
For over two years now you can leverage file triggers in Databricks Jobs to start processing as soon as a new file gets written to your storage. The feature looks amazing but hides some implementation challenges that we're going to see in this blog post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The File arrival trigger was initially released in February 2023 but it became Generally Available only one year later. Prior to this feature, if you needed a real event-driven trigger logic, you had to leverage the capabilities of your cloud provider and combine them with the Databricks Jobs API, like shown in the schema below:
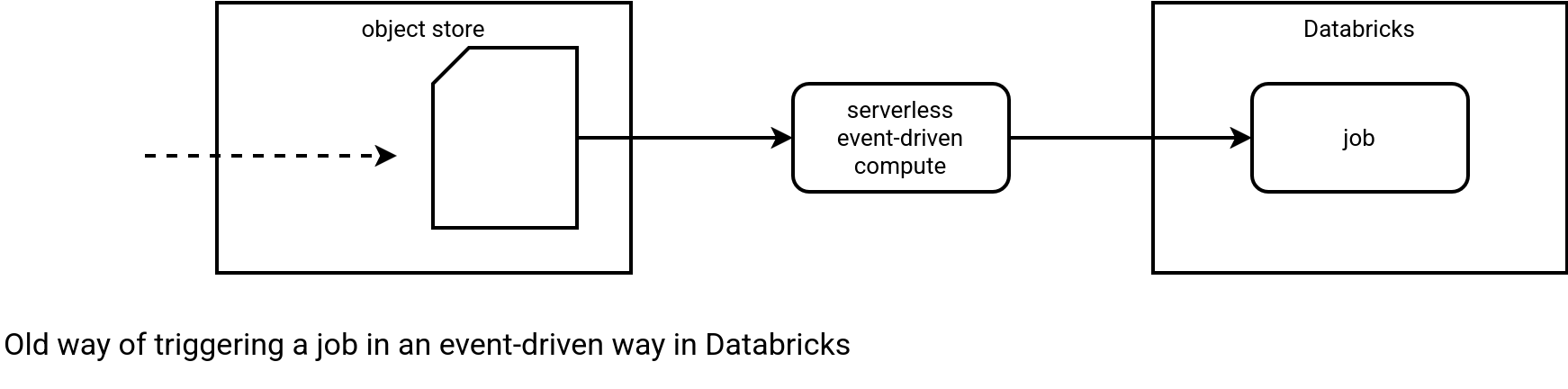
This way of working involves many challenges, including various places to monitor (cloud-native trigger, Databricks-specific job), access token sharing for the Service Principal, implementation split (different SDKs).... All this is no more with the Databricks file trigger feature that starts a Job after detecting a new file in the monitored location. It doesn't require any 3rd party, the triggering and tracking mechanism are natively available in Databricks. I could have stopped this blog post here but it might not be good for SEO, so let's continue and see some configuration and tricky points, hopefully to be better referenced ;)
Configuration
Let's begin our File trigger analysis by a simple Databricks Asset Bundles (DAB) snippet that starts a Workflow whenever a new file arrives to a volume in Unity Catalog:
resources:
jobs:
ingest_to_bronze_layer:
name: bronze_layer_ingestion_job
trigger:
file_arrival:
url: '/Volumes/visits/'
wait_after_last_change_seconds: 300
min_time_between_triggers_seconds: 120
The trigger part perfectly shows the capabilities of the File trigger, alongside its specificities. If you take a look at the Documentation, you'll see that:

If we translate these points to our snippet, it gives:
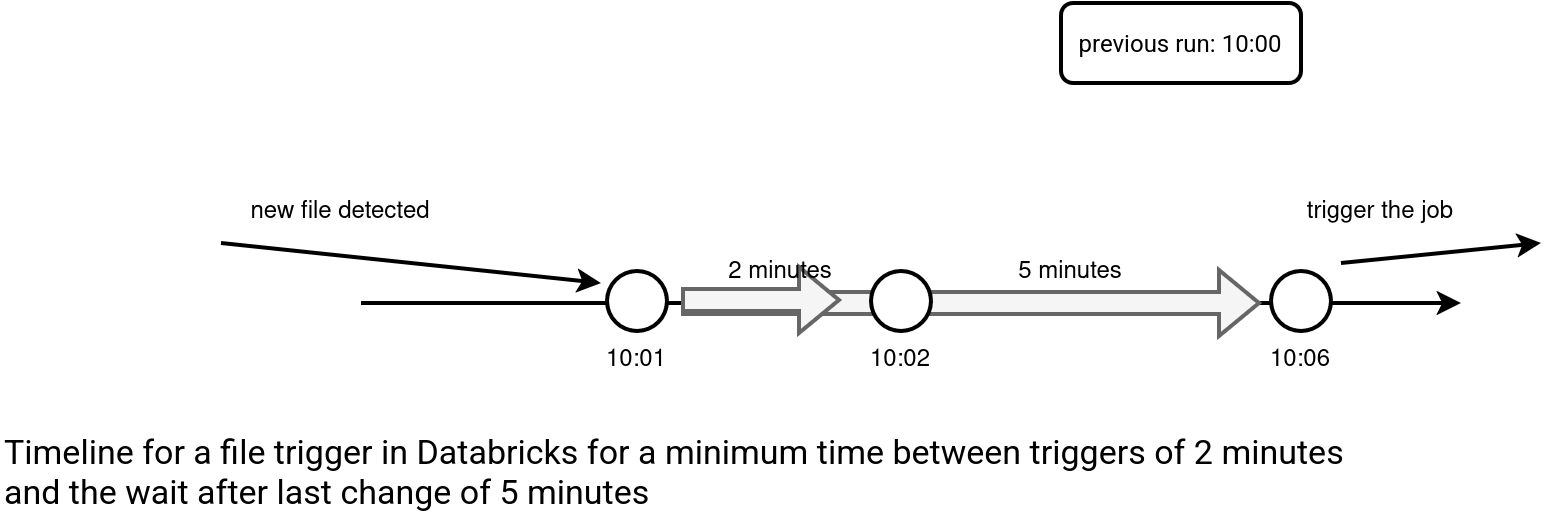
- Minimum time between triggers in seconds: Your next workflow will not start just after the currently running one, even if there are new files to integrate. Instead, it'll start 2 minutes later.
- Wait after last change in seconds: The Workflow execution will be delayed by 5 minutes. An important thing to keep in mind is that "another file arrival in this period resets the timer". Put differently, if you've continuously arriving files, your Workflow will never start as its execution will be continuously delayed. For that reason this setting should be used only to optimize the batch of processed files. It means that if you have a data producer generating 10 different files once a day but doesn't guarantee writing them at the same time, the wait after the last change setting will help you trigger the Workflow once all the files are there. Of course, it doesn't guarantee completeness but that's one of the tricky points we're going to discover in the next section.
Tricky points
The first thing to keep in mind is that the File trigger is unaware of what's going on with the data. For example, if you expect a specific set of files to be present before triggering a processing, you need to implement a validation task in the Job, so that you get a workflow similar to:
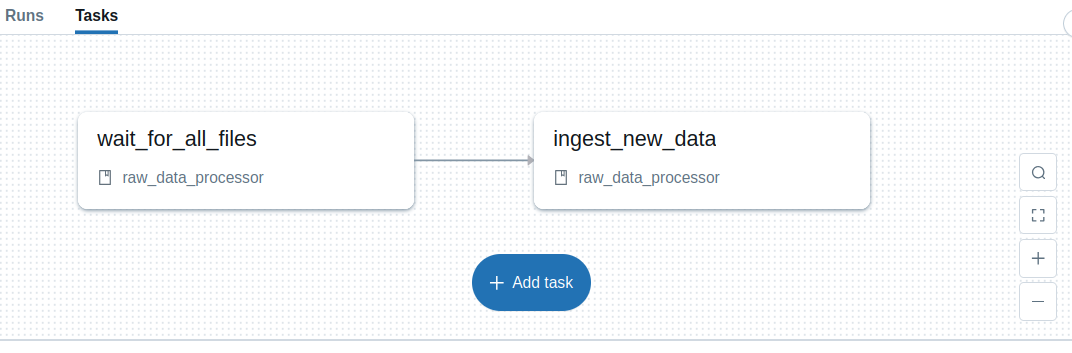
Occasionally, the waiting task could fail if, despite delaying the execution with the options presented in the previous chapter, there is no all required files. Please notice both tasks could be merged into the single one but in that case, you wouldn't know what was the reason of the failure (processing logic or missing files). Having them splitted, makes the errors investigation easier, and the bugs more obvious.
📝 The Readiness marker pattern
The validation task is an example of the Readiness marker pattern presented in Chapter 3 of Data Engineering Design Patterns.
Another challenging part is file name retrieval. At the moment it's not possible to get the file name natively, for example via Job parameters. This behavior is different from the behavior you could experience for serverless functions (AWS Lambda, Azure Functions, GCP Cloud Functions) where each event notification brings some extra content, including the name of the objects triggering the execution. With the File trigger, you need a different solution that will:
- Either leverage Apache Spark Structured Streaming checkpointing capabilities to get new data to process and eventually retrieve file names with the input_file_name() function or with the selectExpr('_metadata.file_path AS processed_file'):
input_files = spark.readStream.text('/Volumes/visits/raw') query = input_files.writeStream.trigger(availableNow=True).option('checkpointLocation', '/Volumes/visits/checkpoint').foreachBatch(process_raw_data).start() query.awaitTermination() - Or use a file system API. Apache Spark Structured Streaming solution is a convenient way to get the data to process but if you are more interested in getting the file names without opening these files for processing, you can implement a reader that will get files created after the previous run. It requires more coding effort, though!
tracking_file = '/Volumes/visits/tracking' last_read_modification_time = get_last_modification_time_from_file(tracking_file) base_dir_volume = '/Volumes/visits/raw' file_infos = dbutils.fs.ls(base_dir_volume) files_to_process = [] new_last_read_modification_time = last_read_modification_time for file_info in file_infos: if file_info.isFile() and file_info.modificationTime > last_read_modification_time: files_to_process.append(file_info.path) new_last_read_modification_time = max(new_last_read_modification_time, file_info.modificationTime) write_new_last_read_modification_time(new_last_read_modification_time, tracking_file)
But none of these solutions will guarantee a complete processing capability. Here comes another limitation of the File trigger which is the files limit in the monitored volume. The trigger will work for the locations with 10 000 exclusively. Good news is, if you use a Unity Catalog external location or volume, this limit applies per subdirectory. Unless you expect getting +10 000 files at once, with an archival mechanism that moves processed files to a different subdirectory, this limit shouldn't be a problem. But yet again, you need to write some code or, if you use Apache Spark Structured Streaming, you can configure the job to use cleanSource=archive alongside the sourceArchiveDir.
📝 The Parallel split pattern
If you have business-specific workflows that need to respond to a new uploaded file, and you want to keep a single triggering workflow, you can leverage the Parallel split pattern (see Chapter 6 of Data Engineering Design Patterns) for that. To trigger depending workflows, you can use the run job task, e.g.
- task_key: trigger_visits_refresh
run_job_task:
job_id: ${resources.jobs.visits.id}
- task_key: trigger_visits_aggregates_refresh
run_job_task:
job_id: ${resources.jobs.visits_aggregates.id}
Besides, you must be aware the trigger doesn't run continuously. It checks for new files every minute, at best (the documentation states "although this can be affected by the performance of the underlying cloud storage"). But as the file trigger runs every minute and it needs to start some infrastructure behind, by design it's not the best choice for continuous processing. This one minute delay shouldn't be a big deal then, especially when all the triggering mechanism is free of charge.

⚠ Infinite triggering
If your job writes new files to the volume used as the file trigger, it'll lead to infinite job executions. For that reason, you should consider consuming from a read-only volume.
To close this shortcomings part, keep in mind the File trigger doesn't handle updates. It only detects new files. A workaround for that, which by the way perfectly fits to mitigating the 10 000 files issue, is archiving already processed files. That way, even if the producer overwrites an already processed file, File trigger will detect it as a new file and trigger the job.
📝 File trigger != stream processing!
Although in this blog post I mentioned Apache Spark Structured Streaming, keep in mind the File trigger doesn't belong to the stream processing! It's more adapted to starting the workloads where the files to processed are delivered undeterministaically, such as sometime between 8 and 11 AM. Stream processing, on another hand, is more reserved to continuous processing of the incoming data. Consequently, the data delivery wouldn't occur between 8 and 11 AM but 24 hours a day.
To be honest, the shortcomings from the second section are here to show the limits so that you can better adapt your future workloads to the File trigger. I'm still positively surprised how Databricks solved this event-driven triggering challenge. Within a single platform, without running a continuous job, you have now a way to start a workflow as a response to a created file. All this is pretty simple, if you use DAB, configuration-driven approach!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about File trigger in Databricks here:
- Databricks release notes February 2023 Databricks release notes February 2024 Trigger jobs when new files arrive
Related blog posts:
- Managing Unity Catalog resources on Databricks
- Hints on Databricks
- Enzyme and Materialized Views on Databricks - better understanding from the SIGMOD-Companion paper