
Feature stores are a more and more common topic in the data landscape and they have been in my backlog for several months already. Finally, I ended up writing the blog post and I really appreciated the learning experience! Even though it's a blog post from a data engineer perspective, so maybe without a deep data science deep dive.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Store for the features, but not only!
At first glance, understanding the need for a feature store may not be obvious. After all, the data (features) for training and prediction is always prepared beforehand. That's maybe true but becomes problematic at scale. Features, so these "little" attributes used by the models during training and inference steps drive the accuracy of the result. Things become complicated when they have to be shared among teams or used in offline and online predictions. The question for these scenarios is how to guarantee the use of the same set of features? And that's where the feature store shines. It provides a central and a single source of truth for the features. The definition is quite reductive because a feature store is much more than that! After all, to keep a single source of truth, you could create a "data-science" bucket and put all your feature data inside.
That's why the single source of truth is only one of the following set of features:
- feature engineering - this one my first astonishment. What's the link between feature engineering, which is more a data transformation task, and a feature store, so more a static concept? That's true and doesn't mean you will stop using Apache Spark or Pandas in feature engineering. Instead of replacing these libraries, you will connect them to the feature store SDK. So that they can be automatically stored after the feature engineering step.
- time travel is the second point characteristic for a feature store. In the previous point, you've learned that the feature engineering SDK can be used alongside Apache Spark or Pandas feature engineering jobs. But where to store these features? One of the storage types - you will see the second one later in this list - is an offline storage and one of its requirements is the support for time travel. So yes, you will find here new ACID-like file formats like Apache Hudi or Delta Lake, but also data warehouses supporting time travel like BigQuery.
- offline and online feature store backends - depending on the feature use cases, you can store it in offline or online storage, or both. I'm sure you already have the picture for the offline storage from the previous point. Yes, it'll be the storage adapted for batch jobs. The online storage will then be the opposite. The real-time prediction jobs will use it. It has to be then a more low-latency data store, like a Key-acess or a memory store.
Since these stores and data processing concepts may be a little bit abstract - or at least, they were for me while I was writing this article - you will find a great example of them in a code snippet shared by Jim Dowling from Hopsworks in his article about Feature stores for ML:
- serving is another component of a feature store. But it's not the models serving. It's the feature serving! It's there to prevent the training-serving skew where different features are used in training and serving parts, leading to weird situations when the model performs very well during the training and much worse at usage.
- monitoring - it's the one not related to the model monitoring but the features monitoring, and more exactly, to their data quality. Feature stores can also monitor the training-serving skew to detect problematic inconsistencies between training and prediction data.
- registry - the place where all features (data) but also their description (metadata) are available. It's particularly useful in the early stages of the new project because it helps other data scientists to discover, very often visually, already available features.
You can also consider the registry as a kind of Git log where data scientists can analyze the evolution of the features over time. Because yes, the features are living beings. They can evolve and use a better version of the generation algorithm or have some bug fixes integrated.
The metadata part of the registry provides the features description and the things you may already know from data engineering fields like data lineage. In this context, the lineage will apply to the feature versions used in the models.
Put another way, the feature store in a picture could look like that:
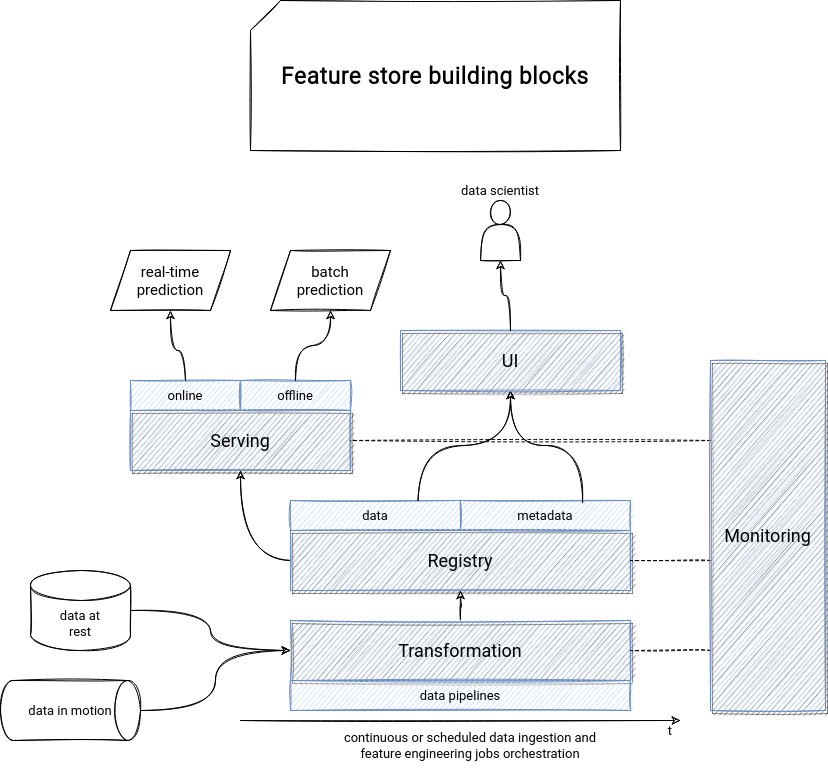
And here we are! But it's not the end because next week you'll see a feature store in action. See you then!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Feature stores - introduction here:
Related blog posts:
- On tests in data systems
- Alerts, guards, and data engineering
- Agnostic data alerts with ydata-profiling
Today I've broken my weekly "Apache Spark + cloud" blogging routine because the 2nd blog post of this week presents some basics about feature stores. The follow-up part is planned for the next week ? https://t.co/PXCjrjvO8p
— Bartosz Konieczny (@waitingforcode) June 27, 2021