
Some time ago I wrote a post about the graph data processing with streams. That article was based on X-Stream framework proposed by the searchers of EPFL research institute. At this occasion, I also mentioned the existence of newer alternative for X-Stream, adapted for distributed workloads, called Chaos. I voluntary omitted the explanation of Chaos in the previous post. Putting it aside of X-Stream would introduce too many new concepts. But now, after some weeks of graph processing discoveries, I would like to return to the successor of X-Stream and present it more in details.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The first part of this post places the Chaos in the context of stream graph processing. The second one presents some implementation details. The third part shows how it could be implemented with serverless architecture on top of AWS.
X-Stream and Chaos
Just a quick reminder, the X-Stream's goal was to process the graph in a sequential manner, in a single machine. However, the distributed computing gained popularity and some novel approaches to deal with graphs appeared. And Chaos is one of them.
Unlike X-Stream, Chaos is a fully distributed system. Even though it takes some concepts defined by its predecessor as partitions and sequential access, it also introduces some new ideas. First, it ignores the data locality. Instead, Chaos assumes that the network bandwidth is at least as good as the storage bandwidth. Because of that, it doesn't take care of the data locality. Chaos also brings a point related to data distribution. Chaos tries to distribute the data to process uniformly and randomly across cluster nodes. And finally, the framework introduces the idea of work stealing consisting of stealing partitions to process from other nodes in order to achieve better performance.
Hence, Chaos is a fully distributed and horizontally scalable solution that can be used in the case of really big graphs. In the article quoted in "Read also" section the EPFL's researchers were able to process the graph of trillion of edges (16 TB of data) in a small commodity cluster.
Chaos implementation
Chaos is a distributed system composed of 2 main layers, storage and computation. Both are located on every node in the cluster. The storage engine is responsible for holding all data and serving it when the computation engine needs it. Among the stored data you will find vertices, edges and any intermediate data generated at each computation stage. All of them are partitioned and spread in a random and uniform manner across the cluster. Hence, exactly as for the X-Stream case, the data is grouped in different partitions. Inside the partitions the data is represented as chunks. They are the main unit of parallelism and of work stealing detailed further in this post.
The computation engine is responsible for the execution of the data processing logic. It uses an edge-centric simplified Gather-Apply-Scatter model. The computation is represented as a sequence of steps consisting of loading data to process, generating updates based on that data and writing it back for the final aggregation and update. In a schema we could represent it as follows:
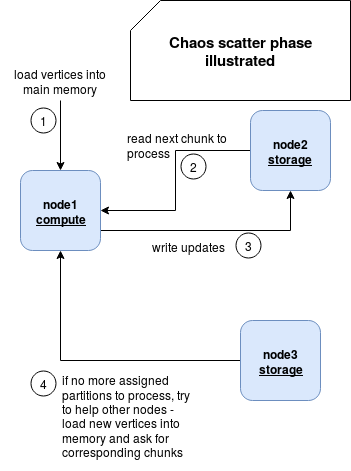
As you can see, the computation engine has a subset of the assigned fixed partitions and it operates only on them. First, it loads all corresponding vertices to process. It's assumed that they fit into the main memory of the nod Later it gets the edges chunks of one partition at a time and applies the data processing logic on them. After that, it writes the results back to the same storage. That's generally the Scatter phase. In the next stage called Gather, all generated updates for vertices stored in the given machine are collected and merged into a final new vertex value. Both stages are separated by a barrier and it could add some extra latency if one of the nodes would process the data slowly.
But the latency won't be added because the nodes performing their work much better can stole work of other nodes. Every time when a node terminates its local execution of the scatter or gather step, it asks the master node whether there are some other nodes needing help. If it's the case, it does what it did before, namely loads vertices of stolen partition into the memory and processes the remaining edges. The guarantee that given partition's chunk is processed exactly once is left to the storage engine. Therefore, the storage engine does not only distribute the data to process but also assigns the processsed chunks to the computation engines. By the way, the work stealing property justifies why Chaos doesn't look for a perfectly balanced local (= storage and compute engines on the same node) partitioning. As stated in the paper, "the vertices, edges and updates of a partition are uniformly randomly spread over the different storage engines". With the work stealing any potential partitioning weakness can be then caught up.
To sum-up, the pseudocode representing above tellings looks like in the following listing taken from the "Chaos: Scale-out Graph processing from Secondary Storage" article:
// Scatter for partition P
exec_scatter(P)
for each e in unprocessed Edges(P)
u = Scatter(e)
add u to Updates(partition(u.dst))
// Gather for partition P
exec_gather(P)
for each u in unprocessed Updates(P)
Gather(u)
// Pre-processing
for each input edge e
Add e to Edges(partition(e.src))
// Main loop
while not done
// Scatter phase
for each of my partitions P
load Vertices(P)
exec_scatter(P)
// When done with my partitions, steal from others
for every other partition P_Stolen
if need_help(Master(P_Stolen))
load Vertices(P_Stolen)
exec_scatter(P_Stolen)
global_barrier()
// Gather Phase
for each of my partitions P
load Vertices(P)
exec_gather(P)
// Apply Phase
for all stealers
accumulators = get_accums(P)
for all v in Vertices(P)
v.value = Apply(v.value, accumulators(v))
delete Updates(P)
// When done with my partitions, steal from others
for every other partition P_Stolen
if need_help(Master(P_Stolen))
load Vertices(P_Stolen)
exec_gather(P_Stolen)
wait for get_accums(P_Stolen)
global_barrier()
The above snippet is quite important because it explains why we need to load all vertices into the main memory. As you can see, each vertex has a property called accumulator where it stores the updated values. In the end, at the gather stage, all accumulated values are merged into the final new vertex value.
Chaos with AWS services
Unlike usually, this time I won't try to implement the Chaos with Open Source technologies - I did this exercise in the streaming and graph processing post. Instead, I will try to implement Chaos in event-driven serverless architecture with the use of AWS cloud services. The requirements for this "exercise" implementation are:
- ability to steal the work of other workers
- ability to read data chunks
- ability to block the execution at the end of each stage (scatter and gather)
- ability to launch iterative executions
- ability to implement process in serverless
Since fully serverless architecture involves the use of plenty of small services with isolated responsibility, I'll split the proposal into 2 parts: scatter and gather. Let's start with the scatter one:
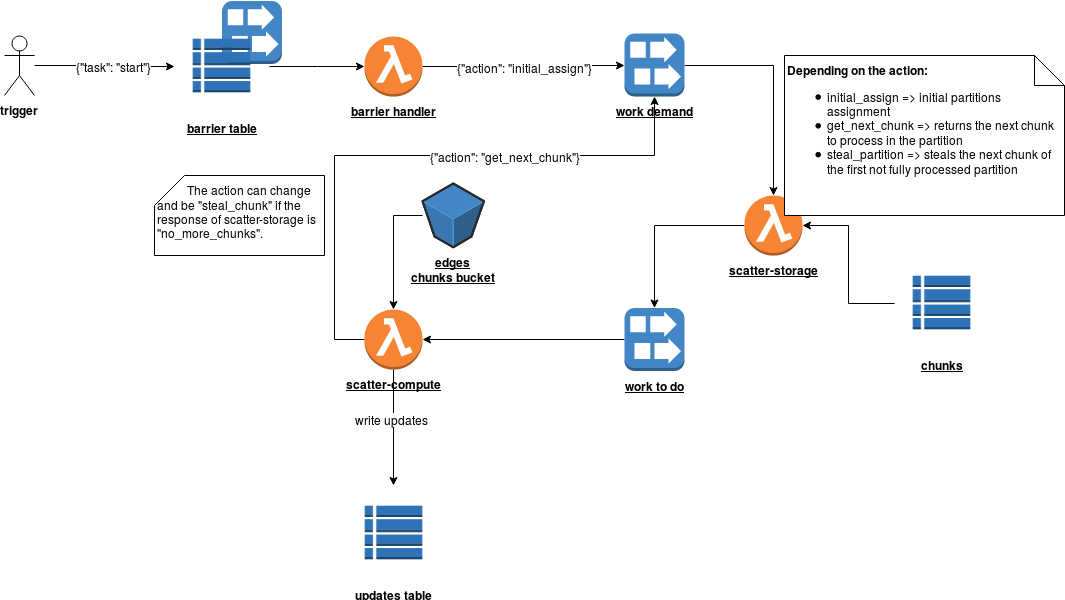
The iteration starts with the trigger message sent to a DynamoDB table called barrier table. This table exposes a DynamoDB stream that is consumed by the Lambda function called barrier handler. Its role consists of beginning the new iteration of the computation. When invoked, it always sends a message to the Kinesis stream called work demand. The message is intercepted by scatter-storage Lambda that reads the starting chunks to process for X scatter-compute lambda. This number is deterministic and it depends on the number of shards in the Kinesis stream. Storage function sends a JSON message to work to do stream, always partitioned in the same way. This message is later read by scatter-compute. This function reads the data to process from an S3 bucket and writes the updates to a DynamoDB table. At the end it also sends a message to work demand stream to mark its activity.
Internally this part works thanks to some assumptions. The work-demand stream has always 1 shard. In that way we always have one storage function able to retrieve chunks in not concurrent manner. Another important property is the writing of updates in the case of work stealing. In order to avoid writing conflicts, the compute Lambda makes the update request by adding a random column with accumulated values for given vertex:
# for each destination vertex in loaded_edges list: updates = generate_updates(processed_vertex, loaded_edges) update_message = Update(partition_key=vertex.id, generate_random_column_name(edge)=updates.value) update_dynamodb_table(update_message)
No local vertices loading
The serverless-based solution can't load vertices into the main memory because the memory lifecycle depends on the Lambda's execution and the latter happens only at every new event. Hence, we can't have a long-running Lambda. But instead of reading all vertices, we'll find the vertices to update among loaded edges and compute the partial updates from them. Eventually, we could also read the most recent vertex value in a DynamoDB table or ElasticCache but for sake of simplicity it's not present in the schema.
As told, each partial aggregate is written with the name of the new column as an update request. Thanks to that we get rid of the synchronization need in the case of concurrent processing of different edges belonging to the same vertex.
The gather part looks like:
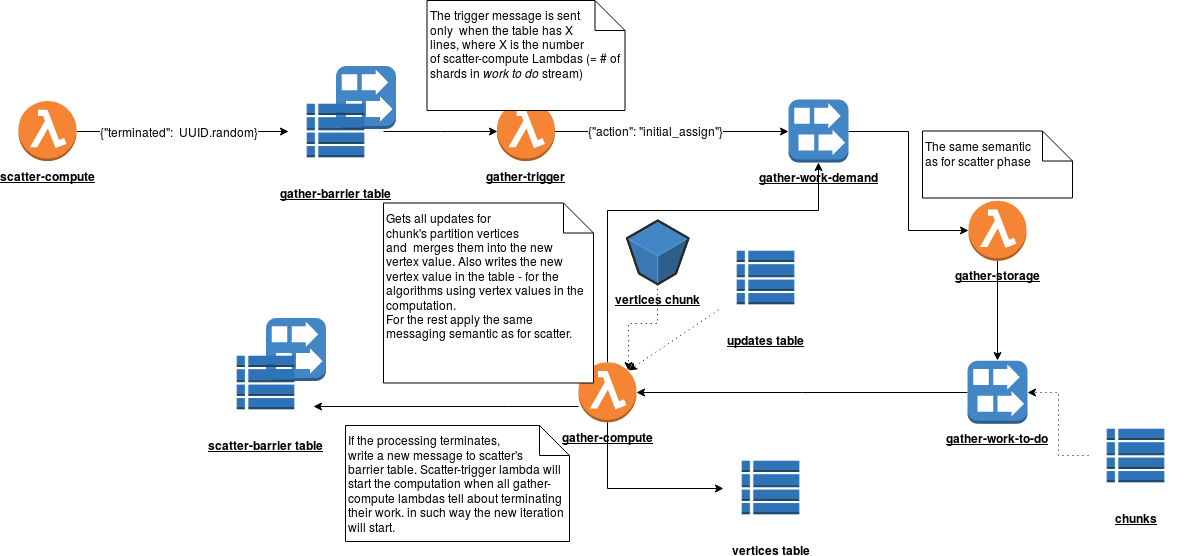
As you can see, the architecture is similar to the previous one. Also, we're waiting for a trigger condition to be met. This condition is met when all scatter-compute Lambdas write a line in the barrier table. Once the condition is met, the gather-trigger Lambda triggers the partitions initial assignment and deletes the rows from the table. The order does matter because we can eventually handle the assignment message twice (or add a logic to not execute it twice) but we can't lose the event. And it could happen if we would remove the rows before sending messages to Kinesis. The next loop is exactly the same - compute Lambda asks storage one for chunks to process. At every new chunk gather-compute function retrieves the vertices to process from an S3 bucket. For each vertex, it retrieves all updates from randomly created columns and computes the new value at once. The value is later stored in a table with vertex id and its most recent value. Of course, you should ensure that this function is fault-tolerant and doesn't generate fake results at retries. When the compute function has no messages to process, it writes a line into barrier table. When all gather lambdas did their job, the new scatter phase can start.
Chaos is the successor of X-Stream graph processing framework. Both are edge-centric solutions preferring sequential data access. However, Chaos is designed to work in a distributed environment. As highlighted in the second part, it's based on 3 principles: uniformly and randomly distributed partitions, 2 different engines responsible for 1 thing (storage or compute), and Gather-Apply-Scatter computation model. Even though Chaos was designed to classical master-slave architectures, we can also try to represent it in serverless mode. It was the goal of the exercise described in the 3rd section of the post. As we could see, thanks to clear Chaos design concepts, we can pretty easily isolate the components and with some extra effort provide the event-driven orchestration pipeline.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Chaos in streaming graph processing here:
Related blog posts:
Some time ago I wrote a post about X-Stream, a streaming approach to process #graph data. Today I published a follow-up post about Chaos, the X-Stream distributed successor with a simple implementation using #aws services: https://t.co/0vpgYdGcha
— Bartosz Konieczny (@waitingforcode) February 20, 2019