
One of the biggest changes for PySpark has been the DataFrame API. It greatly reduces the JVM-to-PVM communication overhead and improves the performance. However, it also complexities the code. Probably, some of you have already seen, written, or worked with the code like this...
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
# mappers.py
def add_birth_year_untyped(people_df: DataFrame) -> DataFrame:
return people_df.withColumn('birth_year', F.year(F.current_date()) - F.col('age'))
# filter.py
def get_people_older_than_untyped(people_df: DataFrame, age_limit: int) -> DataFrame:
return people_df.filter(F.col('age') > age_limit)
# job.py
people_dataset = spark.createDataFrame(rows, 'id INT, name STRING, age INT, address STRUCT<street_name STRING, city STRUCT<city_name STRING, zip_code STRING>>')
older_than_18 = get_people_older_than_untyped(people_dataset, 18)
older_than_18_with_birth_year = add_birth_year_untyped(older_than_18)
Agree, the code does the job but it's a part of a bigger code base and in a long run the evolution and maintenance can be costly. The same names of columns are spread across different files which opens doors to some runtime bugs (on your dev environment, hopefully!) and more difficult understanding since there is no clear association of the column names to a particular DataFrame.
Dataset in Scala API
If you are a lucky user of the Dataset in Apache Spark Scala API, you don't need all this. Instead, you can simply cast your DataFrame to a case class and perform all required operations on top of each instance.
There is a way to overcome this issue, though. The Proxy design pattern that exposes a placeholder for another object and controls the access method. That way, for all column-related interactions, you don't interact with the DataFrame API directly, but with the Proxy instance. The next diagram shows a high-level view of this implementation:
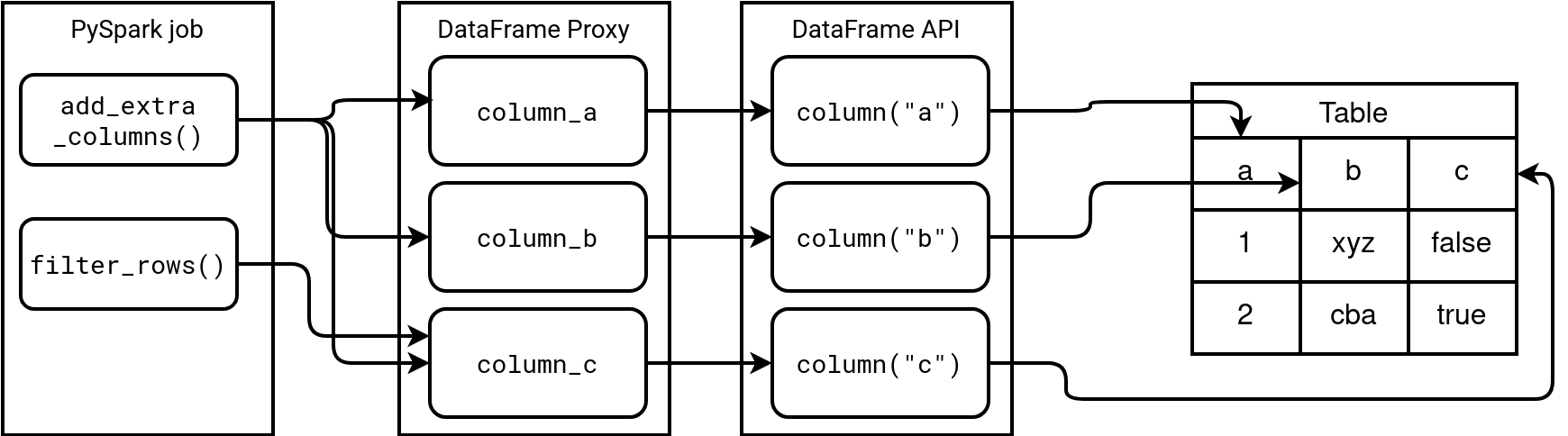
As you can notice, the functions don't repeat the functions.column(...) calls anymore. Instead, they reference the columns from a shared proxy object that in its turn calls - only once this time - the column(...) method.
Code sample
To understand it better, let's see some code. The most important part of the implementation is this class:
@dataclass(kw_only=True)
class SchemaAttribute:
name: str
type: DataType
def as_column(self) -> Column:
return functions.col(self.name)
def as_field(self) -> StructField:
return StructField(self.name, self.type)
def for_row(self, values: List | Any) -> (str, [List | Any]):
if not isinstance(values, list):
return {self.name: values}
entries = reduce(lambda union, next_dict: union.update(next_dict) or union, values, {})
return {
self.name: entries
}
The SchemaAttribute is a simple wrapper that defines some behavior for converting the wrapped values into a StructType field or a Column. And it's extensible. If you need to create a struct types in the schema, you can extend the SchemaAttribute and compose your structure as in the next snippet:
@dataclass(kw_only=True)
class CitySchemaAttribute(SchemaAttribute):
city_name = SchemaAttribute(name='city_name', type=StringType())
zip_code = SchemaAttribute(name='zip_code', type=StringType())
def as_field(self) -> StructField:
return StructField(self.name, StructType(fields=[self.city_name.as_field(), self.zip_code.as_field()]))
@dataclass(kw_only=True)
class AddressSchemaAttribute(SchemaAttribute):
street_name = SchemaAttribute(name='street_name', type=StringType())
city = CitySchemaAttribute(name='city', type=StructType())
def as_field(self) -> StructField:
return StructField(self.name, StructType(fields=[self.street_name.as_field(), self.city.as_field()]))
As you can see here, we're creating an address structure composed of a nested city structure and a simple street name attribute. Putting all this together, you could create the schema for a people dataset like this:
@dataclass(frozen=False) class PeopleSchema: id: SchemaAttribute = SchemaAttribute(name='id', type=IntegerType()) name: SchemaAttribute = SchemaAttribute(name='name', type=StringType()) age: SchemaAttribute = SchemaAttribute(name='age', type=IntegerType()) address: AddressSchemaAttribute = AddressSchemaAttribute(name='address', type=StructType())
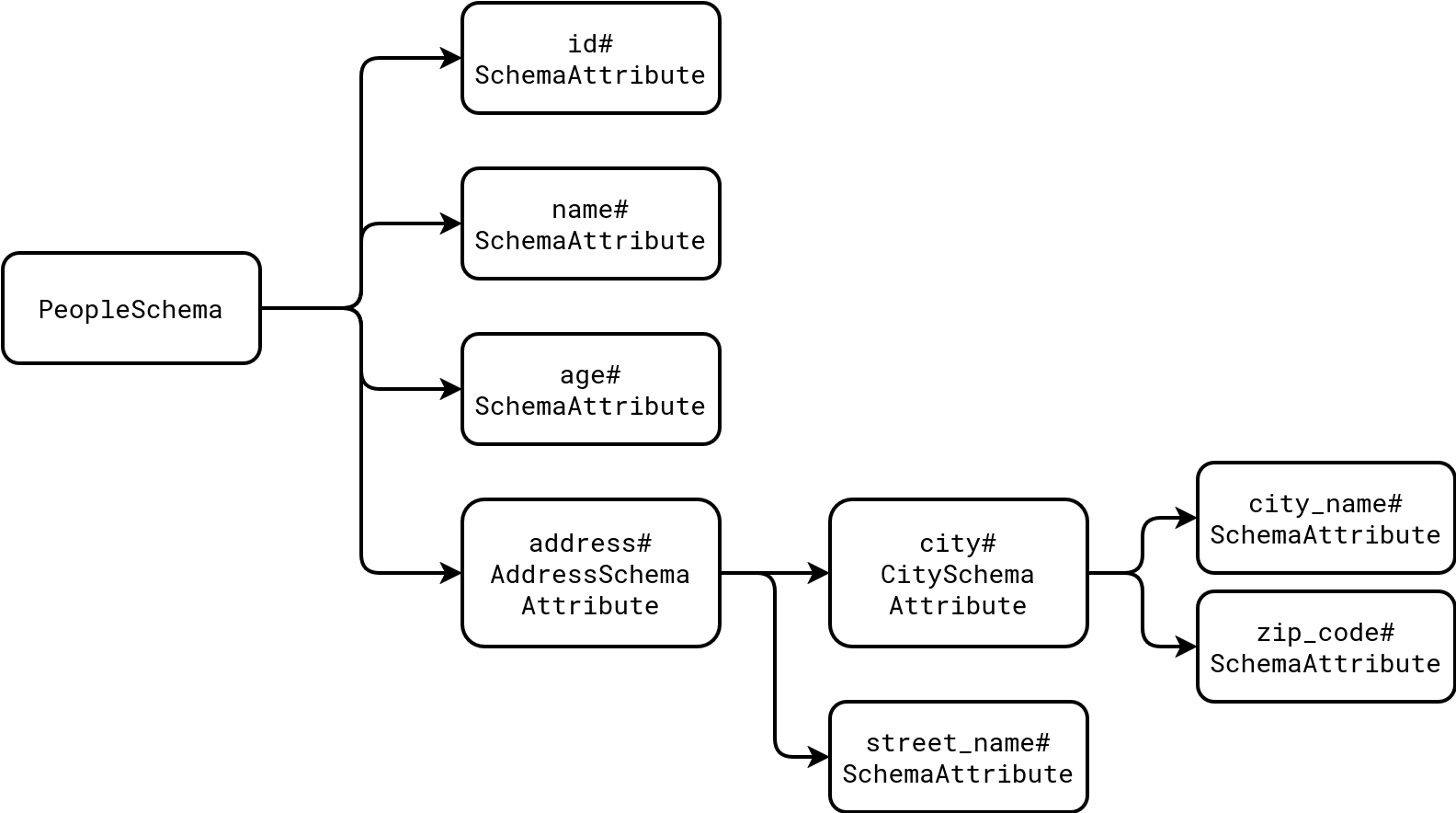
With that, our two functions that repeat the age column can reference the PeopleSchema directly as:
# filters.py
def get_people_older_than(people_df: DataFrame, age_limit: int) -> DataFrame:
return people_df.filter(PeopleSchema.age.as_column() > age_limit)
# mappers.py
def add_birth_year(people_df: DataFrame) -> DataFrame:
return people_df.withColumn('birth_year', F.year(F.current_date()) - PeopleSchema.age.as_column())
Besides avoiding the age attribute to be repeated, you can fully leverage the auto-completion feature of your IDE whenever you deal with one of the columns:
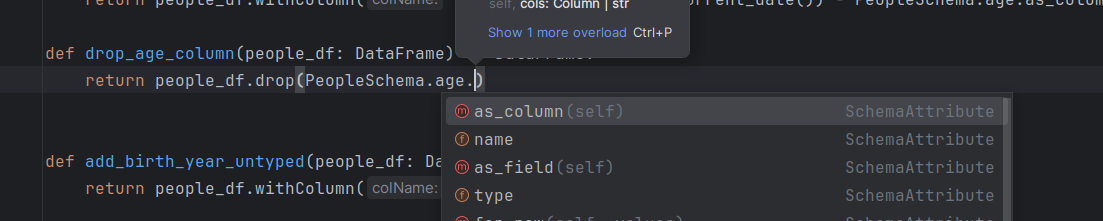
Another interesting features are the utilitary methods you can create to automatically generate the StructType schema version or an in-memory Row. Both are pretty convenient for unit tests definition:
def create_spark_schema_for_typed_schema(typed_schema: dataclass) -> StructType:
schema_fields = [field.default.as_field() for field in dataclasses.fields(typed_schema)]
return StructType(fields=schema_fields)
def create_in_memory_row(*row_attributes) -> Row:
row_dict = reduce(lambda union, next_dict: union.update(next_dict) or union, row_attributes, {})
return Row(**row_dict)
# Example
rows = [(create_in_memory_row(
PeopleSchema.id.for_row(1), PeopleSchema.name.for_row('name_1'), PeopleSchema.age.for_row(20),
PeopleSchema.address.for_row([
PeopleSchema.address.city.for_row([
PeopleSchema.address.city.city_name.for_row('Some city'),
PeopleSchema.address.city.zip_code.for_row('00000')
]), PeopleSchema.address.street_name.for_row('Some street')
])
)), (create_in_memory_row(
PeopleSchema.id.for_row(2), PeopleSchema.name.for_row('name_2'), PeopleSchema.age.for_row(30),
PeopleSchema.address.for_row([
PeopleSchema.address.city.for_row([
PeopleSchema.address.city.city_name.for_row('Some city 2'),
PeopleSchema.address.city.zip_code.for_row('00001')
]), PeopleSchema.address.street_name.for_row('Some street 2')
])
))]
people_dataset = spark.createDataFrame(rows, create_spark_schema_for_typed_schema(PeopleSchema))
TypedSpark
The blog post shares a do-it-yourself solution but you can also use an existing library called TypedSpark, brought to the community by Kaiko.
The proxy is not the single solution you could use to address the repetition problem. Instead you could simply leverage constant column names declared in an enumeration. It may be a valid solution to your problem. The SchemaAttribute proxy gives an additional documentation layer as it provides not only the column names but also their types. Besides, it can be also leveraged in the unit tests layer for a more convenient datasets creation. I wouldn't call it a DSL I've been dreaming about since I saw one written in Groovy a long time ago, but it's pretty close! And I must admit, the auto-completion support is also great, so if you are hesitating between the constant names solution, and something more advanced, you can give a try and extend the proxy in your code base!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩