
Data contracts was a hot topic in the data space before LLMs and GenAI came out. They promised a better world with less communication issues between teams, leading to more reliable and trustworthy data. Unfortunately, the promise has been too hard to put into practice. Has been, or should I write "was"?
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
A data contract is an agreement between data producer and data producers regarding the data structure (schema), data availability, data quality, security guidelines, or SLA. Put differently it's just a document describing what consumers could expect from the dataset.
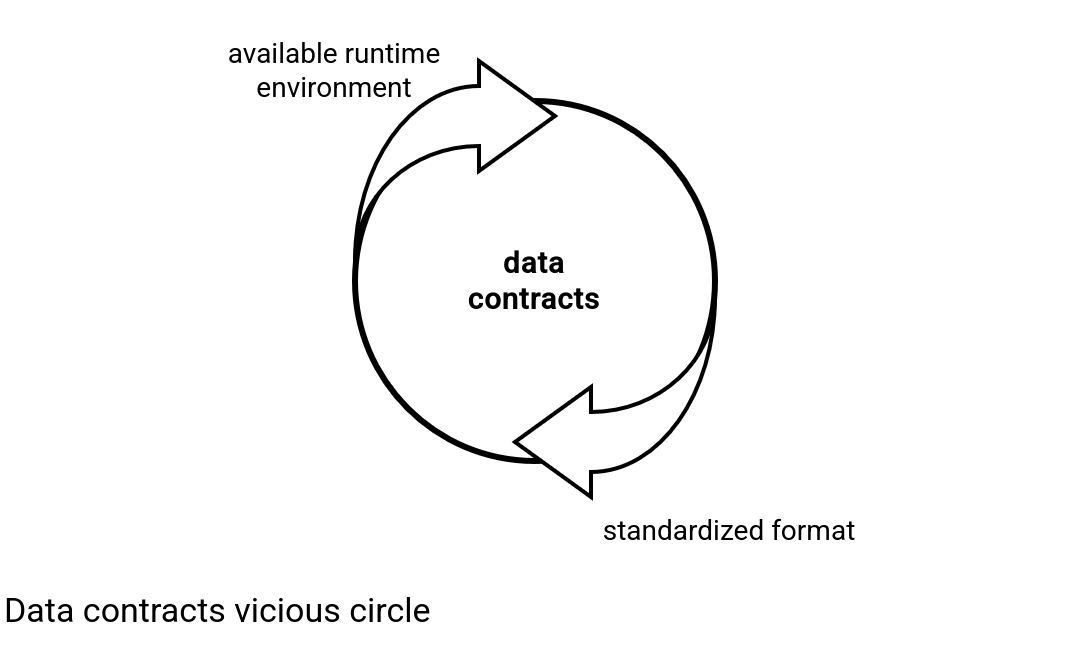
But do not get the just wrong. Conceptually data contracts are a great advancement in standardizing data exchanges that have often been failing in organizations because of data silos and lack of shared documentations of data expectations. The just in my sentence was only here to describe a static character of the idea that was caused by the lack of an official runtime implementation. The runtime was not possible to implement because there wasn't a standardized data contracts format. It's was a vicious circle.
Bitol
To solve the vicious circle you can start by implementing some processing logic and adapt the format later. The drawback of this approach will be a tight coupling between the logic and the format. On another hand, you, a data contracts advocate, will provide a runtime other users can leverage to. An alternative solution is to start by the format definition. The output format here won't be affected by any coding choices and probably, will better suit for different runtimes. However, your potential users will have to contribute and adapt the processing logic to your standard.
Early in 2025 I have heard for the first time about Bitol. Bitol is a Linux Foundation project which goal is to set standards for data contracts:

Put differently, Bitol is a standardized YAML document data teams that can rely on to build their data contracts management library.
Alternatives
While I was writing this blog post, I found another data contracts specification, the datacontract.com.
Bitol and Open Data Contract Standard
A data contract implemented according to the Open Data Contract Standard (ODCS) defined by Bitol [discussed version 3.0.1] should start with some high-level information to show clearly identify what the given contract is about, without entering too much into technical details:
# ODCS version apiVersion: v3.0.1 # type of the file, as of today DataContract is the single supported attribute kind: DataContract # required, unique id, must be unique to avoid name collisions id: 53581432-6c55-4ba2-a65f-72344a91553a # not required name of the contract document name: seller_payments_v1 # contract version described in this document version: 1.0.0 # status of the contract, one of "proposed", "draft", "active", "deprecated", "retired" status: active # logical data domain domain: visits # data product of the domain dataProduct: click_events tenant: InputVisitsEvents #TODO: this is not that clear description: purpose: Raw events for the users visits. limitations: "Requires data cleansing as it might contain duplicates or inconsistent dates" # where the data should be used, e.g. to ingest it to the silver layer usage: "Data ingestion to the silver layer in the Medallion architecture" tags: ['clicks', 'event data']
Once these high-level attributes are defined, you can go to the next part which is more technical. You'll find here properties like:
- schema with data quality checks made on each defined field
- servers that stands for the physical location of the dataset
- roles that identify the access levels
- team where you can define the team members responsible for the dataset described in the contract document
- slaProperties that show what the consumers should expect from the dataset in terms of SLA
Let's see how to add these elements to our initial high-level document:
# ...
schema:
- name: event
logicalType: object
physicalType: record
properties:
- name: event_id
logicalType: string
physicalType: UUID
required: true
primaryKey: true
examples:
- 550e8400-e29b-41d4-a716-446655440000
- name: user_id
logicalType: string
physicalType: VARCHAR(36)
required: false
examples:
- user_7685a5e0
- guest
- name: event_time
logicalType: date
physicalType: TIMESTAMP
required: true
logicalTypeOptions:
format: 'yyyy-MM-dd''T''HH:mm:ssZ'
examples:
- '2024-03-15T14:30:00+0000'
- name: device_type
logicalType: string
physicalType: VARCHAR(20)
required: true
enum:
- desktop
- smartphone
- tablet
- other
examples:
- desktop
- smartphone
- name: browser_info
logicalType: object
physicalType: STRUCT
properties:
- name: browser_name
logicalType: string
examples:
- Chrome
- Safari
- Firefox
- name: browser_version
logicalType: string
examples:
- 120.0.0
- '17.2'
- name: blog_post_id
logicalType: string
physicalType: VARCHAR(50)
required: true
examples:
- post-123
- guide-456
- name: visit_duration
logicalType: integer
physicalType: INT
description: Duration in seconds
examples:
- 45
- 120
- 300
quality:
- type: custom
engine: greatExpectations
implementation: |
type: expect_visit_duration_between
kwargs:
minValue: 1
maxValue: 500
- type: sql
query: 'SELECT COUNT(*) FROM ${table} WHERE event.event_time > CURRENT_TIMESTAMP()'
description: Future-dated events check
severity: warning
team:
- username: web-analytics-team@waitingforcode.com
role: Data Owner
dateIn: '2023-06-01'
- username: data-eng@waitingforcode.com
role: Pipeline Maintainer
dateIn: '2023-07-15'
roles:
- role: analyst
description: Read access for analysis
access: read-only
firstLevelApprovers: Analytics Manager
slaDefaultElement: timestamp
slaProperties:
- property: latency
value: 15
unit: minutes
driver: analytics
description: Maximum allowed event processing delay
Data contract and dreams
Data contracts are static by nature. As you saw, they describe what a consumer should expect from the dataset but alone doesn't bring any immediate value. Put differently, either producer or consumer must write some code or queries to validate the contract engagements, such as schema or data quality. My hidden dream about data contracts in general is their integration with modern data engineering tools we use for the infrastructure definition, data quality, access management, or yet data observability. If the dream comes true, the YAML engineering will be a real job title.
I'm kidding with the YAML Engineer, you'll still have to write some code at some point but my dream is real. I would like a data contract file to translate dynamically to a Terraform resource, such as Delta Lake table in Unity Catalog, an S3 bucket, ... a data quality check to be translated to the code of the data quality engine of my choice (Spark Expectations, Great Expectations, you name it!), or yet an SLA configuration to be translated to a Grafana dashboard or a AWS CloudWatch alert as code.
But before the dream comes true, the industry must agree on the format to follow. Otherwise, we won't be able to automate things easily.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Data contracts and Bitol project here:
Related blog posts:
- On tests in data systems
- Alerts, guards, and data engineering
- Agnostic data alerts with ydata-profiling