
Apache Spark uses a common data abstraction for all its higher level data structures. This implementation rule isn't different for GraphX represented by the sets of specialized versions of RDDs.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This second post in Apache Spark GraphX category focuses on the graphs representation. It's divided into 3 sections. Each one talks about a characteristic point of Graph representation. The first one emphasizes the general parts. The second one talks about triplets while the last covers all remaining points.
Graph
Technically the graph in GraphX library is represented by the implementation of abstract class called...org.apache.spark.graphx.Graph. It's single implementation is GraphImpl. The created graph is under-the-hood represented by the RDDs of vertices (VertexRDD) and edges (EdgeRDD). So created graph is a directed property graph:
private def graph = {
val vertices = TestSparkContext.parallelize(
Seq((1L, Friend("A", 20)), (2L, Friend("B", 21)), (3L, Friend("C", 22)))
)
val edges = TestSparkContext.parallelize(
Seq(Edge(1L, 2L, RelationshipAttributes(0L, 1)), Edge(1L, 3L, RelationshipAttributes(0L, 0)))
)
Graph(vertices, edges)
}
case class Friend(name: String, age: Int)
case class RelationshipAttributes(creationTime: Long, maturityLevel: Int) {
val attrs = s"creationTime: ${creationTime}, maturityLevel: ${maturityLevel}"
}
private def stringifyEdge(edge: Edge[RelationshipAttributes]): String = {
s"(${edge.srcId})-[${edge.attr.printableAttrs}]->(${edge.dstId})"
}
private def stringifyEdges(edges: Array[Edge[RelationshipAttributes]]): String = {
edges.map(edge => stringifyEdge(edge)).mkString(" / ")
}
it should "be a directed property graph" in {
val incomingEdges = graph.collectEdges(EdgeDirection.In).collect().map {
case (vertexId, edges) => stringifyEdges(edges)
}
incomingEdges should have size 2
incomingEdges should contain allOf("(1)-[creationTime: 0, maturityLevel: 1]->(2)",
"(1)-[creationTime: 0, maturityLevel: 0]->(3)")
}
it should "reverse edges direction" in {
val incomingEdges = graph.reverse.collectEdges(EdgeDirection.In).collect().map {
case (vertexId, edges) => stringifyEdges(edges)
}
incomingEdges should have size 1
incomingEdges(0) shouldEqual "(2)-[creationTime: 0, maturityLevel: 1]->(1) / (3)-[creationTime: 0, maturityLevel: 0]->(1)"
}
The above 2 test cases prove the directional character of the graph. The contrast is pretty well visible after applying .reverse operation on the input graph. This transformation changes the direction of the edges and produces a completely different graph than the input one. By the way, as for RDDs, the Graphs are immutable and every action creates a new instance of it:
it should "mutate and create new instance" in {
val sourceGraph = graph
val mappedGraph = sourceGraph.mapVertices {
case (vertexId, friend) => (vertexId, friend.name)
}
sourceGraph should not equal mappedGraph
}
Internally GraphX module optimizes as many things as possible and reuses some of the unchanged attributes, indices or structures from previous VertexRDD and EdgeRDD. But it doesn't happen in all the cases, for instance in the direct transformations on the vertices or edges:
it should "reverse the graph but keep underlying VertexRDD unchanged" in {
val sourceGraph = graph
sourceGraph.vertices.foreach {
case (vertexId, vertex) => InstancesStore.addHashCode(vertex.hashCode())
}
val reversedGraph = sourceGraph.reverse
reversedGraph.vertices.foreach {
case (vertexId, vertex) => InstancesStore.addHashCode(vertex.hashCode())
}
sourceGraph should not equal reversedGraph
// Even if both RDDs are not the same, they both store the same objects - you can
// see that in hashCodes set that has always 3 elements
sourceGraph.vertices should not equal reversedGraph.vertices
InstancesStore.hashCodes should have size 3
}
it should "map the vertices and change the underlying VertexRDD" in {
val sourceGraph = graph
sourceGraph.vertices.foreach {
case (vertexId, vertex) => InstancesStore.addHashCode(vertex.hashCode())
}
val mappedGraph = sourceGraph.mapVertices {
case (vertexId, vertex) => (vertexId, vertex)
}
mappedGraph.vertices.foreach {
case (vertexId, vertex) => InstancesStore.addHashCode(vertex.hashCode())
}
sourceGraph should not equal mappedGraph
sourceGraph.vertices should not equal mappedGraph.vertices
InstancesStore.hashCodes should have size 6
}
Triplets
During the tests we could see the Graph returning either underlying edges or vertices. But it exposes the third data type called triplets. What is the difference between it and VertexRDD and EdgeRDD ? Triplets field returns the whole connection between one node and its neighbor. The "whole" means here that we can retrieve not only the ids of vertices and the properties of the edge, but also all the attributes of both vertices:
it should "expose: vertices, edges and triplets" in {
val sourceGraph = graph
val mappedVertices = sourceGraph.vertices.map {
case (vertexId, friend) => s"name: ${friend.name}, age: ${friend.age}"
}.collect()
val mappedEdges = sourceGraph.edges.map(edge => s"${edge.srcId}-[${edge.attr}]->${edge.dstId}").collect()
val mappedTriplets = sourceGraph.triplets.map(triplet =>
s"${triplet.srcId}(${triplet.srcAttr})-[${triplet.attr}]->${triplet.dstId}(${triplet.dstAttr})").collect()
mappedVertices should have size 3
mappedVertices should contain allOf("name: A, age: 20", "name: B, age: 21", "name: C, age: 22")
mappedEdges should have size 2
mappedEdges should contain allOf("1-[RelationshipAttributes(0,1)]->2", "1-[RelationshipAttributes(0,0)]->3")
mappedTriplets should have size 2
mappedTriplets should contain allOf("1(Friend(A,20))-[RelationshipAttributes(0,1)]->2(Friend(B,21))",
"1(Friend(A,20))-[RelationshipAttributes(0,0)]->3(Friend(C,22))")
}
When triplets are called, the engine starts by shipping vertices attributes to org.apache.spark.graphx.impl.ReplicatedVertexView. ReplicatedVertexView is an in-memory materialized view of the vertices. The whole operation consists on bringing vertices attributes to the edges because for the most of real-world graphs, the number of edges is much bigger than the number of vertices. Therefore, it reduces the amount of data exchanged between executors. If we comment all lines about vertices and edges in the previous test, we can see shuffling in the logs:
DEBUG Fetching outputs for shuffle 1, partitions 1-2 (org.apache.spark.MapOutputTrackerMaster:58) DEBUG Fetching outputs for shuffle 1, partitions 0-1 (org.apache.spark.MapOutputTrackerMaster:58) DEBUG Fetching outputs for shuffle 1, partitions 3-4 (org.apache.spark.MapOutputTrackerMaster:58) DEBUG Fetching outputs for shuffle 1, partitions 2-3 (org.apache.spark.MapOutputTrackerMaster:58) DEBUG maxBytesInFlight: 50331648, targetRequestSize: 10066329, maxBlocksInFlightPerAddress: 2147483647 (org.apache.spark.storage.ShuffleBlockFetcherIterator:58) DEBUG maxBytesInFlight: 50331648, targetRequestSize: 10066329, maxBlocksInFlightPerAddress: 2147483647 (org.apache.spark.storage.ShuffleBlockFetcherIterator:58) DEBUG maxBytesInFlight: 50331648, targetRequestSize: 10066329, maxBlocksInFlightPerAddress: 2147483647 (org.apache.spark.storage.ShuffleBlockFetcherIterator:58) DEBUG maxBytesInFlight: 50331648, targetRequestSize: 10066329, maxBlocksInFlightPerAddress: 2147483647 (org.apache.spark.storage.ShuffleBlockFetcherIterator:58) INFO Getting 1 non-empty blocks out of 4 blocks (org.apache.spark.storage.ShuffleBlockFetcherIterator:5 4) INFO Getting 1 non-empty blocks out of 4 blocks (org.apache.spark.storage.ShuffleBlockFetcherIterator:5 4) INFO Getting 1 non-empty blocks out of 4 blocks (org.apache.spark.storage.ShuffleBlockFetcherIterator:5 4) INFO Getting 0 non-empty blocks out of 4 blocks (org.apache.spark.storage.ShuffleBlockFetcherIterator:5 4) INFO Started 0 remote fetches in 29 ms (org.apache.spark.storage.ShuffleBlockFetcherIterator:54)
Or in the Spark UI:
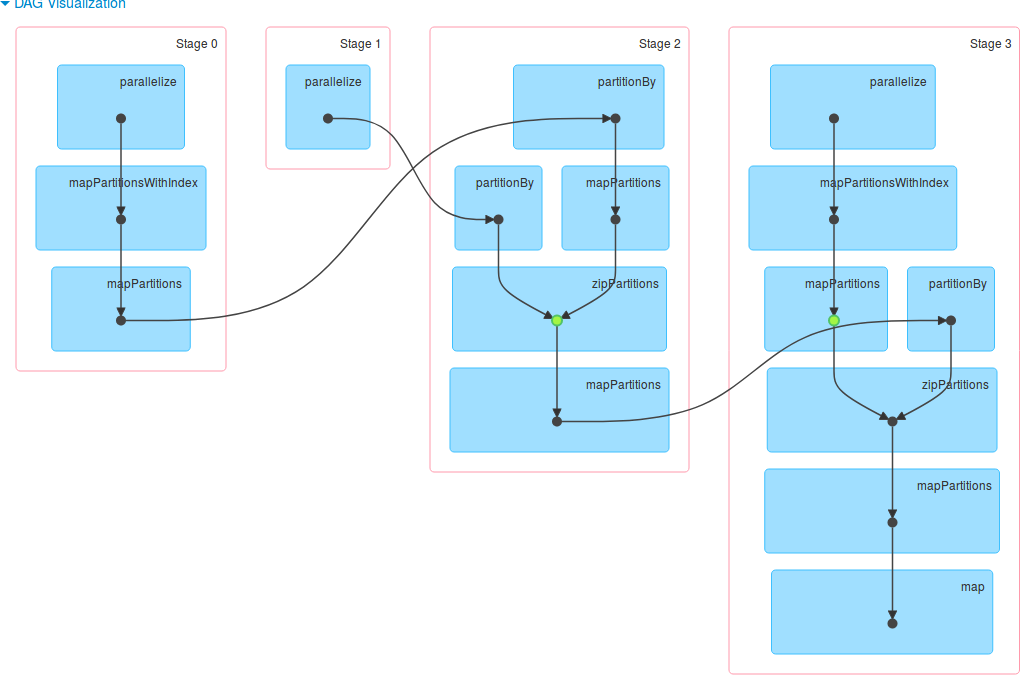
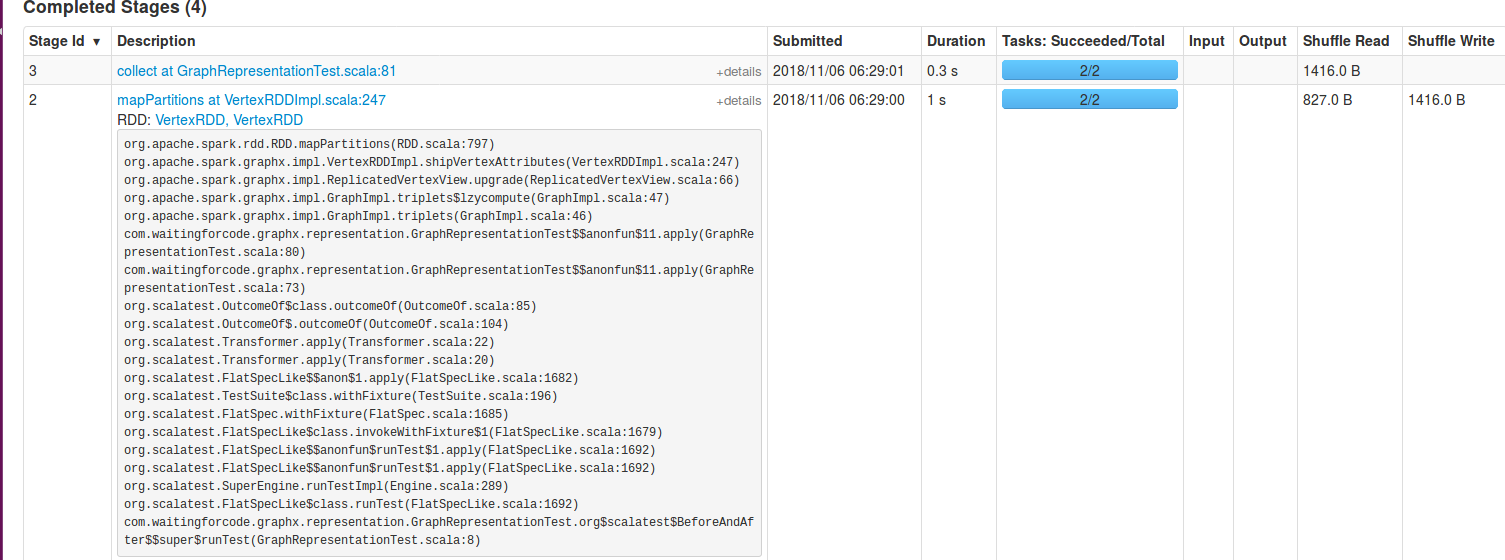
Other characteristics
GraphX's Graph object shares other characteristics of RDDs. If the same graph is reused, we can cache it with classical cache() or persist(StorageLevel) method. The vertices and edges composing the graph are cached separately and the final cache execution is delegated into RDD's cache or persist method:
override def persist(newLevel: StorageLevel): Graph[VD, ED] = {
vertices.persist(newLevel)
replicatedVertexView.edges.persist(newLevel)
this
}
override def cache(): Graph[VD, ED] = {
vertices.cache()
replicatedVertexView.edges.cache()
this
}
Besides caching, Graph supports also other RDD properties, such as partitioning and checkpointing. The former one is defined with an implementation of org.apache.spark.graphx.PartitionStrategy and applies to the edges. The checkpointing is a method bringing fault-tolerance. Both concepts will be covered more in details in the next posts from GraphX category.
Graph and its implementation (GraphImpl) is the entry point for manipulating graph data in Apache Spark GraphX. It's composed of 2 RDDs: vertices and edges. But as we could learn in this post, it also exposes the triplets, i.e. an enriched version of edges. Graph structure inherits a lot of behavior from RDD. It can be cached, partitioned and checkpointed. However, the last 2 concepts were only shortly mentioned in this post because they'll be covered deeper in one of the next articles.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Graphs representation in Apache Spark GraphX here:
Related blog posts:
- Edge representation in Apache Spark GraphX
- Vertex representation in Apache Spark GraphX
- PCollection - data representation in Apache Beam
- Dataset in Spark SQL
- DStream in Spark Streaming
Nothing better to start to learn a #graph data processing framework than... the graph representation: https://t.co/CUVLlh7m9b #ApacheSpark #GraphX
— Bartosz Konieczny (@waitingforcode) December 5, 2018