
It has been a while since I didn't write about general distributed systems topics. That's the reason for this article where I will focus on the topic of an optimistic concurrency control.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Since there are a lot of great papers about Optimistic Concurrency Control (OCC), I will just recall some basics in the first section. Rather than competing with them, I will try to complete them with 2 real-world examples. The first one comes from AWS cloud and is presented in the second section. The next example comes from Elasticsearch and is described in the 3rd part of this blog post. All interesting resources are put, as usual, in the "Read also" section below the article.
Definition
OCC tries to solve the problem of concurrent write operations on the same subset of data. Let's imagine the case when 2 different applications want to update a row in a database, nearly at the same time. What you can do? You can have a proxy controller - which by the way becomes a bottleneck, but it's just for the illustration purposes - that will receive every request and create a lock for the manipulated resources. Any subsequent requests working on the same resource will be then rejected and the clients will need to retry or abort their tries.
That's the easiest example for an exclusive lock that belongs to the Pessimistic Concurrency Control family. As you can see, it reserves exclusive write access only to 1 client and it can lead to some issues like deadlocks. Optimistic Concurrency Control takes another approach. It lets all writers write the data (hypothetically) and only before committing the changes, every writer checks whether his changes aren't in conflict with the changes proposed by other writers.
DynamoDB example - condition expressions
An example? Sure, let's take an AWS DynamoDB item that is concurrently updated by 2 clients. In normal circumstances, the second write will invalid the changes of the first one. However, if you use a feature called condition expressions, you can apply a more fine-grained control over the modifications. A conditional expression is like a clause that will validate or abort your write operation. And AWS proposes a wide range of possibilities:
- checking the existence of the writing item (attribute_not_exists on the partition key)
- checking the existence of an attribute (attribute_not_exists or attribute_exists)
- checking the value(s) of attribute(s) (a little bit like SQL's WHERE clause, but set as a condition-expression attribute of the request)
To illustrate that, let's suppose that we've 1 Lambda that processes events from a Kinesis stream. The problem is that we used the brand new parallelization factor, so we can have 2 Lambdas processing data of the same entity (let's say, user events) and the processing logic looks like that:
item_id = kinesis_record.get_item_id() item = get_item_from_dynamodb(item_id) item.count = item.count + 1 dynamodb_client.write(new_count, item)
Without an OCC, we'll lead to the situation when the writes will produce an inconsistent result:
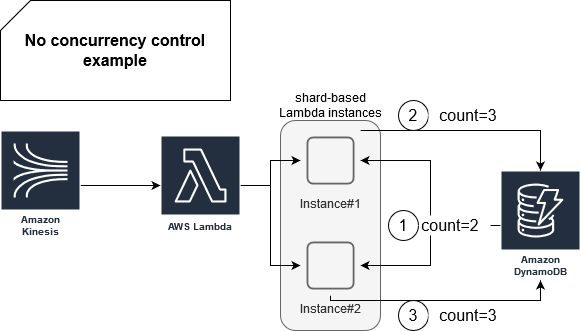
As you can see, every instance starts by retrieving the value equal to 2. Later, it increments it and sends the new result. The problem is that the final result will be 3 instead of 4. To solve that issue, you can prefer the sequential writing from shard which is definitely a simpler option, but you can also use condition expressions:
item_id = kinesis_record.get_item_id() item = get_item_from_dynamodb(item_id) item.count = item.count + 1 previous_change_date = item.last_change_date item.last_change_date = now() dynamodb_client.write(new_count, item, if "last_change_date = previous_change_date ")
And in the picture:
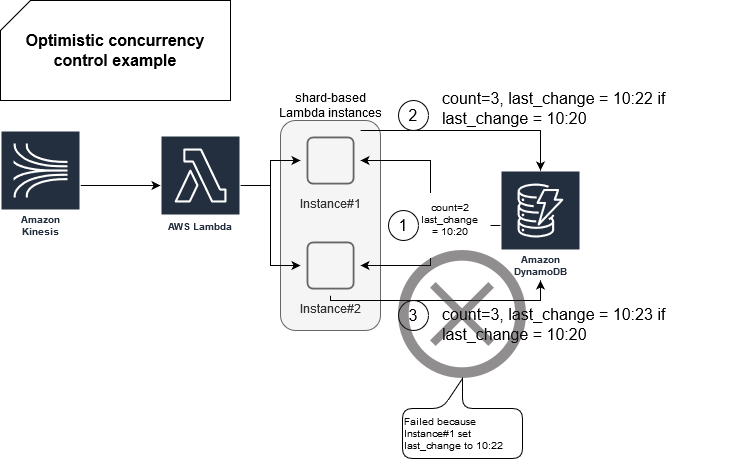
As you can see, the Instance#2 isn't able to update the counter because the condition on last_change attribute failed. Simply speaking, Instance#1 performed the write before Instance#2. However, please notice that I gave this only for illustration purposes. Condition expressions can be more expensive than standard writes (link in Further reading section).
Elasticsearch sequences example
DynamoDB is not the single data store that supports optimistic concurrency control. Another one is Elasticsearch which provides this feature with seqNo and primaryTerm attributes.
What are their meanings? The former one represents a sequence number that increments every time a change is made for the indexed document. Regarding the primary term, it tracks how many times a new primary shard was elected. Just to recall, Elasticsearch partition is called shard and it can be replicated for fault-tolerance. When the primary shard fails, one of the replicas can be promoted and the primary term represents this number of promotions. Why is it important in the context of concurrency control? Some operations may come from the old primary shards and therefore may enter in conflict with the same operations for the new primary shard. In that case, the primary term is used to solve the conflict and reject old changes.
Below you can find a short video showing this use case alongside the code:
val indexName = "test_letters"
val createIndexRequest = new CreateIndexRequest(indexName)
createIndexRequest.source(
"""
|{
|"settings": {
| "number_of_shards": 1,
| "number_of_replicas": 0
|},
|"mappings": {
| "properties": {
| "letter": {"type": "text"}
| }
|}
|}
""".stripMargin, XContentType.JSON
)
val result = client.indices().create(createIndexRequest, RequestOptions.DEFAULT)
// Indexing part
val sequenceNumbers = Seq(
None, Some(0), Some(1), Some(2), Some(5)
)
sequenceNumbers.foreach(maybeNumber => {
val request = new IndexRequest(indexName)
.id(s"test_a")
maybeNumber.map(sequenceNumber => {
request.setIfSeqNo(sequenceNumber)
request.setIfPrimaryTerm(1)
})
val jsonString =
s"""
|{"letter": "AA${maybeNumber}"}
""".stripMargin
request.source(jsonString, XContentType.JSON)
val indexResponse = client.index(request, RequestOptions.DEFAULT)
println(s"indexResponse=${indexResponse.status()}")
println(s"sequence number=${indexResponse.getSeqNo}, primary term=${indexResponse.getPrimaryTerm}")
})
I hope that thanks to these 2 examples the short description of the optimistic concurrency control from the first section is more clear. As you saw, the concurrency control is shared between the client and the server. On one side, the client stores some information that identifies how fresh his knowledge about the data is. On the other side, the server knows the most recent changes to this data. Thanks to this information, the server can figure out if the data sent by the client will introduce the conflicts or not.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Optimistic concurrency control - a little bit of theory and a little bit more examples here:
- AWS Lambda Supports Parallelization Factor for Kinesis and DynamoDB Event Sources Capacity Units Consumed by Conditional Writes On Optimistic Methods for Concurrency Control Optimistic Concurrency Control forDistributed Unsupervised Learning Lecture 05 Optimistic Concurrency Control Distributed Systems (5DV020) Concurrency control Introduce Primary Terms
Related blog posts:
Concurrency control and optimism ? I checked it in my today's post about this topic with an #Elasticsearch example https://t.co/JFEJxoYrTE
— Bartosz Konieczny (@waitingforcode) May 9, 2020