
Because of its connected nature, graph structure has its own branch in data mining. Thanks to this branch we can get insight into relationships and dependencies between vertices.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post focuses on graph mining. Its first section defines the concept. The second one presents a framework dedicated to graph mining in the context of Big Data. The last part contains several examples using the framework.
Definition
First and foremost please notice that graph mining is used interchangeably with graph analysis but we prefer here this first option because of its stronger relationship to data mining. Hence, data mining is a set of analytic techniques those results is an information or a knowledge created from the analyzed graph. The mining process consists of finding user-defined patterns extracting subgraphs.
Working with graph mining at scale is not an easy task because the set of possible patterns and their subgraphs in a graph can be exponential in the size of the original graph. In this context, we talk about big graph mining phenomena where the size of the stored graph only increases.
But the topic of Big Data and graph mining will be covered in the next part with Arabesque. Before going there, we must discover the main graph mining problem classes:
- finding frequent patterns - it explores the graph and returns the patterns present at least n times. This parameter is, alongside with the graph to analyse, passed in the input and it's often set by trial and error method. If it's too low, too many patterns will be returned. If it's too high, maybe none of them will be found. The following image shows an example of frequent pattern matching in a graph:
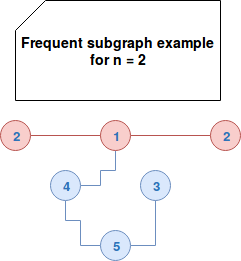
As you can see here, we matched 2 frequent subgraphs: (2) and (2)---(1). - finding cliques - a clique is a subgraph where all vertices are connected to each other. The cliques are marked in red and blue in the following image:
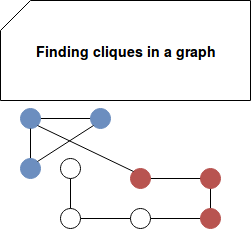
- counting motifs - this class of problems focuses on finding motifs with their frequency in the graph. A motif is considered as a connection of k vertices. For instance, a motif of 3 vertices may be a triangle, as illustrated below:
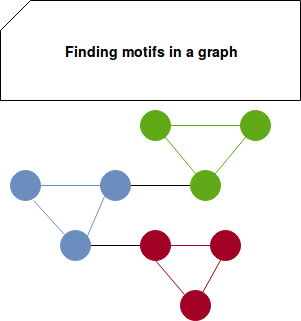
Arabesque
Until now we've discovered "Think Like a Vertex" and "Think Like a Subgraph" computation paradigms but Arabesque comes with its own "Think Like an Embedding" one. The embedding is considered here as a subgraph with a set of vertices and edges of the analyzed graph.
Arabesque is a library initially built on top of Apache Giraph. However, it doesn't use its vertex-centric model. Giraph is only used as an abstraction managing the distributed computing (workers synchronization, partitions balancing etc.). Meantime Apache Spark was added as another runtime environment. Thanks to them Arabesque is able to distribute the work and to deal with graph mining at scale.
According to the test made in the Arabesque paper quoted in the "Read also" section, TLV computation model performance suffers from the communication overhead. Compared with TLE execution model, TLV was 2 times slower. TLE also is different from another approach called Think like a Pattern. The difference consists of the persisted intermediate state. TLP stores all patterns but it can have a negative impact on load balancing. If the load is partitioned by patterns, then the partitions with popular patterns can become hotspots. Instead, Arabesque stores the set of embeddings from the previous step as compact Overapproximating Directed Acyclic Graphs (ODAG).
The computation model follows a sequence of exploration steps (the execution steps are in fact BSP's supersteps). The user specifies an input data set alongside with 2 functions: filter and process. The algorithms start by defining a set of candidate embeddings that are later passed to filter function. If the value is not discarded, it goes to the process function. Here the embedding is transformed to some of the user-defined values and appended to the output set. Once all candidate items are filtered and processed, the output set is transformed into the input set of the next exploration step. The computation ends when the output set is empty.
The distributed execution consists of dividing input set and assigning the partitions to worker machines transparently. Workers receive load balanced work thanks to round-robin partitioning strategy. The partitioning unit is not here an embedding but rather a set of them called block. Their distribution is based on the cost assigned to each of input arrays.
Arabesque example
In this section for the sake of simplicity I'll use Arabesque Spark connector because it can be executed directly from IDE, without the need to install any extra environment. As a first test I wanted to see what is this famous embedding iteration (all tests were added to SparkArabesqueSuite):
// Input graph file:
// 0 1 1
// 1 1 2
// 2 1 1
// In image: (0)-(1)-(2)
test("should print embeddings") {
val traversal = arabGraph
.vertexInducedComputation { (embedding, computation) =>
println(s"get embedding = ${embedding.getVertices} ${embedding.getPattern} and c=${computation.toString}")
computation.output(embedding)
}
.withShouldExpand ((embedding, computation) => true)
.withFilter ((embedding, computation) => true)
val embeddings = traversal.embeddings.collect().map(embedding => embedding.words.sorted.mkString(","))
assert(embeddings.size == 6)
assert(embeddings.contains("0"))
assert(embeddings.contains("1"))
assert(embeddings.contains("2"))
assert(embeddings.contains("0,1"))
assert(embeddings.contains("0,1,2"))
assert(embeddings.contains("1,2"))
}
Two interesting things. First, the embedding accumulates vertices. The vertexInducedComputation is called on each produced embedding and the computation is the processing logic. Here, since we want to know the traversal, we output everything. Two other builder methods serve to check whether the traversed graph should continue and whether given embedding should be discarded before the next step. Let's now rewrite previous test and accept only the path composed of 3 vertices:
// Input graph
// 0 1 1 3
// 1 1 2
// 2 1 1 1
// 3 1 4
// 4 1 5
// 5 1
// In image: (0)-(1)-(2); (0)-(3)-(4)-(5)
test("should return triplets") {
val traversal = arabGraph
.vertexInducedComputation { (embedding, computation) =>
if (embedding.getNumWords == 3) {
computation.output(embedding)
}
}
.withShouldExpand ((embedding, computation) => embedding.getNumWords < 3)
.withFilter ((embedding, computation) => embedding.getNumWords < 4)
val embeddings = traversal.embeddings.collect().map(embedding => embedding.words.sorted.mkString(","))
assert(embeddings.size == 4)
assert(embeddings.contains("0,3,4"))
assert(embeddings.contains("3,4,5"))
assert(embeddings.contains("0,1,3"))
assert(embeddings.contains("0,1,2"))
}
As you can see, all paths with 3 vertices were correctly returned. This time we stop the exploration after finding 3 consecutive vertices. That example was also quite simple. A more complicated one could be the one finding the triangles. Fortunately, Arabesque provides the implementation for this problem with io.arabesque.gmlib.triangles.CountingTrianglesComputation class:
// Input graph
// 0 1 1 2
// 1 1 0 2
// 2 1 0 1 3 4
// 3 1 4
// 4 1
// In image:
// (0)-(1)
// \ /
// (2)-(3)
// \ /
// (4)
test("should find triangles") {
val triangles = arabGraph.triangles().aggregation("output")
assert(triangles.size == 5)
assert(triangles.mkString(", ") == "0 -> 1, 1 -> 1, 2 -> 2, 3 -> 1, 4 -> 1")
}
Graph meaning consists of transforming subgraphs into valuable knowledge. However, this task is complicated in the context of Big Data because of the size of matched patterns. Arabesque is one of the frameworks created to address that size problem. It uses a concept called Think Like an Embedding and is based on the distributed model of Apache Spark or Apache Giraph. Despite that, it doesn't use vertex nor edge-centric computation model. Its main processing unit is the embedding. The framework addresses a lot of common graph mining problems, such as finding cliques, triangles or custom patterns. It does that with built-in frameworks and provided abstractions helping to implement custom processing.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Graph mining here:
- A Review of Big Graph Mining Research Big Graph Mining: Frameworks and Techniques Mining graph patterns An introduction to frequent subgraph mining Arabesque: A System for Distributed Graph Mining
Related blog posts:
- Bipartite graph recommendation example
- Chaos in streaming graph processing
- Graph processing frameworks survey
#graph mining is a #data mining version for getting the insights from the graphs. In today’s post I present 3 main problem classes and an illustration code using Arabesque framework: https://t.co/DAwyRocl7G
— Bartosz Konieczny (@waitingforcode) November 14, 2018