That's the conference I've heard only recently about. What a huge mistake! Despite the lack of "data" word in the name, it covers many interesting data topics and before I share with you my notes from this year's Data+AI Summit, let me do the same for Berlin Buzzwords!
4-day workshop·In-person or online
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to
€7,200 in lost engineering time.
This workshop teaches you to prevent that — unit tests, data tests, and integration
tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.
A Crash Course in Error Handling for Streaming Data Pipeline by Stefan Sprenger
There are 2 types of errors:
Transient - typically temporary that can recover automatically, such as a temporary network connection
Non-transient - are the opposite, so the errors that cannot recover by themselves. The list include: software bugs, serialization/deserialization failures (e.g. input in a different format than expected, like Avro instead of JSON), business rules violation (e.g. data missing in the mandatory fields).
Handling these errors depend on their type:
Transient often solve with the retry mechanism
Non-transient often solve with Dead-Letter Queue pattern. But be aware that it may involve some post-processing
As an alternative for the non-transient errors you can consider dropping them or stop the job to fix the errors manually.
Besides, Stefan also gives some code details on how to implement the Dead-Lettering and retries with Kafka Streams.
Minimizing the memory footprint of Apache Flink by Robert Metzger
Thank you, Robert! I haven't seen such a technically detailed investigation of the JVM in the data context for years! In summary:
"Minimizing Flink" - the term hides the need to deploy Apache Flink for a smaller processing scope than the millions of events per second. For these use cases there is a minimal requirement of 1.67GB (650MB of JobManager + 1024MB of TaskManager) to set up a cluster which can be too much for many small processing jobs to be deployed.
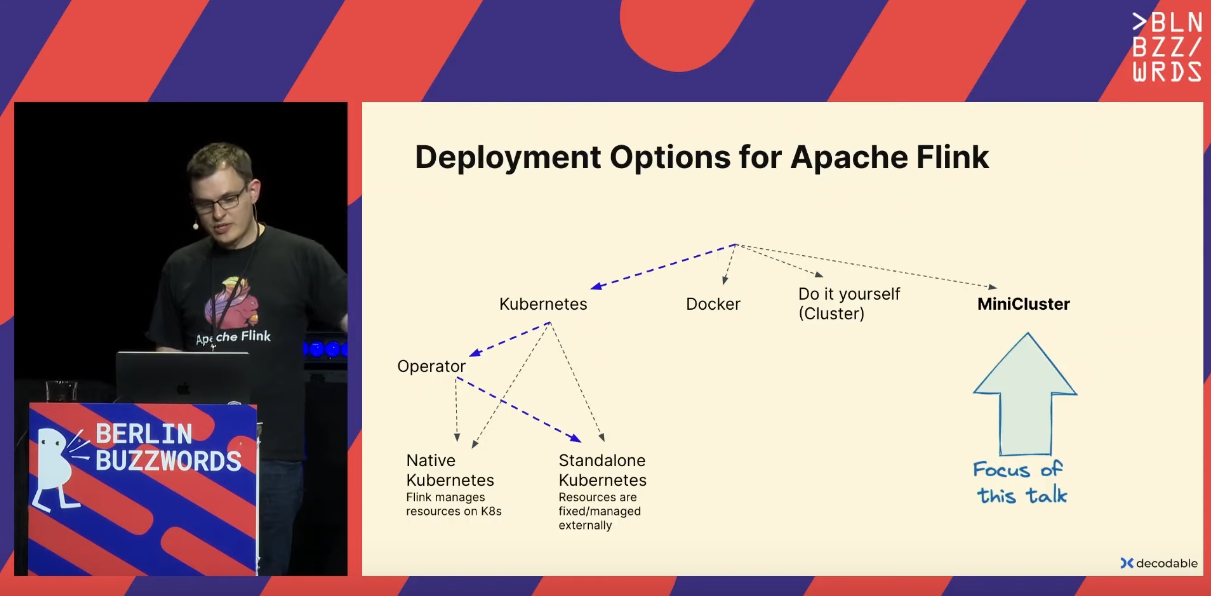
There are different Apache Flink deployment modes:
MiniCluster is a local deployment option that works for small JVM heaps, such as 50MB or 100MB, and throughput of respectively 25 MB/second and 100 MB/second. It may not work for less and lead to OOM due to too high throughput.
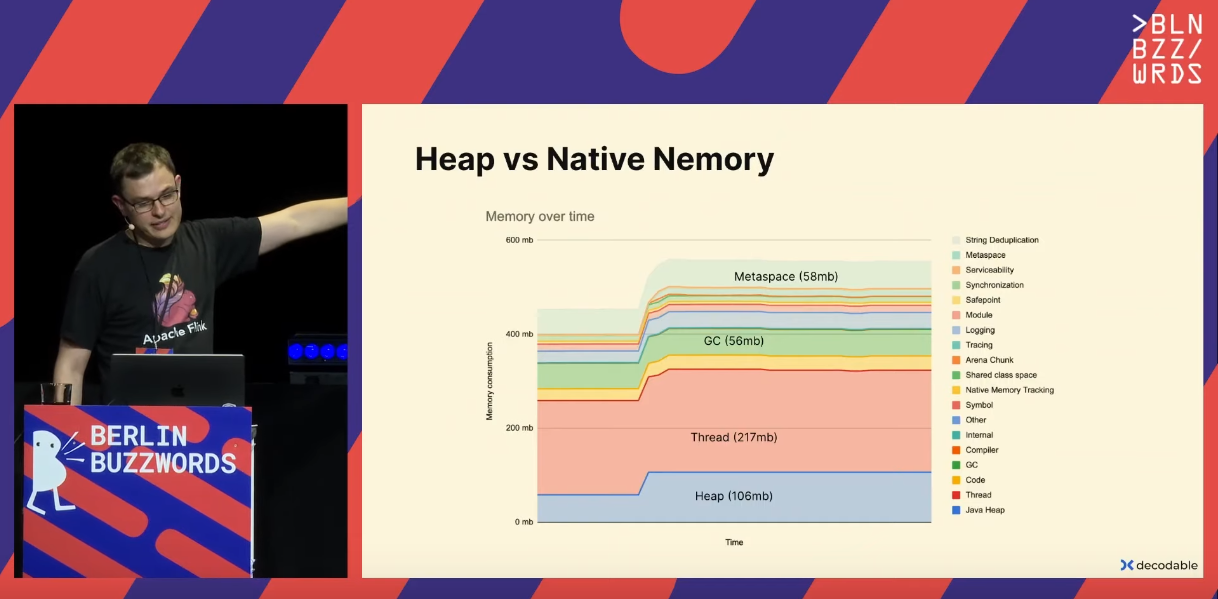
Related to this benchmark, Robert shared his findings on the difference between the Heap limit and Real memory from the screenshot. It comes from the JVM that uses memory for other things, like Metaspace or GC:
You can get the same picture when you enable the Native Memory Tracking JVM feature. And to reduce the size, you can rely on these options (more details in the blog post linked in the end of the slide):
Besides the small data processing, MiniCluster is also the component used in Apache Flink unit tests.
A Kafka Client's Request: There and Back Again by Danica Fine
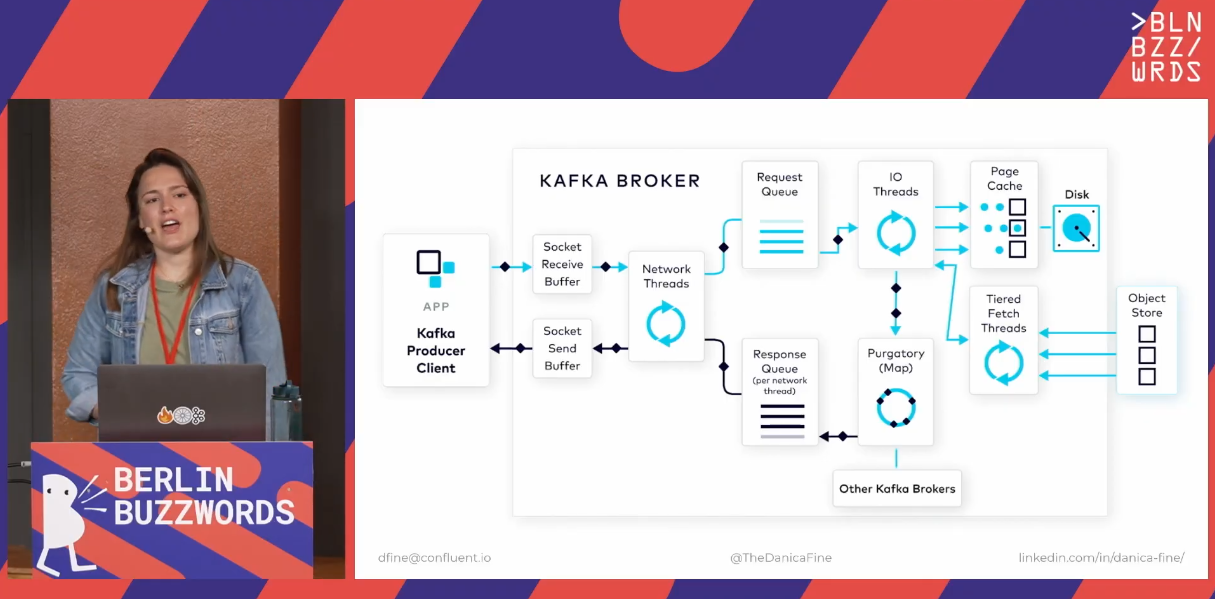
I haven't expected to see an in-depth talk about Apache Kafka elsewhere other than Kafka Summit. Good lord, how wrong I was! Danica shared a great deep dive into Kafka Client's requests. Put differently, she explained this picture in details:
The talk has a lot of details, I'm summarizing here my discoveries or important reminders:
Partitioners
You can enable the adaptive partitioner with the partitioner.adaptive.partitioning.enable. The feature sends the data to the faster brokers.
You can also enable the partitioner.availability.timeout.ms to ignore too slow partitions for a while.
Batching
Each batch applies to an individual topic/partition destination.
Setting linger.ms at the expense of adding more latency because your batch will wait more time hoping to integrate more records into. BUT it can also reduce the latency by putting a smaller pressure on the broker with fewer calls!
To fine-tune the producer you can use the available JMX metrics: batch-size-avg, records-per-request-avg, request-size-avg, buffer-available-bytes, record-queue-time-avg.
Compression data on the producer is an optional step to improve the batch throughput.
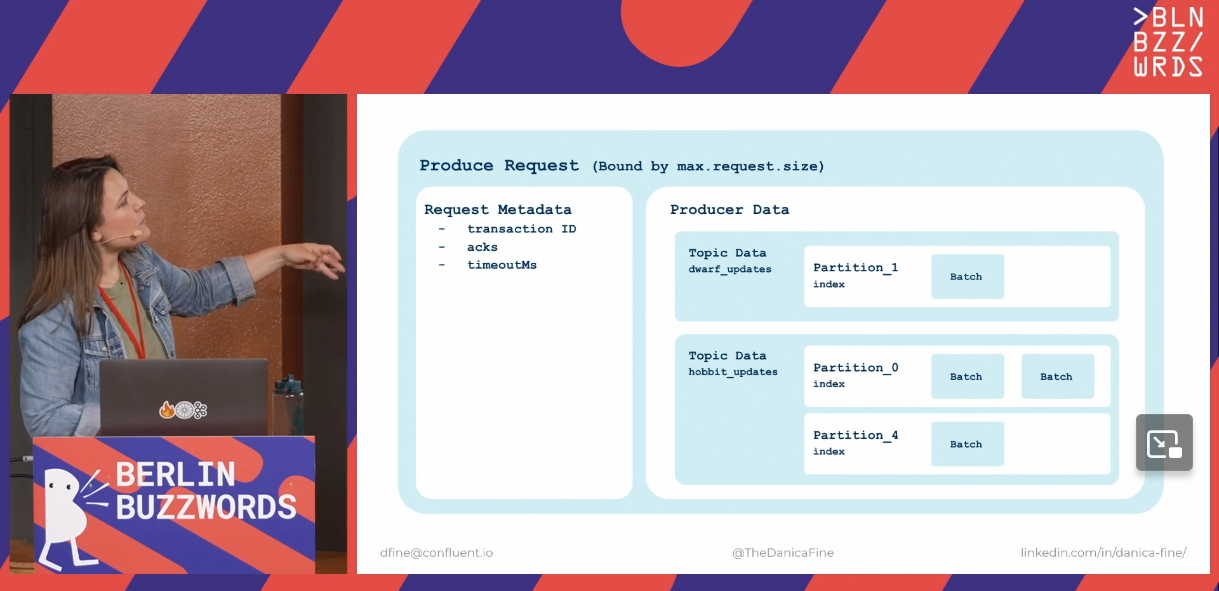
A Producer request eventually ends up with multiple batches, so it can concern multiple topics
What happens when the broker gets the request, in a nutshell:
Socket Receive Buffer - the request lands in this zone, awaiting for processing.
Network threads - the thread analyzes the producer request, resolves its type, and puts it to a request queue. Besides the producer, these threads also handle consumers or admin requests.
Request queue - is the place where the Network thread puts the requests to.
I/O threads (aka Request Handler Threads) - they pick the requests to process from the queue.
Page cache and To disk - the final moment when the data gets physically written to disk.
Purgatory - holds the request until getting all acknowledgments for the replication.
Response queue - queue with the responses to return to the clients.
Network thread hand-off - handles the responses from the queue; last official task of the Network thread.
Socket Send Buffer - the place where the responses go before being delivered to the producer.
Apache Airflow in Production - Bad vs Best Practices by Bhavani Ravi
Because it's always to have a handy list of best practices, I couldn't miss Bhavani's talk about them in Apache Airflow!
Bhavani avoids using the .0 version as much as possible. They can be more buggy than the minor releases.
What executor to use? It depends!
Kubernetes if you need task isolation, have large and resource hungry tasks, or need on-demand resources
Celery if you have short but many tasks, or if you need always-on runners
As a reminder, Kubernetes tasks are created on-demand by the scheduler while Celery instances are continuously running, even if there is nothing to process. They don't have the bootstrap cost but can be less cost-efficient than Kubernetes.
If you deploy the metadata store as a Docker image, do mount volumes. Otherwise, you'll lose everything at the container's crash.
Lock the versions in the requirements to avoid chaos in the future releases.
Three 3 modes of connecting DAGs folder to the Airflow instance: mount volume to the scheduler, Github repo to the scheduler, or directly integrated to the Docker image. If your Airflow is very dynamic, you should prefer the former 2 options.
Savannah gave a great talk about probabilistic data structures. How good was to refresh my memory and discover the structures I haven't covered in my exploration back in 2018. Some takeaways from the talk:
Pretty convincing example on when they're useful: a hash table with 1 million URLs takes at least 25 MB while the Bloom filter for the same use case only 1.13 MB for a 1% false positive rate!
The opposite for probabilistic data structures are deterministic data structures.
Hash definition by Savannah: "any function that can be used to map data of arbitrary size to fixed-size values".
Probabilistic data structure sacrifices a little bit of accuracy for space and speed.
Savannah gives a lot of details for each of the presented structures. This slide summarizes them pretty well:
Besides the structures presented in the talk, Savannah also quoted 3 other ones: Cuckoo Filter, Hyperloglog, and T-Digest.
Hadoop Vectored IO: your data just got faster! by Steve Loughran
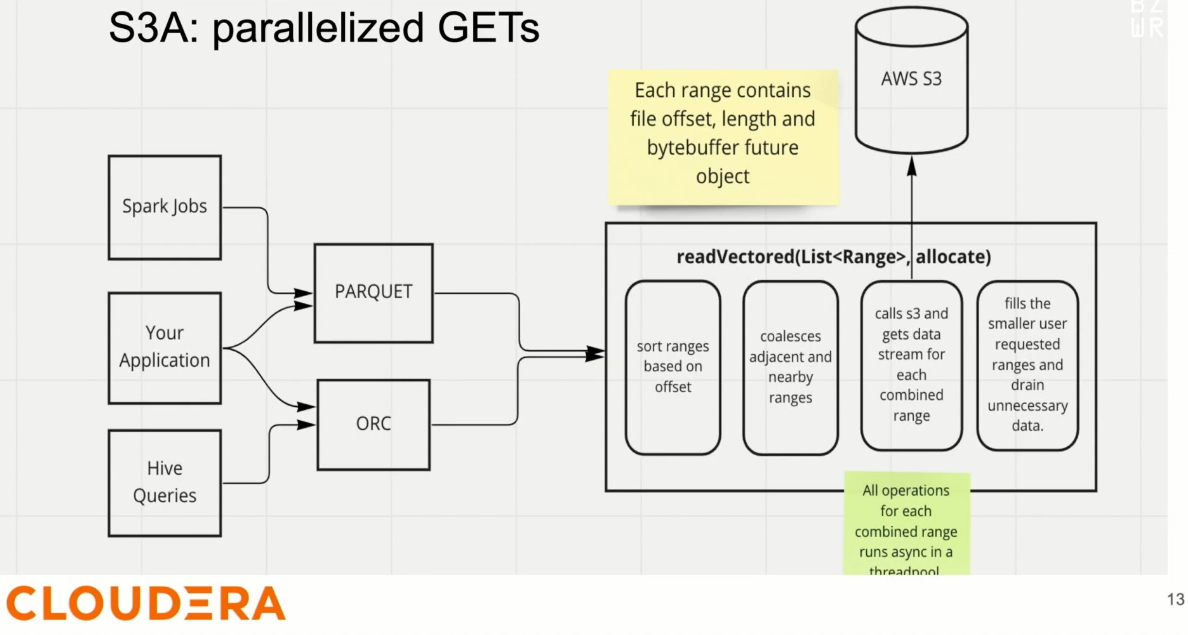
Steve Loughran explained a new Hadoop Vectored IO that improves reading from the cloud object stores:
Vectored IO is an inspiration from the Linux API, and more exactly the readv and writev that respectively, reads and writes data into multiple buffers. Nothing better than Steve's slide to explain the nitty-gritty details!
As you can see, the idea is to read multiple ranges, ideally, in parallel and not blocking. As a consumer you can then process the response as they come instead of waiting for all them to be completely delivered.
Still hungry for the internal details? Steve shared a more detailed schema!
Because of the asynchronous reading, your code must be adapted but again, there is a ready-to-use example:
e:
And most importantly, does it help? According to Steve's microbenchmark for Apache Hive and ORC, the reduced execution time went from 20% to 70%, depending on the measurement method.
Important things to notice, the API doesn't affect Apache Avro and CSV file formats. It mostly optimizes columnar file formats. There is an ongoing effort to implement the feature on GCS and Azure Blob.
There is a new Apache Hadoop library called hadoop-api-shim to "allow hadoop applications to call the recent higher-performance/cloud-aware filesystem API methods when available, but still compile against and link to older hadoop releases".
I also had plans to watch the talks about column lineage, Kaldb, ClickHouse, and Data Mesh migration, but finally needed to postpone due to other topics waiting in my head. For sure, I'll watch them one day but in the meantime, I prefer to share the notes for the 6 first watched presentations, hopefully you find them useful!
Data Engineering Design Patterns
Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
Share, like or comment this Berlin Buzzwords 2023 - notes for data engineers on Twitter
I haven't known about this conference until this year! Berlin Buzzwords, despite the lack of data and engineering in the name, covers various data engineering topics. My summary of the 2023 edition in this blog post ? https://t.co/GLPDtGtIp9
Share, like or comment this Berlin Buzzwords 2023 - notes for data engineers on LinkedIn
📚 Newsletter Get new posts, recommended reading and other exclusive information every week. SPAM free - no 3rd party ads, only the information about waitingforcode!




 You can get the same picture when you enable the Native Memory Tracking JVM feature. And to reduce the size, you can rely on these options (more details in the blog post linked in the end of the slide):
You can get the same picture when you enable the Native Memory Tracking JVM feature. And to reduce the size, you can rely on these options (more details in the blog post linked in the end of the slide):



 As you can see, the idea is to read multiple ranges, ideally, in parallel and not blocking. As a consumer you can then process the response as they come instead of waiting for all them to be completely delivered.
As you can see, the idea is to read multiple ranges, ideally, in parallel and not blocking. As a consumer you can then process the response as they come instead of waiting for all them to be completely delivered.
 e:
e:

