
Last May I gave a talk about stream processing fallacies at Infoshare in Gdansk. Besides this speaking experience, I was also - and maybe among others - an attendee who enjoyed several talks in software and data engineering areas. I'm writing this blog post to remember them and why not, share the knowledge with you!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
My 25 Laws of Test Driven Development
It's one of the greatest Test-Driven Development (TDD) talks I've ever seen! Even though I'm not familiar at all with .NET, it was a great pleasure to listen to Dennis' words of wisdom. Very pragmatic talk where you will find several TDD truths:
- You shouldn't write unit tests before having any production code. Think about responsibilities, scope, and your production code. Only later use test cases to drive the organization. TDD is the design process.
- You can rely on the Dependency Inversion Principle to define the boundaries. Dennis gives a clear example where he shifts the order processing interface from the data to the domain layer, making it more concrete and functionally more relevant:

- The Don't Repeat Yourself (DRY) should be scoped within functional domains. It helps decoupling tests and domains from each other, leading to simpler tests writing.
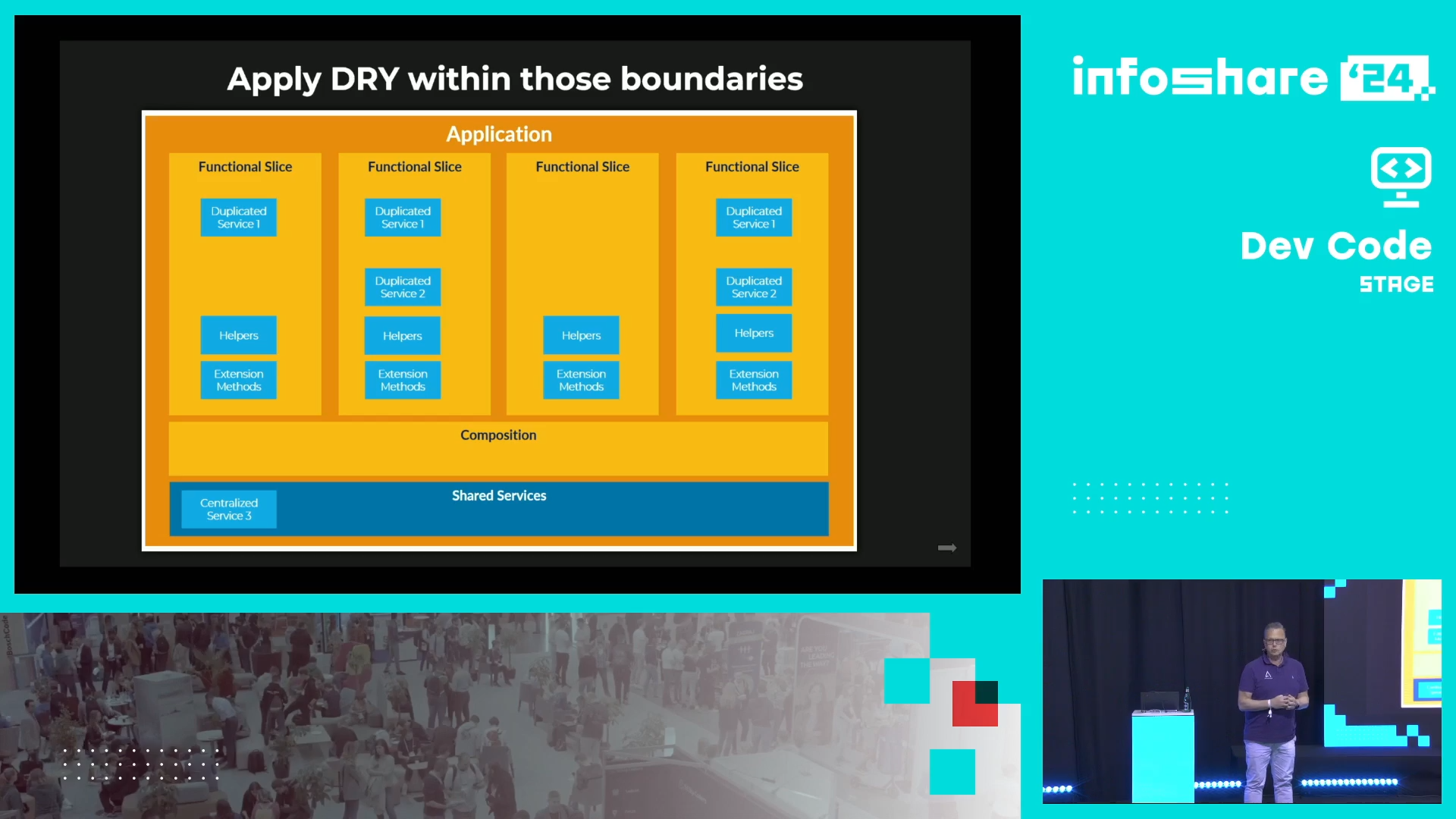
- Avoid doing the TDD by the book. Dennis shares the example of his Open Source testing library (Fluent Assertions) where multiple interfaces and classes, according to the "test all classes and functions" rule, should be tested. He recognized, it's like shooting yourself in the foot. He did it by the way. Instead, it's better to think about the "units" in terms of functional domains and sometimes, consider those domains as the testable units - and so even though they might encapsulate multiple functions or classes. That said, Dennis also mentions an important thing of not being dogmatic about this. Often it's also appropriate to test a function, class, even at its lowest level.

- Besides, don't argue what the "unit" is. Stay pragmatic and apply this definition to your context. A "unit" can be a class, function, or a broader functional domain.

- Test real things. If your clients interact with your code via an HTTP endpoint, test the HTTP endpoint and not the class behind it. The rule also applies to bringing real databases to the tests.
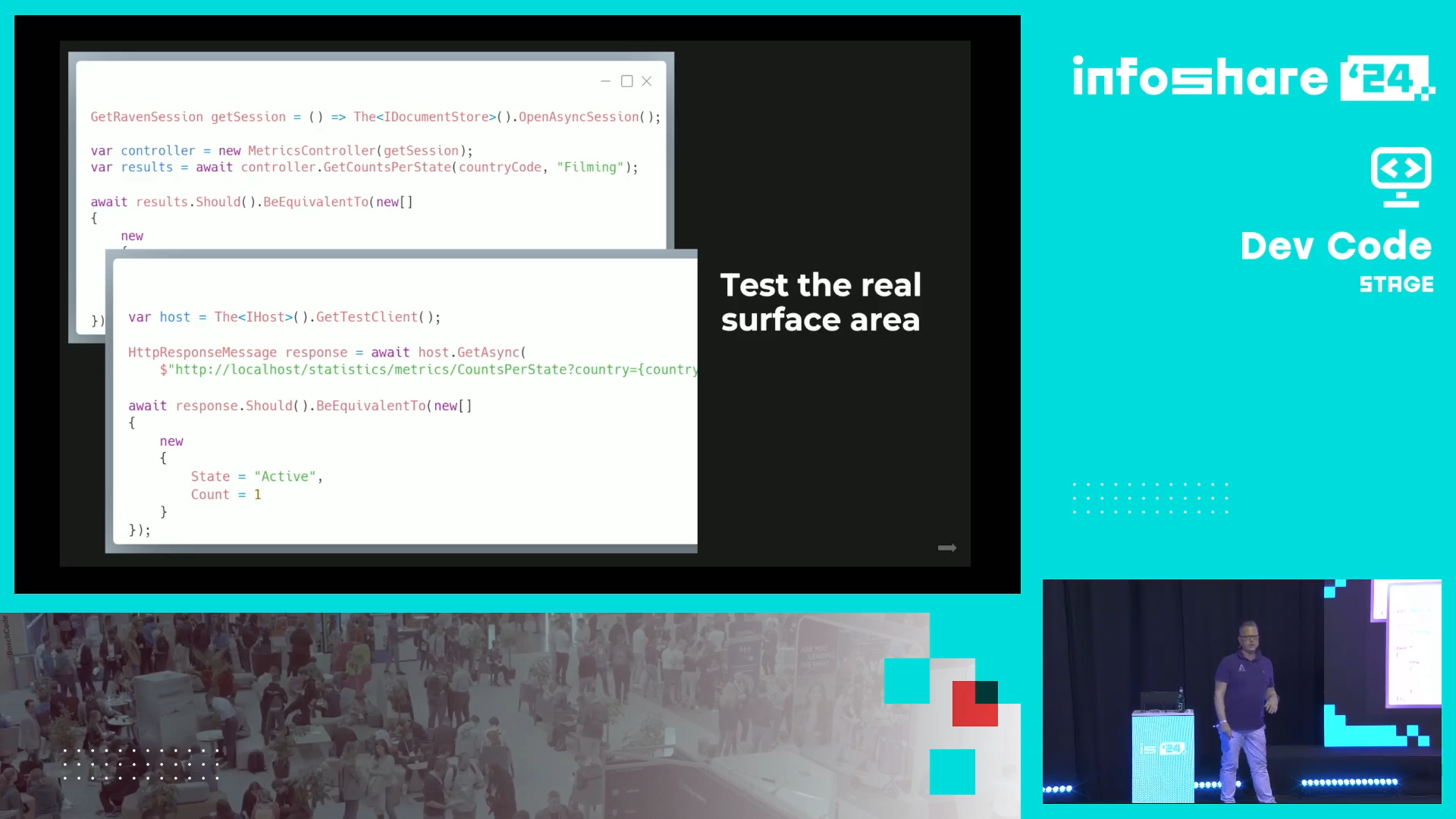
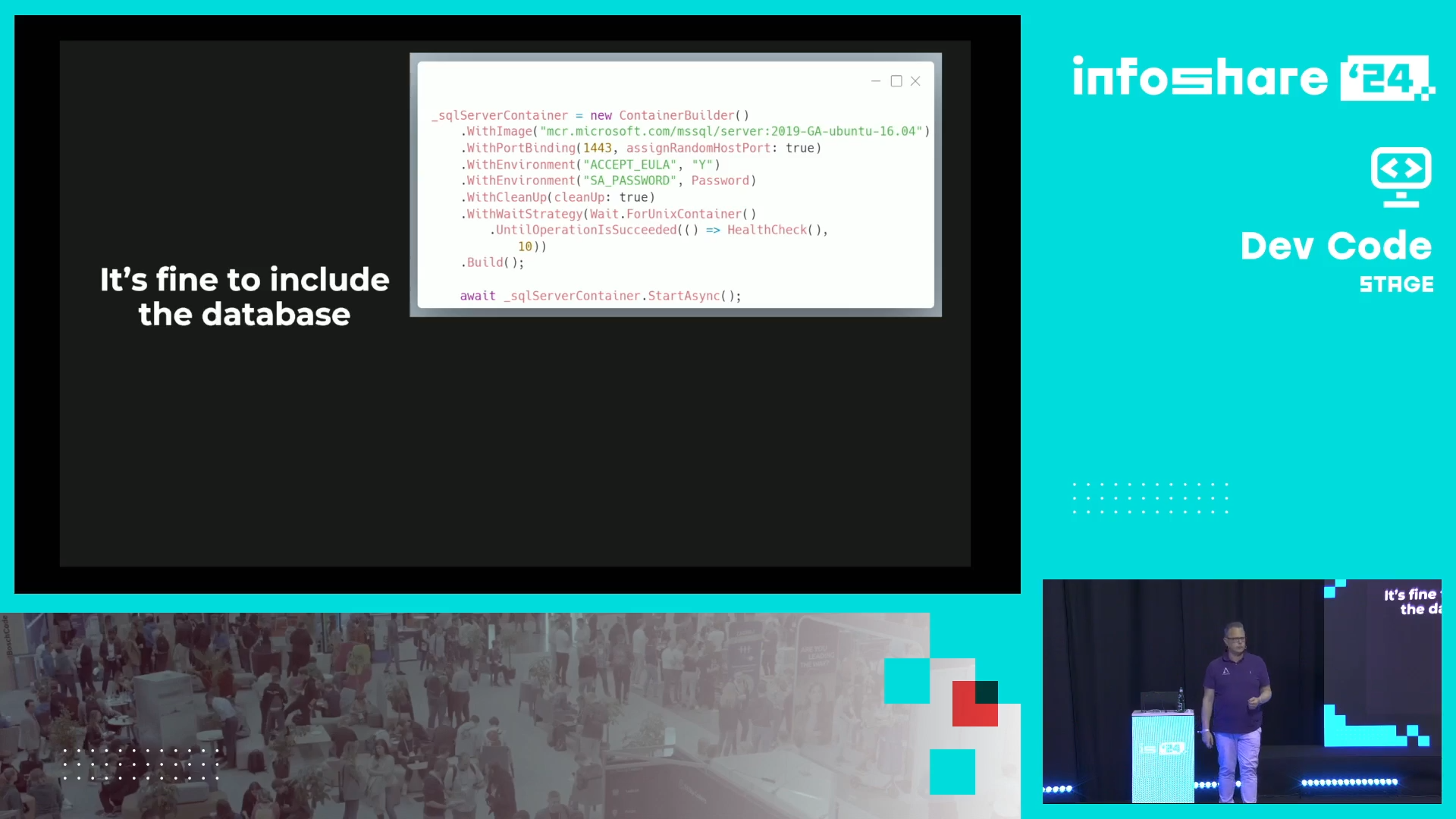
- Correctly implemented tests can be used as documentation. Dennis shares his experience of people asking questions on his test libraries. Whenever there is a new question, he goes to the test to check the expected behavior out.
- To keep the tests readable, you can forget about some of the production code practices. Dennis gives an example of using/not using magic numbers in the code. Although they might help make the production code more readable, they might also have an opposite effect on the test base as you would need to jump between test scenarios and constant definitions.

- Only assert what is relevant for the given test case to ensure the test fails for correct reasons.
- Golden rule for mocking: allowed outside boundaries, not inside.

🎬 Link to the talk: My 25 Laws of Test Driven Development.
🎬 Link to the speaker's LinkedIn: Dennis Doomen.
Organizational and technical solutions for tests
In the next talk test-driven talk from my list, Piotr shared some interesting tips about tests in software [hence data] projects:
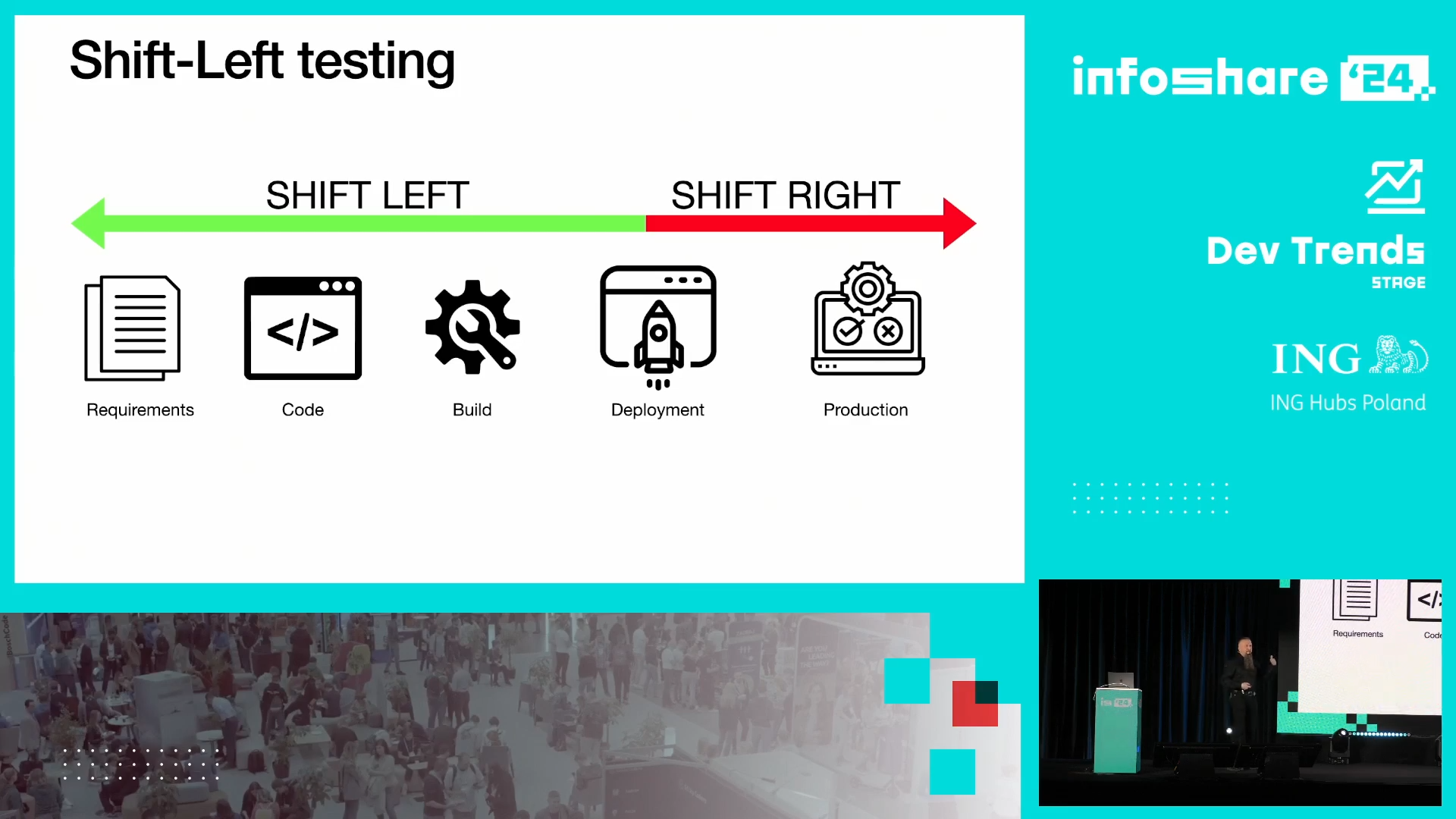
- Shift-left vs. Shift-right testing - elements on the left part of this diagram are cheap and fast to test. The rightmost are their opposite:
- External QA team can be problematic as the development team can be less concerned about the quality, leading to longer bug fixing. Alternatives here are: internal QA team that can even support the development team in defining acceptance tests, or no QA team at all, meaning that everyone in the team is responsible for the quality.
- Code coverage race - it's clear. If your bonus depends on the code coverage, it will always be high. But a high coverage doesn't mean the tests are relevant.
- Multiple test patterns - you've certainly heard about the Pyramid but there are some others:
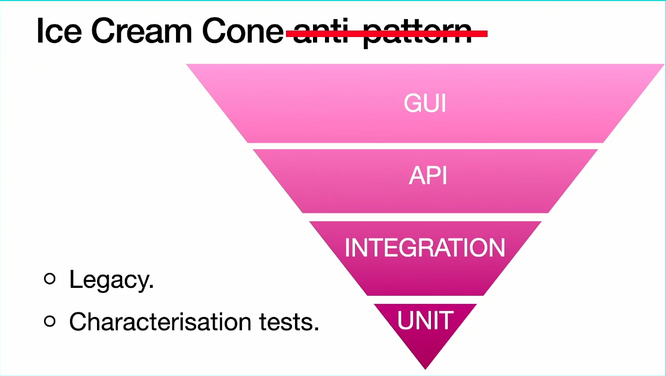
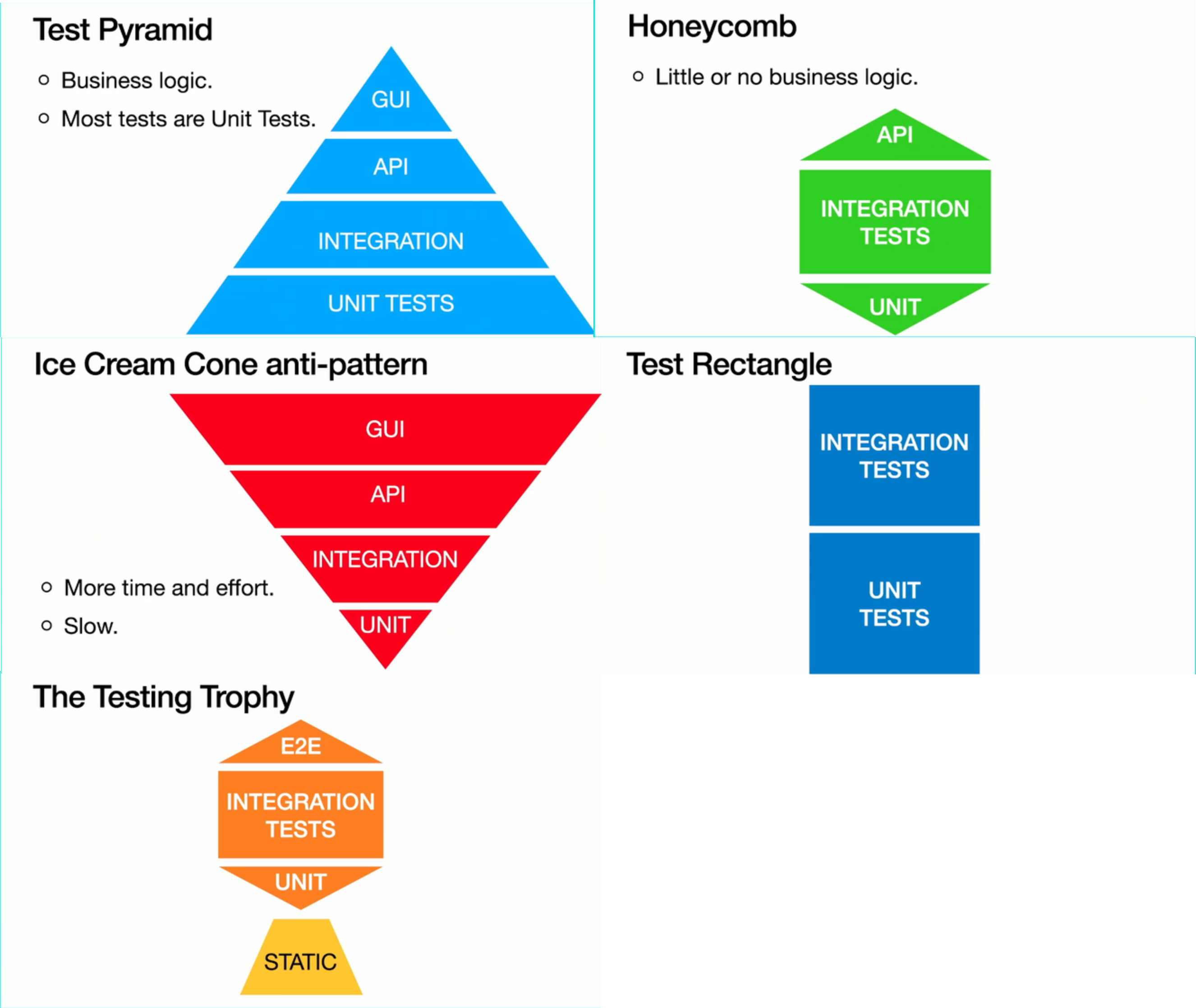 Surprisingly, the Cone anti-pattern can become a pattern under some project conditions:
Surprisingly, the Cone anti-pattern can become a pattern under some project conditions:
- Like Dennis, Piotr doesn't apply the "unit" from unit tests to a class, method or a function. Instead, he defines it in a more functional context:

- Trinity defines 3 ways for keeping the tests readable. The main idea is to rely on high-level abstractions to hide all verbose implementation details:
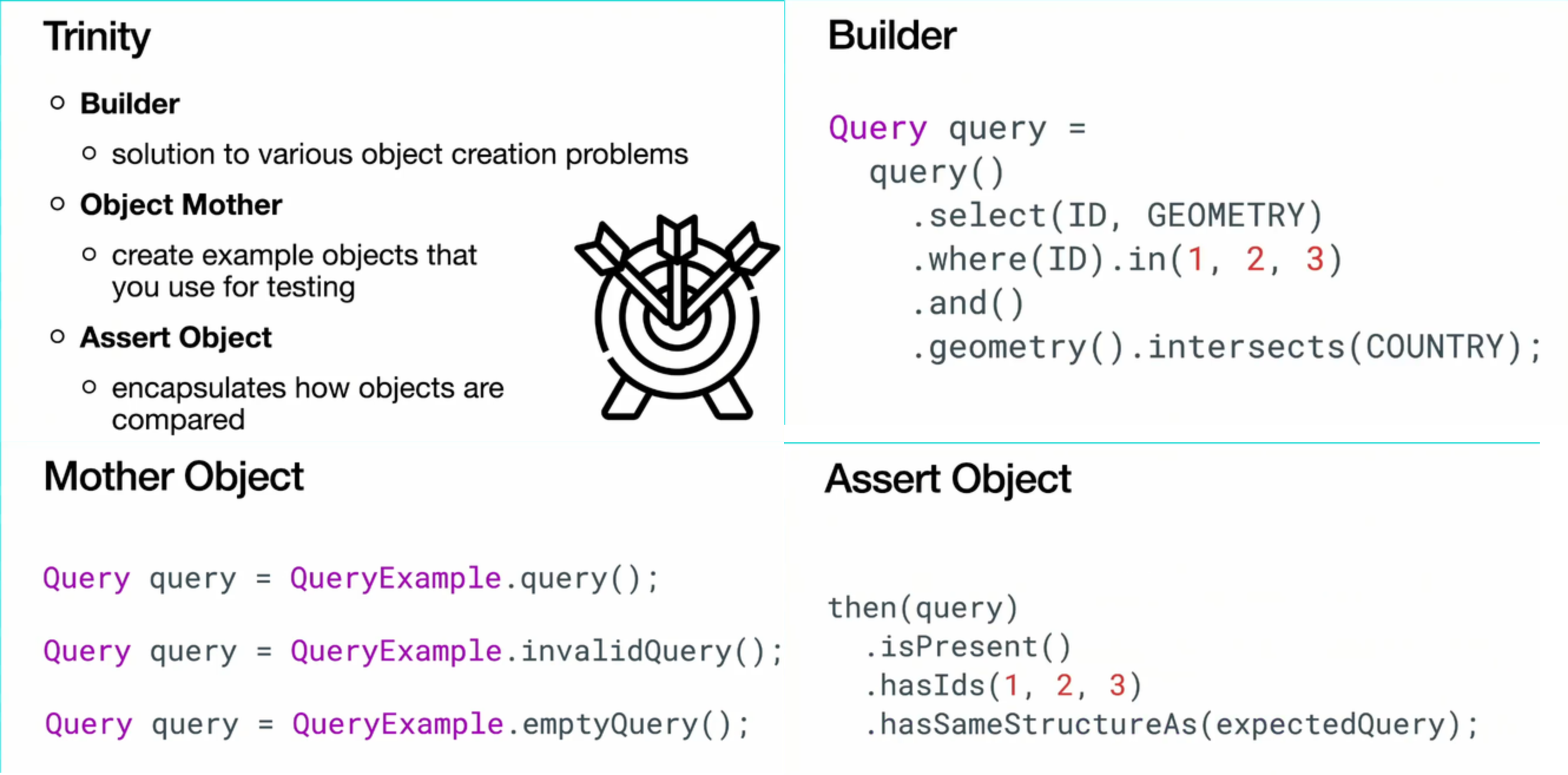
- If you start a greenfield project and you start by including the mocking library, it might be a sign of a wrong project design.
🎬 Link to the talk: Organizational and technical solutions for tests.
🎬 Link to the speaker's LinkedIn: Piotr Stawirej.
Journey to the cloud, or how we started building it ourselves
After these two test-related talks, I attended the one about cloud migration for a traditionally on-premise company. Greg shared not only what benefits has brought GCP to his organization, but also what concrete technical challenges he was able to solve thanks to the elastic computing capabilities:
- PoC without cloud foundation and commitment. It consisted of simply taking some data from the on-premise environment to the cloud, following the architecture from this slide:
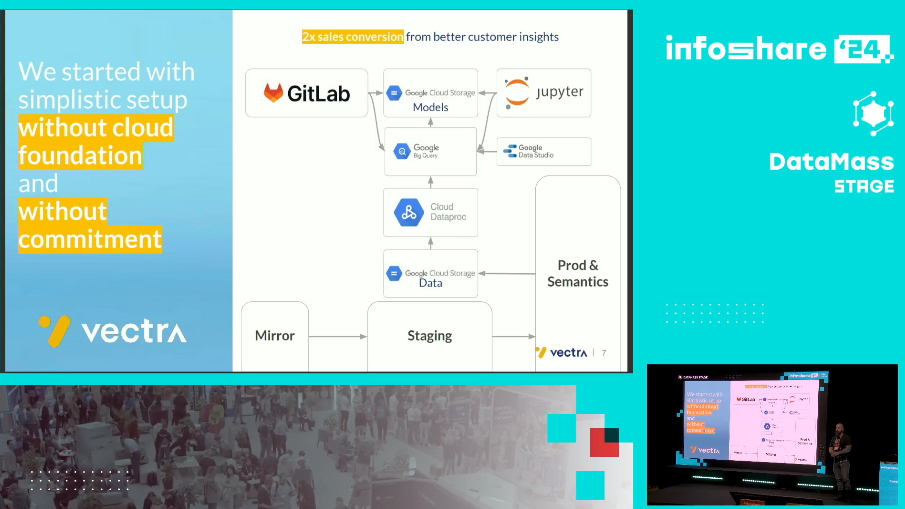
- Reducing time-to-insight from 3 weeks to 6 seconds for billions of events and thousands of files thanks to serverless and event-driven Cloud Functions. It includes integrating with other Google sources.
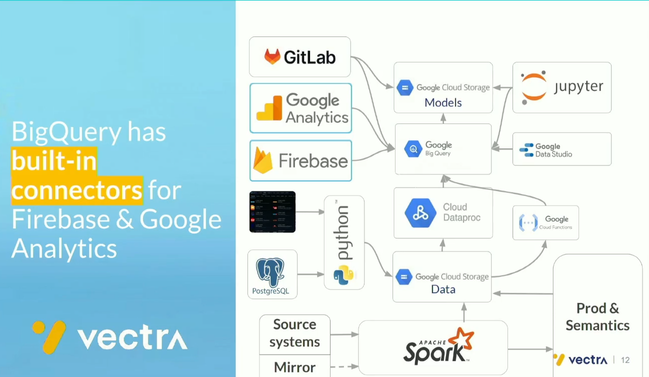
- Greg's team was one of the first Data Stream customers! Lessons learned are pretty positive except for an expensive post-processing step.
- Besides pure data aspects, the infrastructure also concerned the web services API layer. Here too, Greg shared some lessons learned:

🎬 Link to the talk: Journey to the cloud, or how we started building it ourselves.
🎬 Link to the speaker's LinkedIn: Grzegorz Gwoźdź.
Enhanced Enterprise Intelligence with your personal AI Data Copilot
Marek shared how he built an AI Data Copilot to support the work of analytic engineers, specifically targeting the dbt environment and SQL. It was a great example I was familiar with [who hasn't been using autocomplete in an IDE?] that showed steps required to build an LLM-based system, with all technologies and concepts involved. These two slides show it pretty clearly:

There are some important components involved:
- Vector search database contains the information about your data context, i.e. SQL queries, data models.
- There are two models. The first is the SQL LLM model that was trained on some SQL and dbt codebase. The second is the search model that communicates with the vector database to calculate some vector representation of the user's question and looks for the hints to provide to the SQL LLM. Thanks to these hints, the SQL LLM should be able to generate more relevant queries.
Next, Marek introduced the GID Data Copilot which is an extension to Visual Code for the existing SQL and dbt extensions and summarized the talk with the following conclusions:

🎬 Link to the talk: Enhanced Enterprise Intelligence with your personal AI Data Copilot.
🎬 Link to the speaker's LinkedIn: Marek Wiewiórka.
Optimising Apache Spark and SQL for improved performance
In his talk, Marcin shared a few optimization techniques for Apache Spark SQL jobs. All of them apply to Apache Spark 2 but some of them might have been optimized by engine changes in the 3rd release.
The first tip: data skew for a window function that calculates the next timestamp for each user. The solution was to replace the x-days processing by day-by-day processing, and use the UNION operator to combine events at the day's boundaries (otherwise you will get NULLs for those records). An Alternative to this split solution is to simply ignore skewed records if the non skewed ones can provide an insight good enough.
The second tip: be aware of the cartesian joins. It applies particularly to the self-joins. Marcin gives an example of an order table where the goal was to see all products bought together. A solution to that is salting, so adding some kind of randomness.
The third tip: lazy evaluation catch. If you transform the same DataFrame, for example, with some non deterministic transformations such as random columns, you'll get two different results each time. Marcin illustrates the issue with the following code:

🎬 Link to the talk: Optimising Apache Spark and SQL for improved performance.
🎬 Link to the speaker's LinkedIn: Marcin Szymaniuk.
Can we work differently? Straight way to the burn-out
In the last talk of my list, Ola Kunysz shared an interesting insight about burn-out. Lucky you if you have never felt it because according to the numbers from 2022 ("The State of Burnout in Tech" by Yerbo), 20% of IT workers have a high burn-out risk, 69% of IT female workers and 56% of male IT workers, are exhausted after a day of work. There is even worse, 56% of us can't relax at home because of work-related problems.
Thankfully, there is hope. Ola explains several signs and solutions you can apply to your daily routine to avoid a burn-out:
- "Death march in IT" - when you're working 150% of your capacities, hoping it'll end one day. How to recognize it? A clear sign is when you blame people who completed their tasks and left/disconnected before you. You, who are doing long hours.
- What are other energy vampires? Team spirit, personal conflict, useless meetings, different involvement in the project, and micro-management...
- Also our impact on the project may have some negative impact on our feelings, such as responsibility without being involved in the decision making, lack of time for upskilling while new tech is involved in the project, and finally wooling over your eyes, for example when people listen and nod to your comments but ignore implementing them.
Besides these dark sides, Ola also shares solutions that might be:
- walk, sport or other activity, such as gardening
- talking with someone
- better time management to find availability for learning new skills
- split big tasks into smaller ones to avoid being overwhelmed in case of any unexpected event
- always expect unexpected
- be responsible for your scope, you can't always "save the world"
- take breaks throughout the day
- celebrate even the smallest successes
- ask for feedback; some leaders assume that "no feedback" means positive feedback but it's always better to explicitly hear it
🎬 Link to the talk: Can we work differently? Straight way to the burn-out.
🎬 Link to the speaker's LinkedIn: Ola Kunysz.
Infoshare is the second conference I discovered after last year's Berlin Buzzwords and I'm very pleased about that! BTW, the retrospective for Berlin buzzwords 2024 is in my plans too :)
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Infoshare 2024 - Retrospective here:
Related blog posts:
- On tests in data systems
- Alerts, guards, and data engineering
- Agnostic data alerts with ydata-profiling