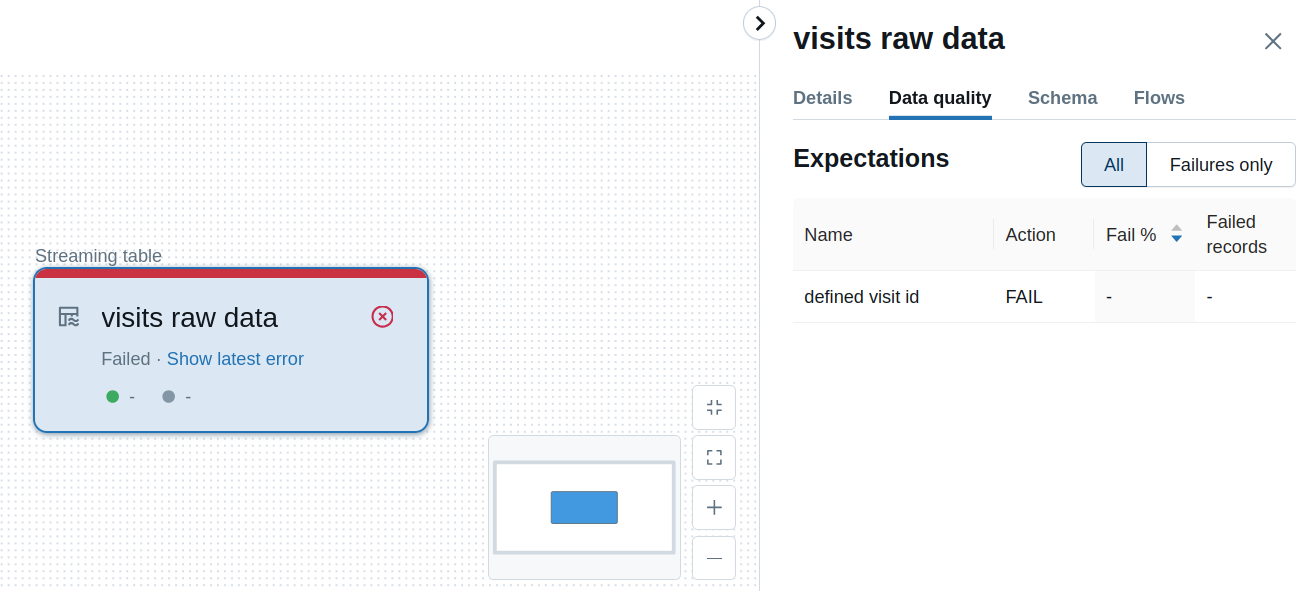
@dlt.expect_or_fail("defined visit id", "visit_id IS NOT NULL")
Consequently, any issue with the input data leads to the messages like this:
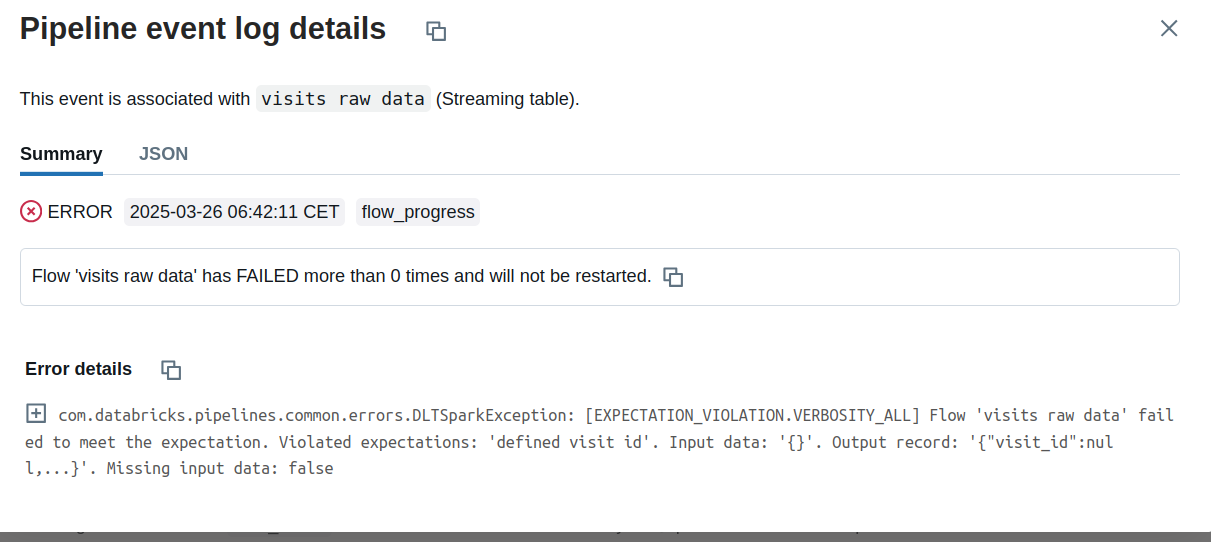
Additionally, when you click on the Show latest error link, you'll see the details of the failed record:
Complex rules
If you only need these simple column-based rules, you should be fine. Your code should remain relatively lightweight, particularly when you use grouping decorators such as @dlt.expect_all, @dlt.expect_all_or_drop, or @dlt.expect_all_or_fail. For example, a validation case for our visits table could be summarized as:
expectations = {
'defined visit id': 'visit_id IS NOT NULL',
'defined device name': 'device_name IS NOT NULL',
'valid visit country': 'visit_country IN ("PL", "FR", "DE")'
}
@dlt.table()
@dlt.expect_all_or_fail(expectations)
If you check this on Databricks UI, you should also be pretty satisfied with the explicitness:
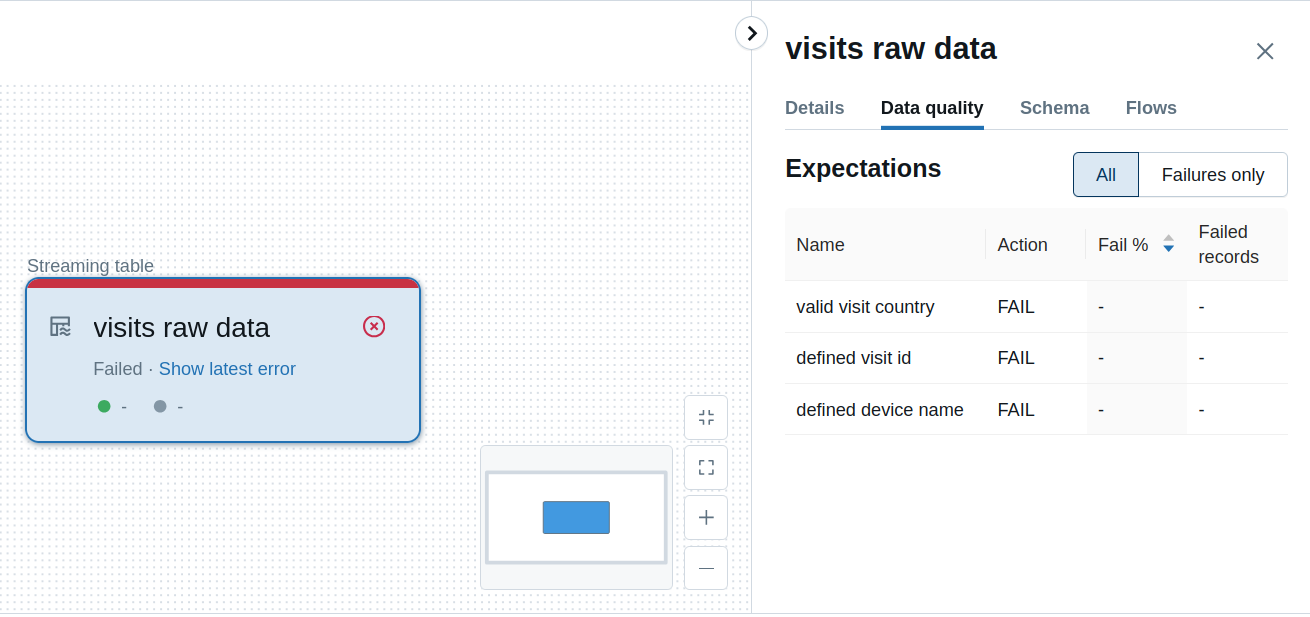
Unfortunately, the things may become complex if you need to use multiple complex data quality rules, such as the ones to verify data integrity by joining two tables, or comparing seasonality between incrementally loaded datasets.
Expects are just WHERE statements
In fact, the expectations are statements dynamically added to the Delta Live table. To see this in action, you can try to add an invalid expectation rule, such as counting the number of rows in the table. Databricks should return an AnalysisException, such as below for @dlt.expect("valid count for visited pages", "COUNT(visit_page) > 1"):
org.apache.spark.sql.catalyst.ExtendedAnalysisException: [INVALID_WHERE_CONDITION] The WHERE condition "(NOT ((((((count(visit_id) > 1) AND ....)" contains invalid expressions: count(visit_id). # Rewrite the query to avoid window functions, aggregate functions, and generator functions in the WHERE clause.; # Filter NOT ((((((count(visit_id#1376) > cast(1 as bigint)) AND (length(login#1378) >= 2)) AND (NOT (name#1372 = login#1375) AND NOT (login#1375 = email#1376))) AND (date_registered#1373 < now())) AND AND isnotnull(user_id#1370)) # +- Distinct # ... # +- Aggregate [col1#2088, col2#2275, col3#2091, # ....
If you need to apply one of these complex rules, you'll have to create temporary tables or views, and decorate them with the expectations. Below you can find an example for the integrity and seasonality checks:
@dlt.table(name=visits_for_referential_integrity', temporary=True)
@dlt.expect_or_fail("at least half of defined visits", "defined_visits >= 50")
def visits_for_referential_integrity():
return spark.sql(f"""SELECT
(referenced_visits * 100)/all_visits AS defined_visits
FROM (
SELECT COUNT(v.id) AS all_visits, COUNT(ref.visit_id) AS referenced_visits
FROM visits_staging v
LEFT JOIN visits_references ref ON v.id = ref.visit_id
)
""")
@dlt.table(name='visits_for_seasonality_check', temporary=True)
@dlt.expect_or_fail("at least that many visits as before", "rows_difference >= 0")
def visits_for_seasonality_check():
return spark.sql(f"""SELECT
SUM(rows_number_new) - SUM(rows_number_old) AS rows_difference
FROM (
SELECT COUNT(*) AS rows_number_new, 0 AS rows_number_old FROM visits_staging
UNION ALL
SELECT 0 AS rows_number_new, COUNT(*) AS rows_number_old FROM visits
)
""")
expectations = {
'defined visit id': 'visit_id IS NOT NULL',
'defined device name': 'device_name IS NOT NULL',
'valid visit country': 'visit_country IN ("PL", "FR", "DE")'
}
@dlt.table()
@dlt.expect_all_or_fail(expectations)
def visits_bronze():
spark.sql('SELECT COUNT(*) FROM live.visits_for_referential_integrity').show()
spark.sql('SELECT COUNT(*) FROM live.visits_for_seasonality_check').show()
return spark.readStream.table("visits_staging")
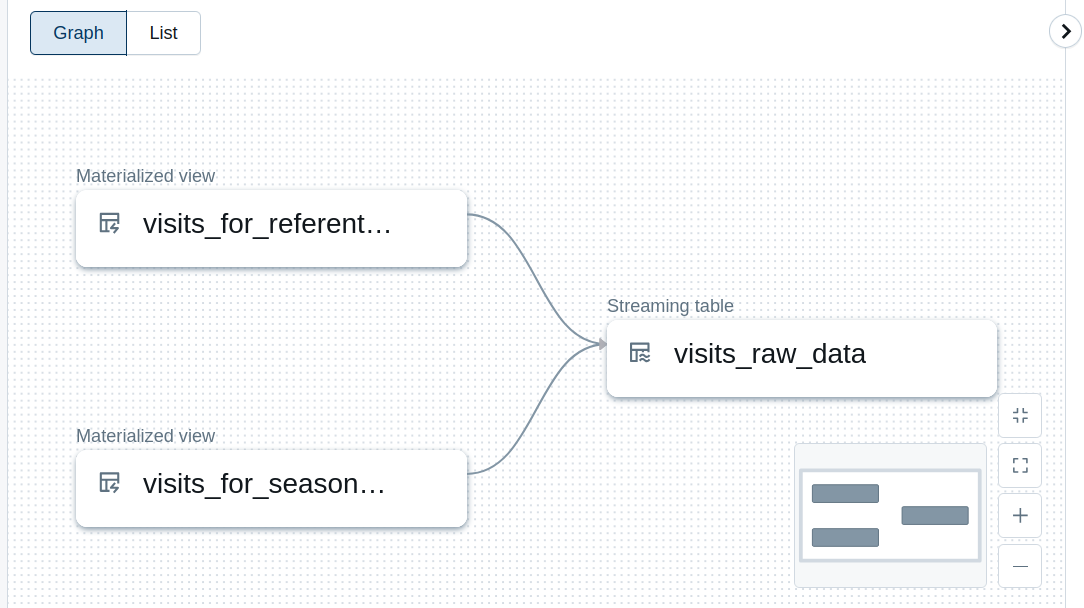
Even though the code doesn't look scary, one of serious implications is visible in the UI where our so-far simple and linear flow, transforms into more advanced workflow with branches:
And a failure in our example might look like that:
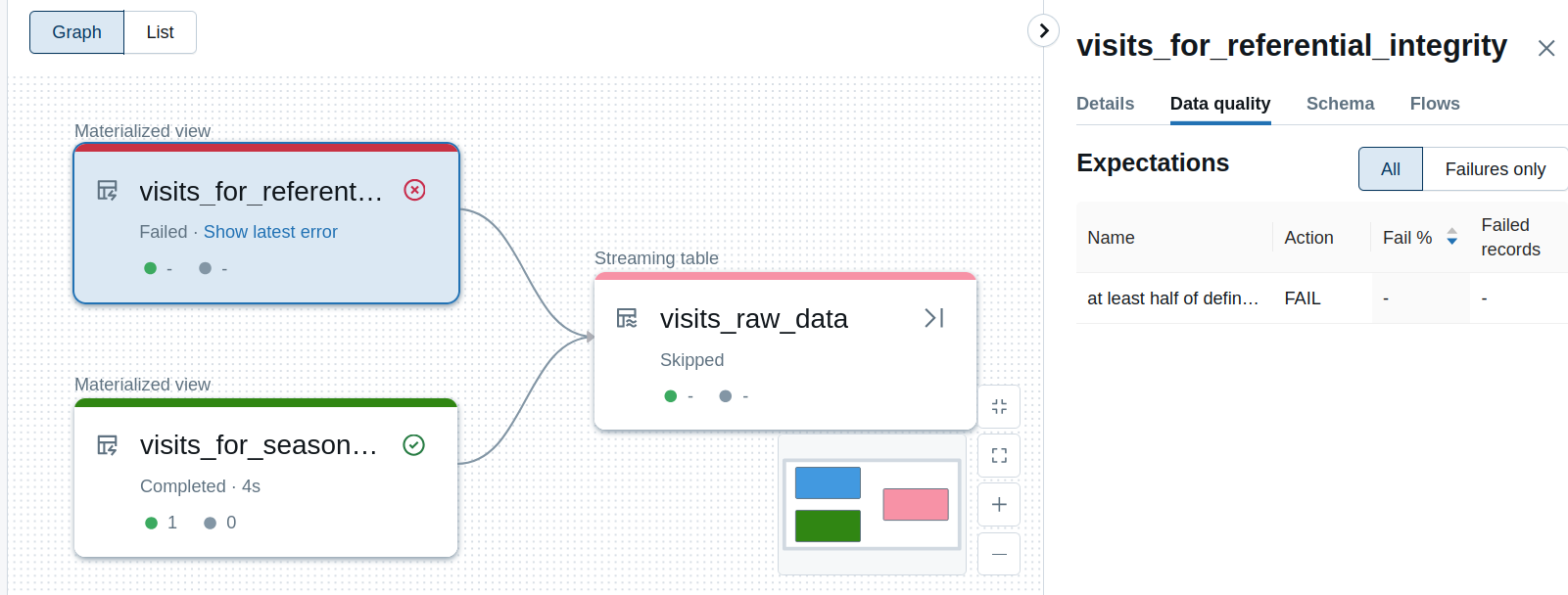
You must remember to reference the tables. In the snippet, I did them by calling the counts which, by definition, should be relatively quick operations. If you don't link the materialized views to the final table, your workflow will be composed of three separate jobs and any failure will not prevent refreshing the final visits raw table. Below you can see the separated workflow:
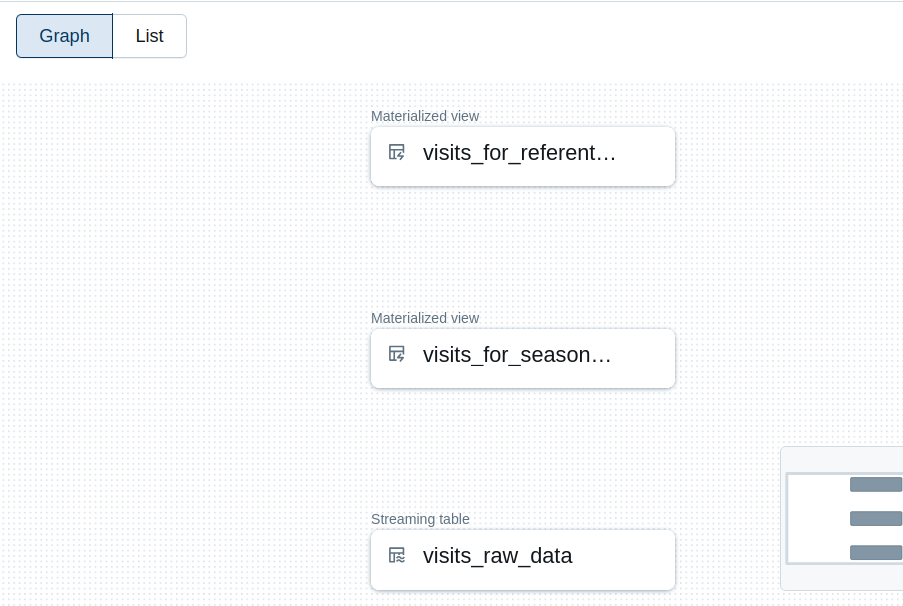
...and the result after data quality evaluation:

It's by the way a good moment to try to summarize the Delta Live Tables expectations for implementing data quality rules on Databricks.
Pros vs. cons
| Pros | Cons |
|---|---|
| Easy definition for simple rules. | Definition remains relatively easy for advanced rules but the execution graph can become very complex. The workflow for advanced rules can be simplified with temporary tables as they're removed after the run but you'll still see those tables in the UI. |
| Native support for warning, drop, and fail-fast modes. | No possibility to write invalid records to a separate storage for further analysis. It can be mitigated by writing the records in the warning mode to a table, and later dispatching the rows without the warning to the final destination, and saving the rows with warning to a different place. |
| Built-in integration to Databricks UI that simplifies day-to-day usage. | API support limited to the operations supported in DLT. If you try to run an unsupported operation, you'll get the error:
com.databricks.pipelines.common.errors.DLTSparkException:
[UNSUPPORTED_SPARK_SQL_COMMAND] 'TruncateTable' is not supported in
spark.sql("...") API in DLT Python. Supported command: `SELECT`,
`DESCRIBE`, `SHOW TABLES`, `SHOW TBLPROPERTIES`, `SHOW NAMESPACES`,
`SHOW COLUMNS IN`, `SHOW FUNCTIONS`, `SHOW VIEWS`, `SHOW CATALOGS`, `SHOW
CREATE TABLE`, `USE SCHEMA`, `USE CATALOG`.
at com.databricks.pipelines.api.GraphErrors$.unsupportedSparkSqlCommand(GraphErrors.scala:66)
at com.databricks.pipelines.SQLPipeline$.sql(SQLPipeline.scala:473)
|
If you use Delta Live Tables for data integration, there are big chances you'll also use the expectations framework for data quality assertions. But, if you consider some alternative execution modes, in the next blog posts of the series you'll find two complementary data quality examples.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩