
Timely and accurate data is a Holy Grail for each data practitioner. To make it real, data engineers have to be careful about the transformations they make before exposing the dataset to consumers, but they also need to understand the timeline of the data.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this blog post we're going to see different time terms you may encounter while dealing with datasets. But before we go into details, let's see what need to happen before you receive a new record to process:
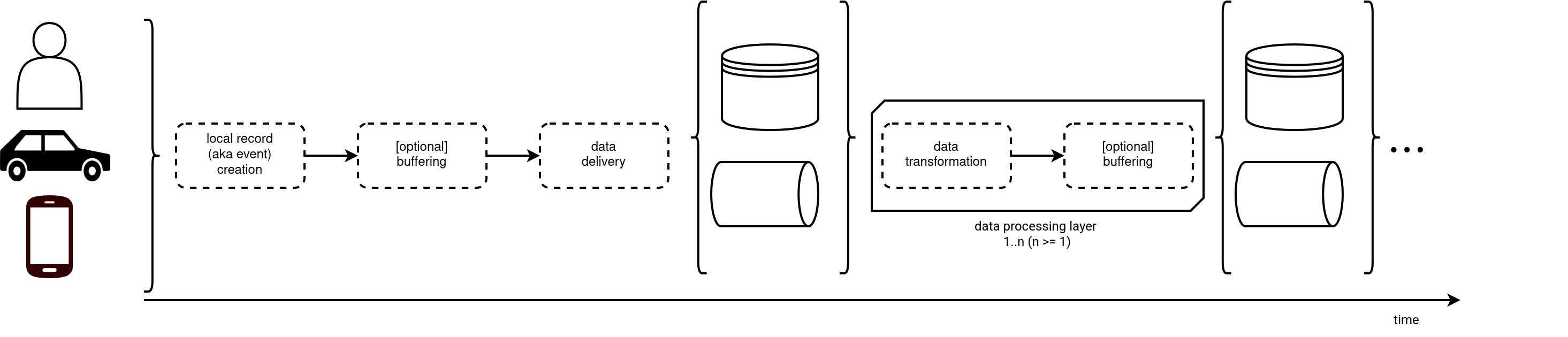
As you can notice, the timeline starts with data producers that can be humans making some explicit actions, or IoT devices emitting signals in an automated manner. They produce events that may be buffered locally to avoid too many network trips and optimize the delivery loop. Soon after the delivery is triggered, the events land in a data store from where the first data processing jobs can start transforming the records. As the jobs write their outcome to other data stores, there is a possibility to have multiple sequential or concurrent data transformations following the initial data ingestion.
Time
The picture shows pretty clearly - the closest you're to the left, the better data freshness should be. Unfortunately, that's just a theory and to understand better why, we need to introduce some time-related concepts. Let's redo the schema but this time with some additional time annotations:

On the leftmost part you have the event time. It represents when a given event really happened. For example, if your user clicked on a link in your website, the click's time will be represented as the event time in the whole system. An important property of the event time is the immutability. Put differently, you cannot change it. At this occasion it's worth mentioning zones time conversion; on one hand it doesn't alter the current change but standardizes it to a common time zone, such as UTC. On another side, each transformation brings a risk of introducing errors that consequently will alter the original value. Therefore, how to adapt this timestamp field? Change-in-place or decorate? There is no easy answer to that question:
- data decoration approach is safer as it creates a new field with the standardized time value, for example event_time_utc where original event time will be stored as UTC
- change-in-place approach is riskier because you lose the reference value, but it simplifies the understanding as there is a single event time-related field; technically, the reference value should still be available at the data source level but often the sources won't follow the same lifecycle as the downstream parts of the system
Derived event time
If your data processing layer transforms the original event time into something else, for example by aggregating event times for an entity, action, or period, we can consider the new time value as a derived event time. It somehow represents the action time but doesn't relate anymore to the original context, such as click or IoT signal emission. Ultimately, you can also consider this time attribute as a simple business key property.
Next comes the delivery time. Unfortunately, it's not always present in the input data but it's important, especially for streaming and latency intensive systems. Having it set helps spot any data generation issues without a big effort. The detection is then a simple equation delivery time - event time. If the difference is bigger than the expected threshold, it means the data producer encountered some buffering issues.
The delivery time is different from the next term, the ingestion time. The ingestion time represents when a given record arrives at the storage while the delivery time represents the delivery action which can be for example an INSERT INTO command, or an API request. As you may guess, both don't need to be the same, especially if you consider network issues or throughput limitations on the database.
Once the data is correctly ingested, your data processing job can transform it. The time representing this action is called processing time. It's monotonically increasing value that, in case of retries, will be different for the same set of records. This difference is normal because remember, this value is tied to the processing layer. Therefore, any context change such as a retry, should be considered as a new time.
Leveraging time in monitoring - cheat sheet
Time in your dataset is not just a property. It's implied in establishing some important data observability metrics, just as you do for other attributes with data quality rules. For time, you can use the following equations:
- delivery time - event time = the result spots any local issue on the producer side, such as too high buffering time or software problems in promoting buffered records for delivery.
- processing time - ingestion time = the result detects data reading latency. For example, if your processing job is fighting with other consumers for the data, its reading throughput may be reduced leading to the increased reading latency.
- ingestion time - processing time = as the opposite of the previous equation, the result spots any writing issues that might be caused by an inefficient data transformation, slow network, or yet the output database too small for the volume of the written data.
- ingestion time - delivery time = this is a more precise result that isolates the data writing issues at the last stage of sending records to the output database. It can be a good measure to spot any sizing unbalances between data producers and the output databases, such as a producer writing 10 GB of data per minute to a database whose throughput is 1 GB per minute. Typically in that case, the writing time will be much higher than the data transformation time.
- delivery time - processing time = the result shows how long your business logic takes to process the data. It helps exclude a possible data delivery issues and measure the transformation part only.
- ingestion time - event time = the result stands for the overall latency between the event generation and its delivery to the consumers. You must be aware here of a risk for outliers in case the producer encounters some connectivity issues. For example, if a user takes a plane and needs to buffer its data for the flight duration, the difference between the event time and ingestion time will be [should be, at least!] higher than usually.
You can see, there are many possibilities to get useful feedback on how the whole system performs, from the raw data ingestion to the last data processing steps. But this promise doesn't come for free. It requires timestamping. That seems obvious but without adding time property in each of the steps, having end-to-end observability will be challenging. Even if it sounds simple, this action will involve many different teams and require more organizational skills than the technical ones to make it successful.
When it comes to adding this timestamp attribute at each stage, it depends on the technology and type of the timestamp. The event time is also a business attribute. Therefore, it'll be part of the payload. On the other hand, all remaining attributes are rather technical and they might not be significant for the end users such as data analysts or data scientists. For that reason you can:
- write them as metadata layer, e.g. with Apache Kafka headers
- implement a metadata structure in the input row, well isolated from the business attributes, such as {"attribute1": .., "metadata": {"ingestion_time_producer": ..}}
- leverage the data store directly, for example defaults for some columns that will set the value to the current time (CREATE TABLE ... col1 TIMESTAMP NOT NULL DEFAULT NOW()), or native property such as append time semantics in Apache Kafka
I hope you have no doubts about the utility of time attributes. They will make the performance monitoring much simpler and optimize your chances to deliver not only accurate, but also fresh data. However, the implementation might be challenging in some places, especially on IoT devices where updates are more complex than just downloading a new version from an application store.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩