
Even though data engineers enjoy discussing table file formats, distributed data processing, or more recently, small data, they still need to deal with legacy systems. By "legacy," I mean not only the code you or your colleagues wrote five years ago but also data formats that have been around for a long time. Despite being challenging for data engineers, these formats remain popular among business users. One of them is Excel.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Before you discover challenges - if you haven't discovered them in real-life, lucky you! - for processing Excel files, let's take a step back and try to understand why we still need to deal with Excel files. To answer the question, nothing better than asking another one, what instead of Excel?
- A text document with JSON structure?
- A User Interface simulating Excel behavior and exporting the output as Apache Parquet?
- Natural language converted to file with LLMs?
- ...any other thoughts?
Let's see, why any of the above alternatives won't be better than Excel for a simple corporate environment:
- A text document with JSON structure? - Do you imagine your business users opening Visual Code, checking the "wrap lines" option in, and editing the document line by line?
- A User Interface simulating Excel behavior and exporting the output as Apache Parquet? → Do you have a budget for the implementation and the maintenance? Excel has it for "free" [that said, included in the licensing fees].
- Natural language transformed with LLMs? - Will the LLMs always be able to translate human input to easily processable output? If not, how it would be different from Excel where users can make simple mistakes, including typos, type changes etc.?
Long story short, if you cannot afford building a custom UI, Excel is still a valid UI-based solution enabling business users to interact with the data world where you, as a data engineer, is living. Hopefully, this blog post will make your life easier, or at least, provide a set of tips for your next Excel data processing challenges.
Challenges - data
Let's start with the challenges related to the data. Maybe the first issue you'll notice is the lack of proper NULLs. It's up to you to determine whether an empty cell should be translated as a missing value or simply as an empty string. Both formats represent some form of emptiness but they won't behave the same in your processing logic. A transformation applied on a NULL value will generate a NULL in return while the one on an empty string will always output a value or throw an error.
⚠ Types war
An empty string will be casted to the type required by the operation. Consequently, casting an empty string to a number or boolean will not be possible and your query will throw an error, like below where I tried to divide a number by a string column:
[CAST_INVALID_INPUT] The value ' ' of the type "STRING" cannot be cast to "BIGINT" because it is malformed. Correct the value as per the syntax, or change its target type. Use `try_cast` to tolerate malformed input and return NULL instead. SQLSTATE: 22018
On another hand, if you divide a number by a NULL, the operation will return NULL:
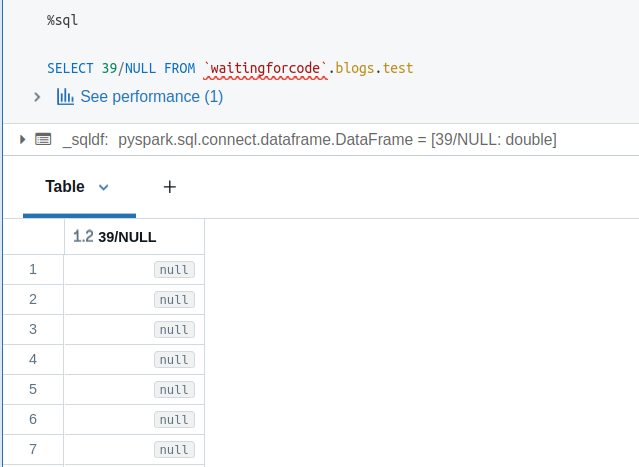
But emptiness consideration is not a single data-related challenge. As by default everything is a string, other high-level types - to not quote struct types! - are missing. Put differently, even though you expect a column to contain only dates, nothing guarantees you'll be able to process it effortlessly. For example, the aforementioned date column can store dates defined as "10-May-2025", as well as "10/05/2025", or yet "2025-05-10"... Even worse, your column can contain only integers and be resolved to a decimal type. Or the column can have a date expressed as text or epoch milliseconds.
Yet another problem related to the lack of control are typos in header columns or even worse, placing header columns in an arbitrary position in the Excel sheet. And the position-based schema resolution doesn't help here as the users could also - mistakenly or not - reverse column positions in the header, leading to unexpected errors in your processing.
Another challenge is navigation. Your users might work on well isolated Excel files where each sheet represents a unique concept, such as sales stats, mapping, or anything else. Otherwise, you might deal with Excel-table-monsters where multiple tables are contained in the same sheet and the single way of accessing them is to explicitly delimit them by positions.
Challenges - I/O
The next challenges category is about the I/O. First, the most obvious part, reading Excel files. Other challenging formats like CSVs are text-based meaning that you don't need anything special to access them; a simple text reader is enough. It's not the case of Excel which is binary and so despite supporting Office Open XML (thus XML) format.
💡 Getting Excel's XML
To get the hidden XML for modern Excel files, you can convert the file to a compressed archive like a ZIP, and decompress it.
As for any other binary files, Excel files are hard to process in parallel, i.e. if you have many files and want to use a distributed data processing framework, you'll typically end up processing a bunch of files in each task. It's not the case for text-based file formats that can be divided and processed concurrently in different tasks.
Besides these pure reading aspects, there is another one related to the binary format, the readers. Again, compared to a text format or even binary but open as Apache Parquet, reading the Excel files programmatically is less standardized. Needless to say, in Python you can read Excel files with openpyxl, calamine, odf, pyxlsb, or xlrd!
Solutions for data challenges with Pandas
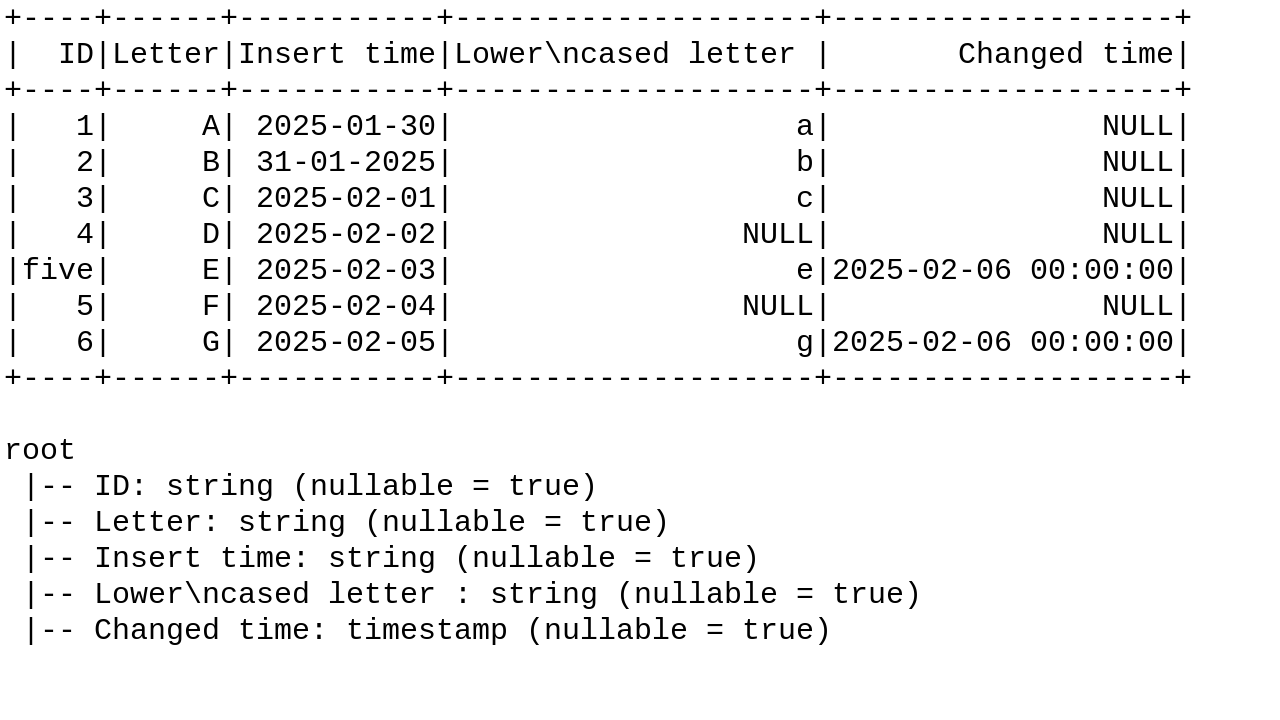
Now when we have taken a look at the challenges, let's see how to address them with code. To start simple, we're going to focus on the data-related challenges first that we're going to solve with the following Excel file:
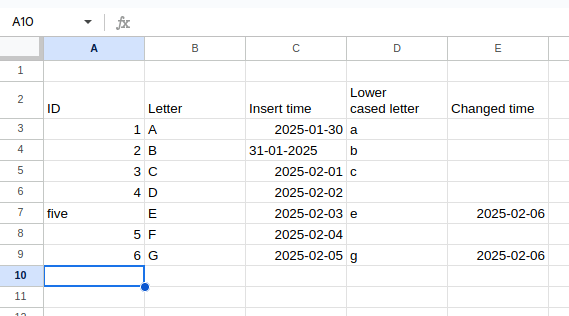
When you use the default reading method - maybe the most common for data engineering workloads today - which is pandas.read_excel('excel_file.xls'), you will get pretty unexploitable DataFrame:
Unnamed: 0 Unnamed: 1 ... Unnamed: 3 Unnamed: 4 0 ID Letter ... Lower\ncased letter Changed time 1 1 A ... a NaN 2 2 B ... b NaN 3 3 C ... c NaN 4 4 D ... NaN NaN 5 five E ... e 2025-02-06 00:00:00 6 5 F ... NaN NaN 7 6 G ... g 2025-02-06 00:00:00
And when you try to convert this Pandas DataFrame to an Apache Spark DataFrame, you'll get the following error:
File "pyarrow/array.pxi", line 1116, in pyarrow.lib.Array.from_pandas File "pyarrow/array.pxi", line 340, in pyarrow.lib.array File "pyarrow/array.pxi", line 86, in pyarrow.lib._ndarray_to_array File "pyarrow/error.pxi", line 91, in pyarrow.lib.check_status pyarrow.lib.ArrowTypeError: Expected bytes, got a 'int' object:
Besides the error, you can clearly notice a few important problems here:
- Missing headers. Since the headers were defined in the second row, the reader didn't pick them up correctly
- Missing nulls. You can see NaNs to represent missing values.
- Special characters present in the header. It's a typical example of a typo error where a new line and whitespace were left by the author of the file. Although it won't fail your processing code, it'll make its definition more difficult.
- Types issues. As you can notice, the Insert time column has inconsistent time formats.
Good news is, Pandas' read_excel method addresses the issues out-of-the-box. Let's start with the header-related issues. To mitigate the missing headers and special characters in the header, we need to rethink the processing logic and start by getting the header row exclusively. With Pandas you can achieve that by skipping the first row and reading only one row after. In the code, it translates to:
header_only = pd.read_excel('wfc tests.xlsx', skiprows=0, nrows=1)
schema_fields = header_only.values[0]
From now on, you can cleanse the column names, for example with the following code:
cleaned_fields = [field.lower().strip().replace('\n', '').replace(' ', '_') for field in schema_fields]
# cleaned_fields = ['id', 'letter', 'insert_time', 'lowercased_letter', 'changed_time']
The next step consists of reading the data with the schema coming from the cleaned_fields list. It's also the moment where we're going to address data consistency issues for the Insert time column or the type confusion for the ID column. Yet again, Pandas come with built-in support to deal with this kind of problems thanks to the names attribute to handle the new schema, and the converters attribute to manage data transformation at reading. The next snippet we should add looks then like:
def convert_id(value: str) -> int:
if value == 'five':
return 5
else:
return int(value)
def convert_insert_time(value: str|datetime.datetime) -> datetime.datetime:
if type(value) is str:
return datetime.datetime.strptime(value, '%d-%m-%Y')
return value
cleaned_dataset = pd.read_excel('wfc tests.xlsx', skiprows=1, na_filter=True,
converters={'id': convert_id, 'insert_time': convert_insert_time},
names=cleaned_fields)
Now the Pandas DataFrame looks correct and we can either write it somewhere, or convert to Apache Spark's DataFrame. For the latter option PySpark comes with an utility method that wraps original Pandas DataFrame and converts it to the Apache Spark DataFrame in just one line:
import pyspark.pandas as ps ps.DataFrame(cleaned_dataset).to_spark()
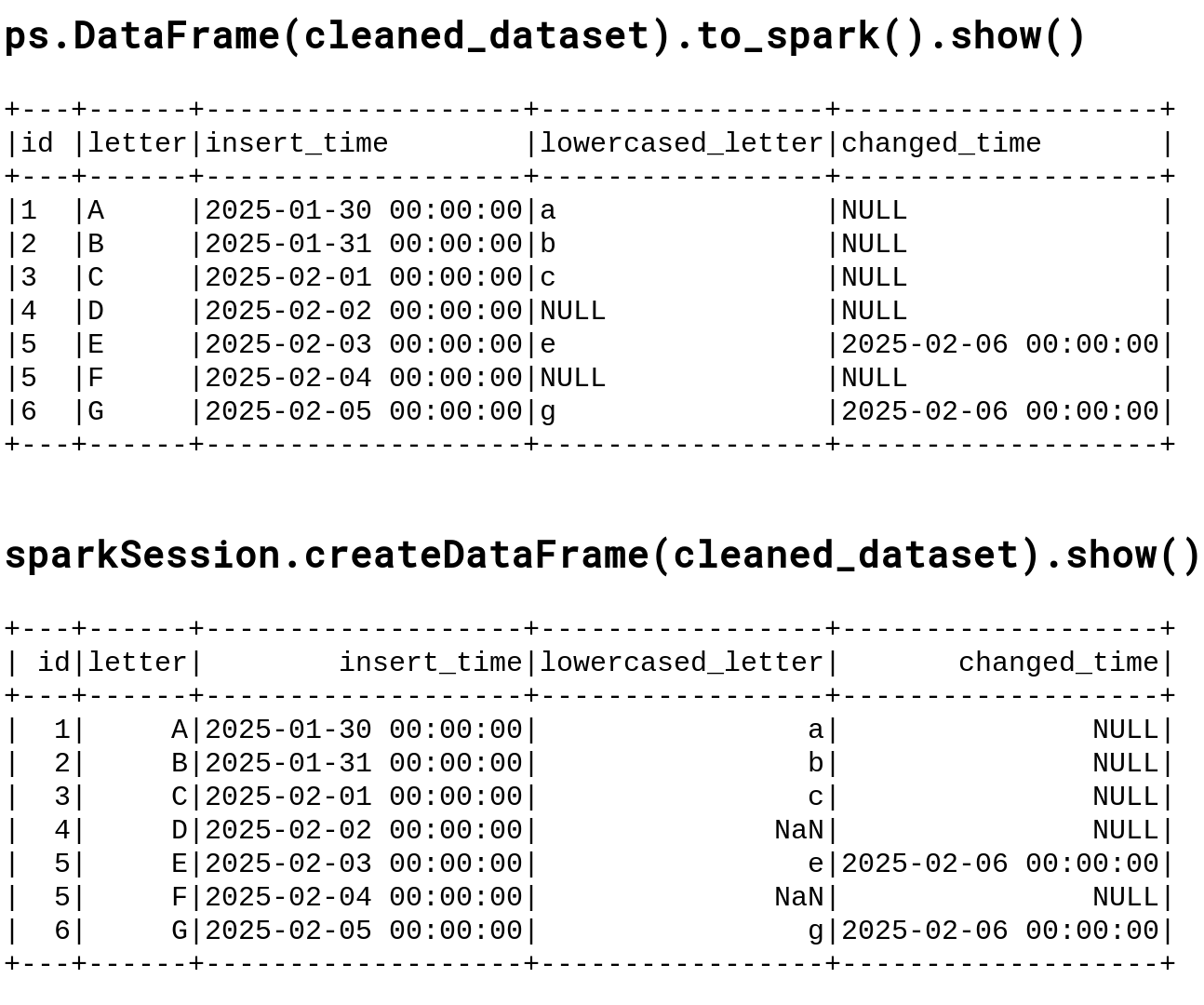
At this moment it's worth noting that if you converted the Pandas DataFrame into Apache Spark DataFrame with a createDataFrame method, it would generate an inconsistent result for the lowercased_letter column which, for the to_spark version correctly converts to NULL while the createDataFrame version translates NaN into "NaN" text:
💡 Columns setting
Another way to replace column names is by setting them with DataFrame.columns, such as:
my_dataframe.columns = ['column1', 'column2']
Solutions for data challenges with PySpark
If you don't know Pandas or simply prefer to use PySpark for all transformations in your code base, you can adapt the previously introduced processing mode. The adaptation starts by applying a schema that will consider all columns as strings. For that, we can rely on the schema detection method presented before and pass the retrieved schema to dtype parameter:
header_only = pd.read_excel('wfc tests.xlsx', skiprows=0, nrows=1)
schema_fields = header_only.values[0]
cleaned_fields = [field.lower().strip().replace('\n', '').replace(' ', '_') for field in schema_fields]
mapped_schema = {column: str for column in cleaned_fields}
cleaned_dataset = pd.read_excel('wfc tests.xlsx', skiprows=1, names=cleaned_fields, dtype=mapped_schema)
ps.DataFrame(cleaned_dataset).to_spark().show(truncate=False)
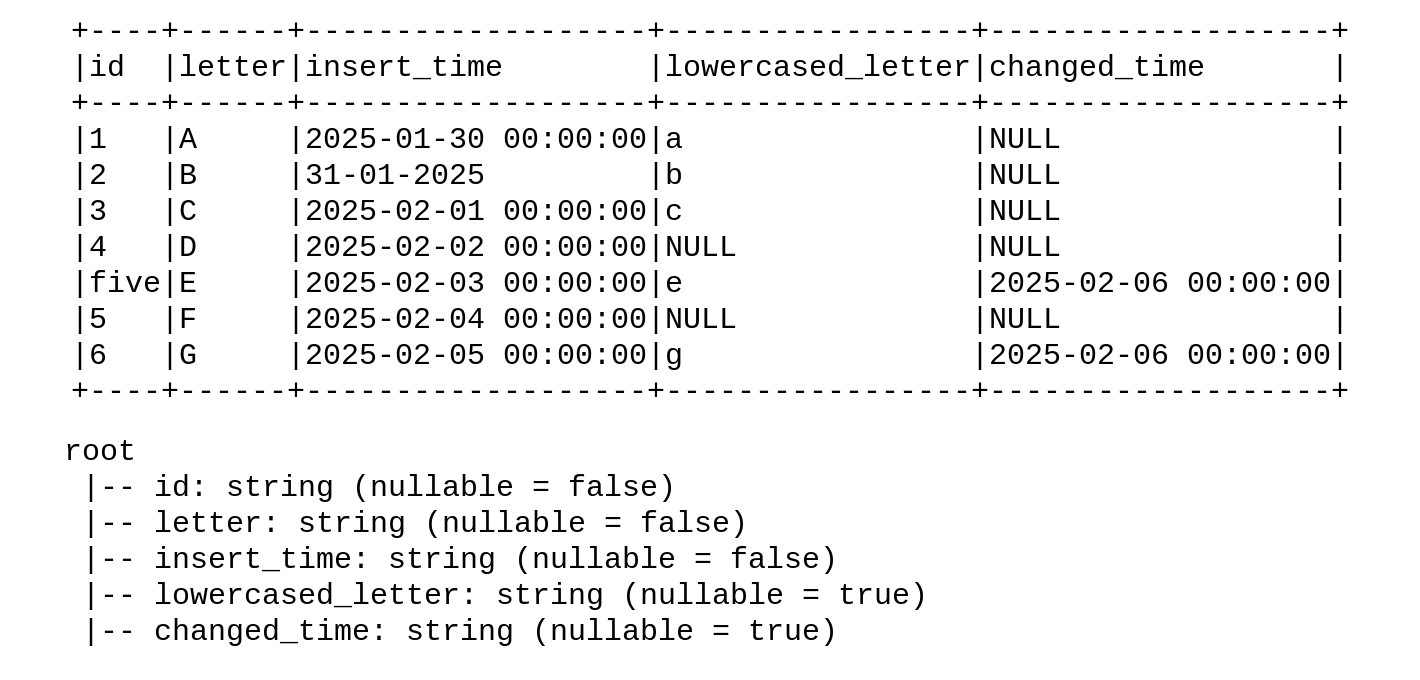
The code will consider each column as a string:
From that you can transform the raw data with one of PySpark's mapIn* functions, a UDF, or native column transformations.
Solutions I/O
When it comes to the scaling issue of the I/O challenge, there are at least two possible approaches. The first one is to use Spark Excel Library, originally known as com.crealytics, since then renamed to dev.mauch package. It's a native PySpark alternative to reading Pandas files. Consequently, to read our highly inconsistent wfc_test.xlsx, we need to write the code like this:
spark_session = (SparkSession.builder.master('local[*]')
.config('spark.jars.packages','dev.mauch:spark-excel_2.12:3.5.3_0.30.0')
.getOrCreate())
spark_session.read.format('excel').options(dataAddress='A2', inferSchema=True)
.load('/tmp/wfc tests.xlsx')
The results would be:
As you can see, there are still some schema issues but they can be easily solved with Apache Spark's withColumnsRenamed function. Anyway, the Excel library leverages Apache Spark data source API to perform parallel reading of the input Excel files:
# https://github.com/nightscape/spark-excel/blob/aa53d60c9cdb82655de1bf9940d8f3f902240d69/src/main/scala/dev/mauch/spark/excel/ExcelRelation.scala#L23
case class ExcelRelation(
// ...
override def buildScan(requiredColumns: Array[String]): RDD[Row] = {
val lookups = requiredColumns.map(columnExtractor).toSeq
workbookReader.withWorkbook { workbook =>
val allDataIterator = dataLocator.readFrom(workbook)
val iter = if (header) allDataIterator.drop(1) else allDataIterator
val rows: Iterator[Seq[Any]] = iter.flatMap(row =>
Try {
val values = lookups.map(l => l(row))
Some(values)
}.recover { case _ =>
None
}.get
)
val result = rows.toVector
parallelize(result.map(Row.fromSeq))
}
}
private def parallelize[T : scala.reflect.ClassTag](seq: Seq[T]): RDD[T] = sqlContext.sparkContext.parallelize(seq)
However, the Spark-Excel library is not an officially supported package. If it's your concern, you can build your own Excel reader in PySpark by combining the binary source and the Pandas code we implemented previously:
excels_dataset_to_read = (spark_session.read.format('binaryFile')
.options(pathGlobFilter='*.xlsx')
.load('/home/bartosz/workspace/isen/iqore-veeva/scratch/excel_tests/')
.drop('content'))
def read_excel_with_pandas(binary_row: Row):
header_only = pd.read_excel(binary_row.path, skiprows=0, nrows=1)
schema_fields = header_only.values[0]
cleaned_fields = [field.lower().strip().replace('\n', '').replace(' ', '_') for field in schema_fields]
mapped_schema = {column: str for column in cleaned_fields}
cleaned_dataset = pd.read_excel(binary_row.path, skiprows=1, names=cleaned_fields, dtype=mapped_schema)
print(cleaned_dataset)
excels_dataset_to_read.foreach(read_excel_with_pandas)
excels_dataset_to_read.show(truncate=False)
excels_dataset_to_read.explain()
The code prints:
id letter insert_time lowercased_letter changed_time 0 1 A 2025-01-30 00:00:00 a NaN 1 2 B 31-01-2025 b NaN 2 3 C 2025-02-01 00:00:00 c NaN 3 4 D 2025-02-02 00:00:00 NaN NaN 4 five E 2025-02-03 00:00:00 e 2025-02-06 00:00:00 5 5 F 2025-02-04 00:00:00 NaN NaN 6 6 G 2025-02-05 00:00:00 g 2025-02-06 00:00:00
And for the show and explain:

One point to notice, though. With the aforementioned method you won't be able to create a DataFrame inside the foreach function as it's a not allowed operation:
pyspark.errors.exceptions.base.PySparkRuntimeError: [CONTEXT_ONLY_VALID_ON_DRIVER] It appears that you are attempting to reference SparkContext from a broadcast variable, action, or transformation. SparkContext can only be used on the driver, not in code that it run on workers. For more information, see SPARK-5063.
As you can see, processing Excel files is not an easy task. The binary file format is one difficulty but compared to the human errors in types or column names is just a tiny issue that can be natively solved with Pandas or PySpark!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩