
We've learned in the previous PySpark blog posts about the serialization overhead between the Python application and JVM. An intrinsic actor of this overhead are Python serializers that will be the topic of this article and hopefully, will provide a more complete overview of the Python <=> JVM serialization.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Serializer API
A typical PySpark serializer supports 2 operations, the dump and load. The former one serializes Python objects to the output stream while the latter does the opposite and returns the deserialized objects from the input stream.
PySpark implements the serializers with the Serializer class that defines the aforementioned dump and load method:
class Serializer:
def dump_stream(self, iterator, stream):
"""
Serialize an iterator of objects to the output stream.
"""
raise NotImplementedError
def load_stream(self, stream):
"""
Return an iterator of deserialized objects from the input stream.
"""
raise NotImplementedError
def dumps(self, obj):
"""
Serialize an object into a byte array.
When batching is used, this will be called with an array of objects.
"""
raise NotImplementedError
def _load_stream_without_unbatching(self, stream):
"""
Return an iterator of deserialized batches (iterable) of objects from the input stream.
If the serializer does not operate on batches the default implementation returns an
iterator of single element lists.
"""
return map(lambda x: [x], self.load_stream(stream))
Types and purposes
The Serializer is an abstract class with multiple serializers. By "multiple" I mean really a lot and that's the reason why I prefer to give you a general object tree hierarchy before focusing more deeply on the serializers in the code.
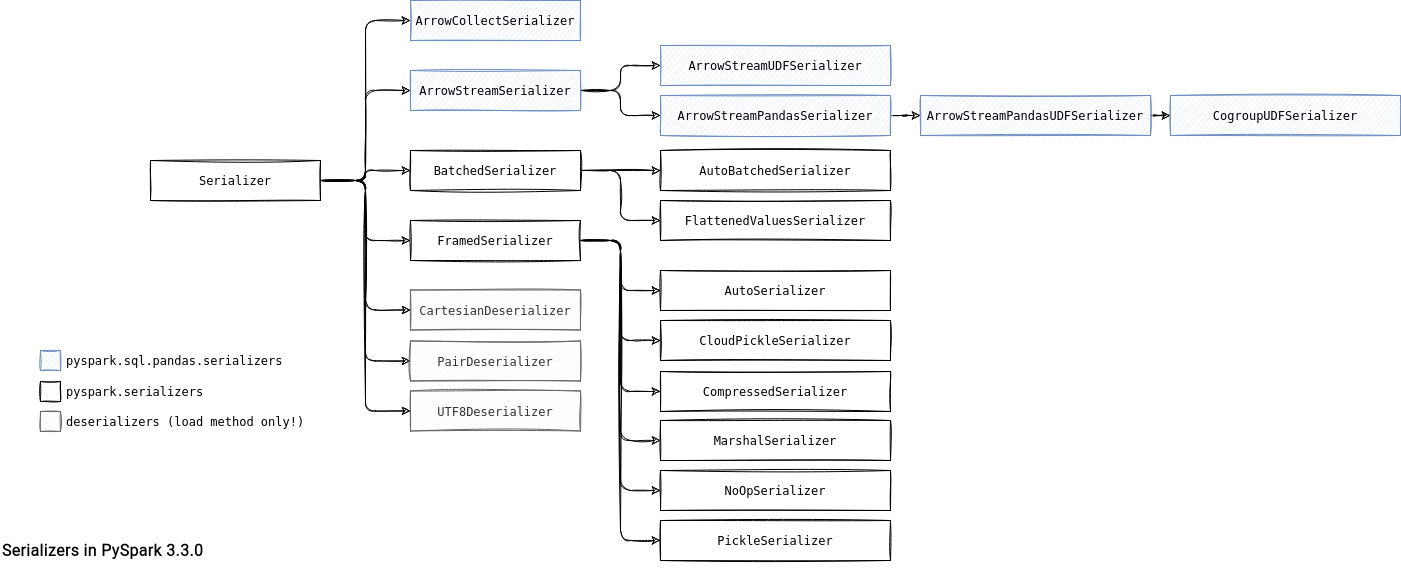
As you can notice, there are 3 main groups of serializers that I'll shortly detail in the next sections.
Deserializers
The easiest one to understand because it contains 3 classes (CartesianDeserializer, PairDeserializer, UTF8Deserializer) responsible for deserializing objects from the input stream. To be more precise:
- UTF8Deserializer converts UTF-8 strings. It's there to read text from the JVM and processing RDDs created from textFile() and wholeTextFiles() methods.
- PairDeserializer references 2 other serializers, one for the key and another for the value of the pair. PySpark uses it for creating RDDs built from binaryFiles(), wholeTextFiles() or zip() methods. In the former 2 the PairDeserializer uses UTF8Deserializer to deserialize the key being the name of the input file.
- CartesianDeserializer is there to handle RDD created from cartesian() method. Since it also involves 2 parts, CartesianDeserializer references 2 other serializers.
PySpark serializers - BatchedSerialier
It's the most popular group where you can find 2 main serializers. The first of them is BatchedSerializer that works on the batched streams. It's a wrapper around another serializer and its single added value is grouping the iterator into batches, as shows the _batched function called in the load and dump actions:
class BatchedSerializer(Serializer):
# ...
def _batched(self, iterator):
if self.batchSize == self.UNLIMITED_BATCH_SIZE:
yield list(iterator)
elif hasattr(iterator, "__len__") and hasattr(iterator, "__getslice__"):
n = len(iterator)
for i in range(0, n, self.batchSize):
yield iterator[i : i + self.batchSize]
else:
items = []
count = 0
for item in iterator:
items.append(item)
count += 1
if count == self.batchSize:
yield items
items = []
count = 0
if items:
yield items
The BatchedSerializer has 2 implementations:
- AutoBatchedSerializer that chooses the batch size dynamically from the input object.
- FlattenedValuesSerializer used for the streams of list of pairs. It tries to create list values of the same size for each key:
def _batched(self, iterator): n = self.batchSize for key, values in iterator: for i in range(0, len(values), n): yield key, values[i : i + n]It's involved in the spilling for the shuffle-related operations, such as groupByKey or combineByKey.
PySpark serializers - FramedSerializer
The second PySpark serializers family is represented by FramedSerializer. As its name suggests, it works on top of frames and writes objects as (length, data) pairs. Among its implementations you'll find:
- AutoSerializer. It dynamically resolves the serialization protocol to Marshal or Pickle. The resolution consists of analyzing the first byte of the stream, as below in the dump example:
# dump writes the stream with the first byte set to M or P def loads(self, obj): _type = obj[0] if _type == b"M": return marshal.loads(obj[1:]) elif _type == b"P": return pickle.loads(obj[1:]) else: raise ValueError("invalid serialization type: %s" % _type) - CompressedSerializer. It works on ZLIB-compressed stream, mainly involved in the shuffle operations on the Python side, for example during spilling.
- MarshalSerializer. It relies on Marshal serializer that is faster than CloudPickleSerializer. However, it supports fewer data types and seems not to be used in the code anymore.
- NoOpSerializer. It's a no-op serializer, so a serializer that does nothing with the input and output stream data. Put another way, it returns them directly. It's mainly used for binary data, including binary RDDs (e.g, binaryFiles()).
- PickleSerializer. It uses Python pickle module for serialization.
- CloudPickleSerializer. It uses a more optimized pickle version called cloudpickle. It supports more types than the classical pickle.
Both Pickle-based serializers are the most widely used in the data exchange with the default choice set to CloudPickleSerializer if the Python version is greater than 3.8:
# pyspark/serializers.py if sys.version_info < (3, 8): CPickleSerializer = PickleSerializer else: CPickleSerializer = CloudPickleSerializer
The Pickle-like serializers are default serializers for transferring data but if for whatever reason you need to change it, you can do it with the serializer attribute of SparkContext. It's worth noticing that the SparkContext must be created before SparkSession in that context:
spark_context = SparkContext(serializer=MarshalSerializer())
spark_session = SparkSession.builder.master("local[1]").getOrCreate()
Pandas serializers
Finally, PySpark also has serializers from the Pandas package:
- ArrowCollectSerializer. It's the serializer involved in the toPandas() action if the spark.sql.execution.arrow.pyspark.enabled is set to true.
- ArrowStreamSerializer. It completes Apache Arrow usage with the following implementations:
- ArrowStreamUDFSerializer used for the functions defined in the mapInArrow function.
- ArrowStreamPandasSerializer. The parent class is used to create a PySpark DataFrame from Pandas DataFrame backed by Apache Arrow. Additionally, it has 2 specialized subclasses:
- ArrowStreamPandasUDFSerializer. As the name indicates, the serializer takes part of the Pandas UDF evaluation. It also has a specialized serializer called CogroupUDFSerializer to handle co-grouped Pandas UDFs (applyInPandas).
Examples
PySpark has multiple serializers where each is responsible for a dedicated task and it looks quite complex. However, there is good news. You won't probably need to modify this part unless you're doing really complex and low level things!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Serializers in PySpark here:
Related blog posts:
- Abstracting column access in PySpark with Proxy design pattern
- Shuffle in PySpark
- PySpark and pyspark.zip story
Serialization/deserialization is a relatively easy concept to understand. In theory. In practice it can be quite challenging. It's the case of #PySpark where the serializers adapt to the code you write ? https://t.co/AKeT17NfN9
— Bartosz Konieczny (@waitingforcode) November 26, 2022