
If you have been working with Apache Airflow already, you certainly met XComs at some point. You know, these variables that you can "exchange" between tasks within the same DAG. If after switching to Databricks Workflows for data orchestration you're wondering how to do the same, there is good news. Databricks supports this exchange capability natively with Task values.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Using the feature is relatively simple as you just need to leverage the dbutils.jobs.taskValues. To define a task value, you call a set function while to retrieve its value, you use the get. The next snippet shows this write/read interaction:
# task = read_file_to_process dbutils.jobs.taskValues.set(key="file_to_process", value="new_file1.txt") # task = process_new_file dbutils.jobs.taskValues.get(taskKey="read_file_to_process" key="file_to_process")
So defined task values are later exposed from the Workflows UI, as you can see in the screenshots below:
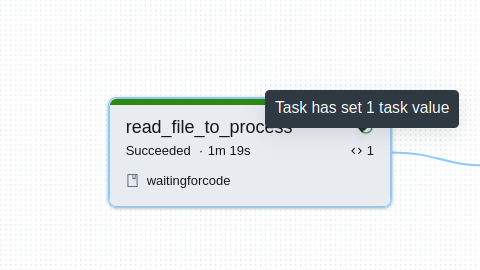
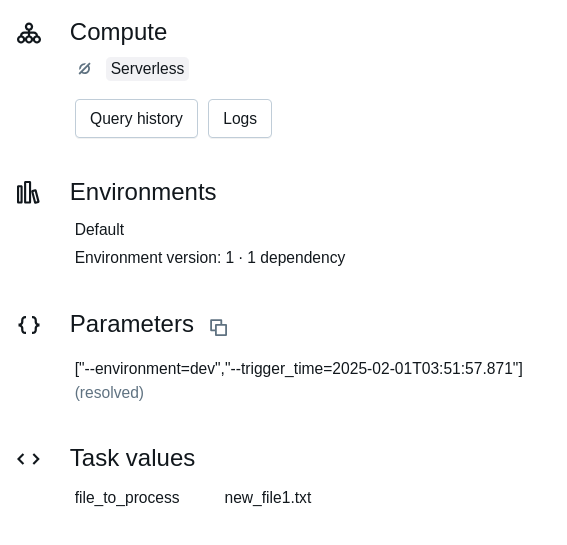
Dynamic value references
However, the dbutils-based access is not the single way of reading the task values. Besides you can use another great feature of Databricks Jobs which is the dynamic value references. Dynamic value references are like Jinja macros you could use in Apache Airflow. Put differently, they provide a collection of variables available to the tasks. By default, there are many references available that you can leverage to implement idempotent data processing logic, or simply to provide some additional metadata context to the generated tables.
Among these native values you'll find {{ job.trigger.time }} for the trigger time, {{ job.id }} for the unique job id, or yet {{ job.run_id }} for unique job execution (aka run) id.
In addition to these native reference values, you can also access task values with the same, Jinja-like syntax. The retrieval consists of using the tasks domain, followed by the task name and values attribute. For example, to access a task called abc with a task value called z, you will need to write {{ tasks.abc.values.z }}.
You can later pass retrieved task values as parameters to your wheel-based jobs, or to other tasks, such as an if-else task. If we keep our initial example, we could write a logic that will define a dedicated path to follow regarding the file name, e.g.:
- task_key: evaluate_file_to_process
depends_on:
- task_key: read_file_to_process
condition_task:
op: EQUAL_TO
left: "{{ tasks.read_file_to_process.values.file_to_process }}"
right: "_SUCCESS"
- task_key: refresh_table
depends_on:
- task_key: evaluate_file_to_process
outcome: "true"
The snippet above will run the refresh_table only when the detected file to process retrieved from {{ tasks.read_file_to_process.values.file_to_process }} to is equal to _SUCCESS.
Challenges and limits
The first challenge you may face is the task value integration to a wheel job because of the missing dbutils package that will cause ModuleNotFoundError: No module named 'dbutils' error. A workaround is to wrap the dbutils from a method resolved at runtime, such as:
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
get_dbutils(spark_session).jobs.taskValues.set(key="file_to_process", value="new_file1.txt")
The second limitation is size. A task value cannot be bigger than 48 KiB. And knowing how XComs were abused in the early days of Apache Airflow, the hard limit is a good thing. At that time, XComs were only stored in Apache Airflow's relational database metastore and it was not uncommon people used them to exchange the datasets, causing an additional and serious load on the database. At least, task values limited to 48 KiB addresses this potential misuse from the beginning.
Apache Airflow XCom backend
If you don't want to load your database with XCom variables, you can configure another storage backend, such as an object store, with xcom_backend configuration. You'll find more details in the documentation.
Another limitation comes from dbutils itself which is a Python library not available for JVM workloads you can also execute on Databricks. Thankfully, the dynamic value references covered before mitigate this issue very easily.
Exchanging values between tasks is a pretty common feature in the data orchestration world. It enables work decoupling, fine-tuning backfilling boundaries, or yet implementing Data flow design patterns such as the Fan-out ones (I'm covering them more in my Data Engineering Design Patterns book). Databricks is not an exception and implements this capability with task values covered in this blog post.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Apache Airflow XCom in Databricks with task values here:
Related blog posts:
- Ruff and Declarative Automation Bundles
- Managing Unity Catalog resources on Databricks
- Hints on Databricks