
Even though nowadays data processing frameworks and data stores have smart query planners, they don't take our responsibility to correctly design the job logic.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
One of the key factors in data engineering jobs is the order, the job-level and code-level.
Job-level
The first and the most visible optimization for the order-based optimization is the job itself. Remember the golden rule, reduce the data processing scope as early as you can. How? With filtering, obviously. Each filter expression should be as close to the filtered dataset as possible.
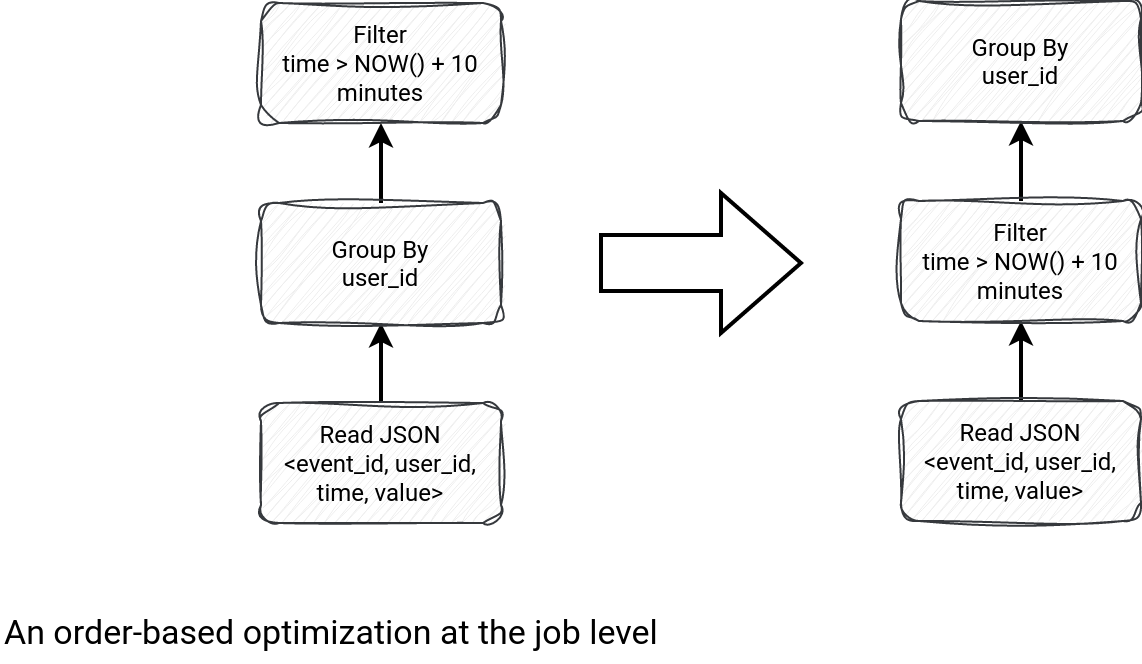
This query execution tree illustrates the idea. The leftmost graph reads events and groups them before filtering the data on the attribute that is natively present in the input dataset. The problem is that the group by involves network traffic and by applying the filter late, we even increase the network IO pressure. Possibly, many of the shuffled rows will be filtered out later. That's why it's better to do this filtering logic before.
Another example, a little less obvious though, is the local CPU- and memory-intensive computations. In Apache Spark Scala API you can cast the raw Row data representation into more meaningful and easier to manipulate case class:

From the snippet above you can see that Apache Spark optimized the second operation and collapsed the filtering operation. It can't really do that for the uppermost part because the framework cannot interpret this custom filter expression. The string-based one is converted into internally generated Java code:
/* 018 */ public boolean eval(InternalRow i) {
/* 019 */
/* 020 */ boolean isNull_0 = true;
/* 021 */ boolean value_0 = false;
/* 022 */ boolean isNull_1 = false;
/* 023 */ int value_1 = -1;
/* 024 */ if (2 == 0) {
/* 025 */ isNull_1 = true;
/* 026 */ } else {
/* 027 */ int value_2 = i.getInt(0);
/* 028 */
/* 029 */ value_1 = (int)(value_2 % 2);
/* 030 */ }
/* 031 */ if (!isNull_1) {
/* 032 */
/* 033 */
/* 034 */ isNull_0 = false; // resultCode could change nullability.
/* 035 */ value_0 = value_1 == 0;
/* 036 */
/* 037 */ }
/* 038 */ return !isNull_0 && value_0;
/* 039 */ }
/* 040 */
Code-level
The optimisations can be also made at a lower level, directly in the code you're writing. Here too you can take some shortcuts and very quickly improve the code quality. Let's take the code below as an example (I'm writing this without monads on purpose, it should be clearer for Python readers of the blog):
def getEventTimeFormattedAsDay(inputData: Map[String, String]): Option[String] = {
val maybeEventTime = inputData.get("event_time")
val dayFormat = DateTimeFormatter.ofPattern("yyyy-MM-dd")
if (maybeEventTime.isDefined) {
Some(maybeEventTime.get.format(dayFormat))
} else {
None
}
}
The code does the job but there is a problem with the DateTimeFormatter. Do you see it?
If your concern was the object creation, you were right. The formatter is initialized every time, even if there is no event_time in the input map! So to start, initialize things only when necessary. It may not be a big deal here but if this object had some I/O-involved actions, like opening a network connection to a database, you should see the impact on the performance at scale.
Another point is about the number of created objects. The DateTimeFormatter is thread-safe meaning that we could create a unique instance of it and call from various threads. Again, here it's just a text formatter but if the initialization is costly, it may be worth having this single shared instance.
Although it concerns the low-level part of the jobs, the principle is the same. Do something only if it's necessary and do this closely to the user. The latter, besides the performance impact, also improves the code readability because the related things live close to each other.
All this to say, the order helps not only in daily life but also in data engineering!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩