
Dealing with numbers may be easy and challenging at the same time. When you operate on integers, you can encounter integers overflow. When you deal with floating-point types, which will be the topic of this blog post, you can encounter rounding issues.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
I'm working these days more or less exclusively with Databricks. For that reason the blog post targets this specific platform. However, I believe you can apply the knowledge shared here on other data platforms running Apache Spark, or even other frameworks.
Doubles, floats, decimals,...
As a refresher let's recall some working example that shows how the compute results for the floating-point types can be different, depending on what type we chose. Below you can see a simple multiplication in Python that will generate a different result for double and decimal types:
from decimal import Decimal
number_1 = 1.49
number_2 = 2.33
result = number_1 * number_2
assert result == 3.4717000000000002
number_1 = Decimal('1.49')
number_2 = Decimal('2.33')
result = number_1 * number_2
assert result == Decimal("3.4717")
Even though both snippets show a similar value, you can see the double type prints additional "0002" in the end. We call this a floating-point inaccuracy. You are seeing the tiny, unavoidable rounding error that occurs when computers store and calculate decimal numbers using the standard binary floating-point system like the double type from the example.
Technically speaking, double uses a binary (base 2) system while decimal storage uses decimal (base 10) system. What does it mean? The Python documentation for floating-point arithmetics:
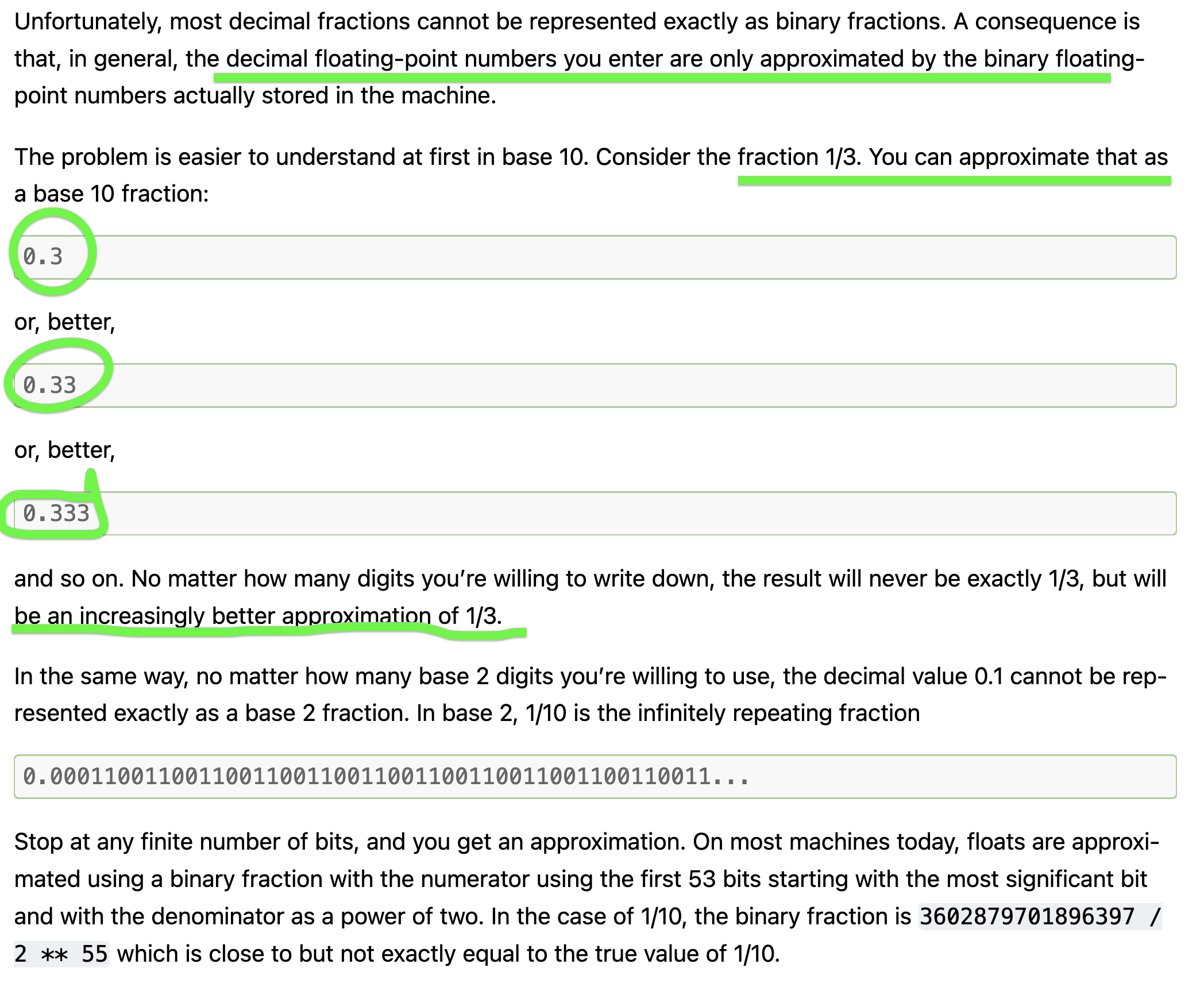
Let me use Python yet again to quote a great explanation for the decimal types:

Use case refresher
Thanks to their exact representation decimals are then a good choice for everything requiring...the exact representation. In this category you will certainly find domains like finance, currency, tax calculations, ... On the opposite side where the exact results are not required, you will use doubles.
I know, it's imprecise and you should always adapt the data type to your problem and instead of targeting a specific domain, you should think of accepting the trade-off of faster computation (doubles run on the hardware level) versus slower computation (decimals are on the software part) but exact values.
Manipulating decimals
Now comes Databricks and Unity Catalog. Again, I won't give you the answer if your column should be a double or decimal because it boils down to your requirements. The single point I will share with you is to explain the difference between double and decimal calculations.
Let's create a new notebook that is going to run this PySpark code:
from decimal import Decimal
from pyspark.sql import functions as F
numbers = [
{'number_1': 1.49, 'number_2': 2.33,
'number_1_dec': Decimal('1.49'), 'number_2_dec': Decimal('2.33')}
]
numbers_df = spark.createDataFrame(numbers, 'number_1 DOUBLE, number_2 DOUBLE, number_1_dec DECIMAL(5, 3), number_2_dec DECIMAL(5, 3)')
numbers_df_multiplied = (numbers_df.withColumn('multiplication_double', F.col('number_1') * F.col('number_2'))
.withColumn('multiplication_dec', F.col('number_1_dec') * F.col('number_2_dec')))
numbers_df_multiplied.printSchema()
display(numbers_df_multiplied)
Now you can hit the run button and check the displayed table:
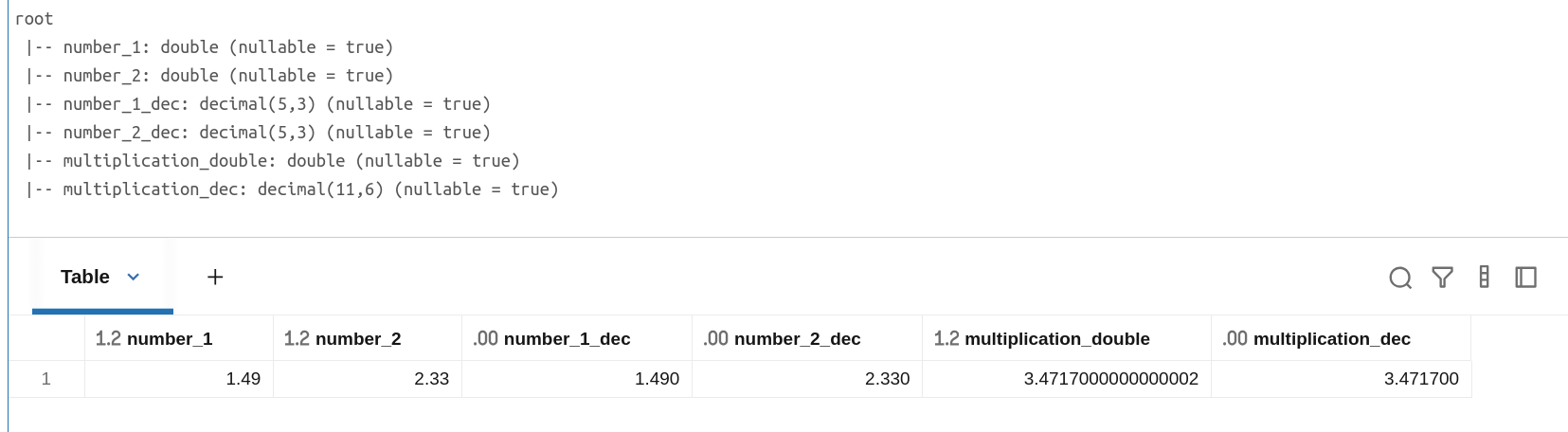
The first thing won't surprise you, the results are still different between the double and decimal multiplications. But I bet there is one thing that puzzles you, the DECIMAL(11,6) type in the output DataFrame. If your intuition tells you it's the sum of both input columns, you're almost right. To find the exact answer, we need to delve into Apache Spark code.
Arithmetic operations are managed by classes implementing the org.apache.spark.sql.catalyst.expressions.BinaryArithmetic trait. One of the required methods to implement is this one:
private lazy val internalDataType: DataType = (left.dataType, right.dataType) match {
case (DecimalType.Fixed(p1, s1), DecimalType.Fixed(p2, s2)) =>
resultDecimalType(p1, s1, p2, s2)
case _ => left.dataType
}
protected def resultDecimalType(p1: Int, s1: Int, p2: Int, s2: Int): DecimalType = {
throw SparkException.internalError(
s"${getClass.getSimpleName} must override `resultDecimalType`.")
}
As you can notice, whenever our math operation returns a decimal, we delegate the generation of the exact type to this resultDecimalType method that takes, respectively, precision and scale of the first column, and precision and scale of the second column. In our case, the code calls this function as:
resultDecimalType(5, 3, 5, 3)
Since the involved operation is a multiplication, we have to check the Multiply implementation:
override def resultDecimalType(p1: Int, s1: Int, p2: Int, s2: Int): DecimalType = {
val resultScale = s1 + s2
val resultPrecision = p1 + p2 + 1
if (allowPrecisionLoss) {
DecimalType.adjustPrecisionScale(resultPrecision, resultScale)
} else {
DecimalType.bounded(resultPrecision, resultScale)
}
}
If you substitute the p1, s1, p2, and s2 by the exact numbers you'll quickly understand why the new type is not a DECIMAL(5, 3) but a DECIMAL(11, 6) (scale = 3 +3; precision = 5 + 5 + 1).
Precision loss
Even though these decimal-based operations may sound familiar, you should be aware they can lead to some issues related to these precision changes. For those reasons Apache Spark 2.3.1 brought a configuration property called spark.sql.decimalOperations.allowPrecisionLoss that according to the Scaladoc is responsible for rounding the values on your behalf if they cannot be represented exactly:
val DECIMAL_OPERATIONS_ALLOW_PREC_LOSS =
buildConf("spark.sql.decimalOperations.allowPrecisionLoss")
.internal()
.doc("When true (default), establishing the result type of an arithmetic operation " +
"happens according to Hive behavior and SQL ANSI 2011 specification, i.e. rounding the " +
"decimal part of the result if an exact representation is not possible. Otherwise, NULL " +
"is returned in those cases, as previously.")
.version("2.3.1")
.booleanConf
.createWithDefault(true)
This property is later read by the arithmetic operations to know whether they should adjust the scale or not. Let's understand it better with another example:
numbers = [
{'number_1': 1.49, 'number_2': 2.33, 'number_1_dec': Decimal('1.49'), 'number_2_dec': Decimal('2.33')}
]
numbers_df = spark.createDataFrame(numbers,
'number_1 DOUBLE, number_2 DOUBLE, number_1_dec DECIMAL(38, 18), number_2_dec DECIMAL(38, 18)')
numbers_df_multiplied = (numbers_df.withColumn('multiplication_double', F.col('number_1') * F.col('number_2'))
.withColumn('multiplication_dec', F.col('number_1_dec') * F.col('number_2_dec')))
numbers_df_multiplied.printSchema()
display(numbers_df_multiplied)
If you rerun this code with the precision loss enabled, you will notice the difference in the output type that will be:
# Precision loss disabled root |-- number_1: double (nullable = true) |-- number_2: double (nullable = true) |-- number_1_dec: decimal(38,18) (nullable = true) |-- number_2_dec: decimal(38,18) (nullable = true) |-- multiplication_double: double (nullable = true) |-- multiplication_dec: decimal(38,36) (nullable = true) # Precision loss enabled root |-- number_1: double (nullable = true) |-- number_2: double (nullable = true) |-- number_1_dec: decimal(38,18) (nullable = true) |-- number_2_dec: decimal(38,18) (nullable = true) |-- multiplication_double: double (nullable = true) |-- multiplication_dec: decimal(38,6) (nullable = true)
Please note the property can be changed with local SparkSession. If you try to run it on Databricks Serverless, you'll get this error:

Bug fix in Apache Spark 4.1.0
Prior to Apache Spark 4.1.0 the configuration could be changed within the same SparkSession leading to inconsistent behavior. Stefan Kandic addressed it in SPARK-53968 by replacing the mutable configuration by an immutable NumericEvalContext class.
I know, the blog post doesn't answer your question of using doubles or decimals directly but it should give you all the necessary information to judge when one is better over another on your own! I hope, it also answers the questions why operations on decimals return bigger decimal types. In fact, that was triggered my investigation ;)
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩