
Shuffle is for me a never-ending story. Last year I spent long weeks analyzing the readers and writers and was hoping for some rest in 2022. However, it didn't happen. My recent PySpark investigation led me to the shuffle.py file and my first reaction was "Oh, so PySpark has its own shuffle mechanism?". Let's check this out!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Genesis
PySpark shuffle is not a new concept. It has been there since Apache Spark 1.1.0 (!) and got introduced during 2014 by Davies Liu as a part of SPARK-2538: External aggregation in Python.
The problem PySpark users faced at that time were job failures caused by OOM errors when the reduce tasks had data bigger than the available memory. The solution was to use the same spilling technique as for the JVM part, so writing data from memory on disk.
If you have read the JIRA title carefully, you should have noticed the "external" word in the title. It's not a coincidence. These aggregations work on Python functions, so externally to the Apache Spark JVM engine. If you look for them in the code, you'll very quickly identify some of them because they all start with an External prefix.
To understand the purpose of these external aggregations, let's analyze 3 shuffle-based functions: groupByKey, combineByKey and sortByKey.
groupByKey
The groupByKey operation is only a high-level interface. If you check the implementation out, you will notice that several other transformations occur. Each of them invokes an external aggregation, as shown in the following schema:
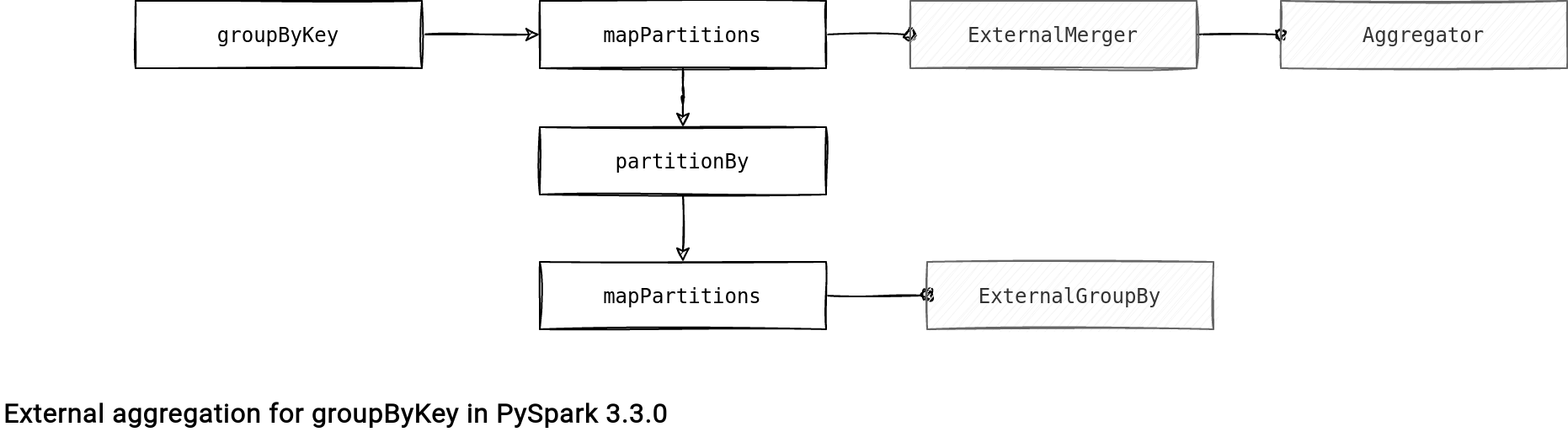
The Aggregator is simply a class holding the grouping logic (init, merge values, merge combiners) and there is no shuffle happening in there. The ExternalMerger, on the other hand, is the first place when the shuffle, and eventually spilling, occur. To be more precise, the groupByKey operation uses these 2 methods of the ExternalMerger:
- mergeValues. The finality of this step are all input records grouped in the single container, and hence, returned one-by-one to the consumer process. At a first glance, it looks like a simple iteration putting records to a dictionary but in fact, it's a bit more complex than that. First, the process checks the current memory usage. If it's greater than the limit, it moves in-memory data to files on disk. It also does it after iterating all records, in the end of the method:
def mergeValues(self, iterator): # ... for k, v in iterator: d = pdata[hfun(k)] if pdata else data d[k] = comb(d[k], v) if k in d else creator(v) c += 1 if c >= batch: if get_used_memory() >= limit: self._spill() # ... if get_used_memory() >= limit: self._spill()The spilling process uses an ExternalMerger attribute called partitions. The field represents the number of files to create for each spill. Each of these partitions contains a defined subset of input data:def _spill(self): # ... if not self.pdata: # Init pdata else: for i in range(self.partitions): p = os.path.join(path, str(i)) with open(p, "wb") as f: # dump items in batch self.serializer.dump_stream(iter(self.pdata[i].items()), f) self.pdata[i].clear() DiskBytesSpilled += os.path.getsize(p) # ...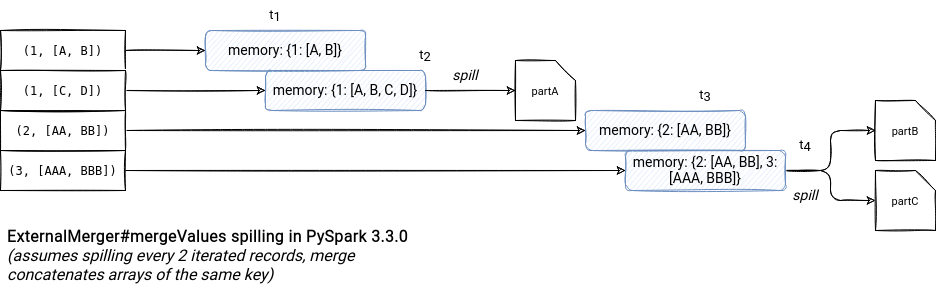
- items. The items method is another easy-looking-but-complex operation. Apparently it only returns the locally merged items but this action becomes way more difficult if the spilling is involved.
- Read all spill partitions. By default there are 59 partitions which means that the process will sequentially read ${spill number} files (59 x ${spills number} files in total).
- Inside each spill partition, the method iterates all spill actions. Whenever a spill need is detected, the mergeValues spills all buffered data, potentially writing all partition files.
- For the first spill file, the process loads the content into memory.
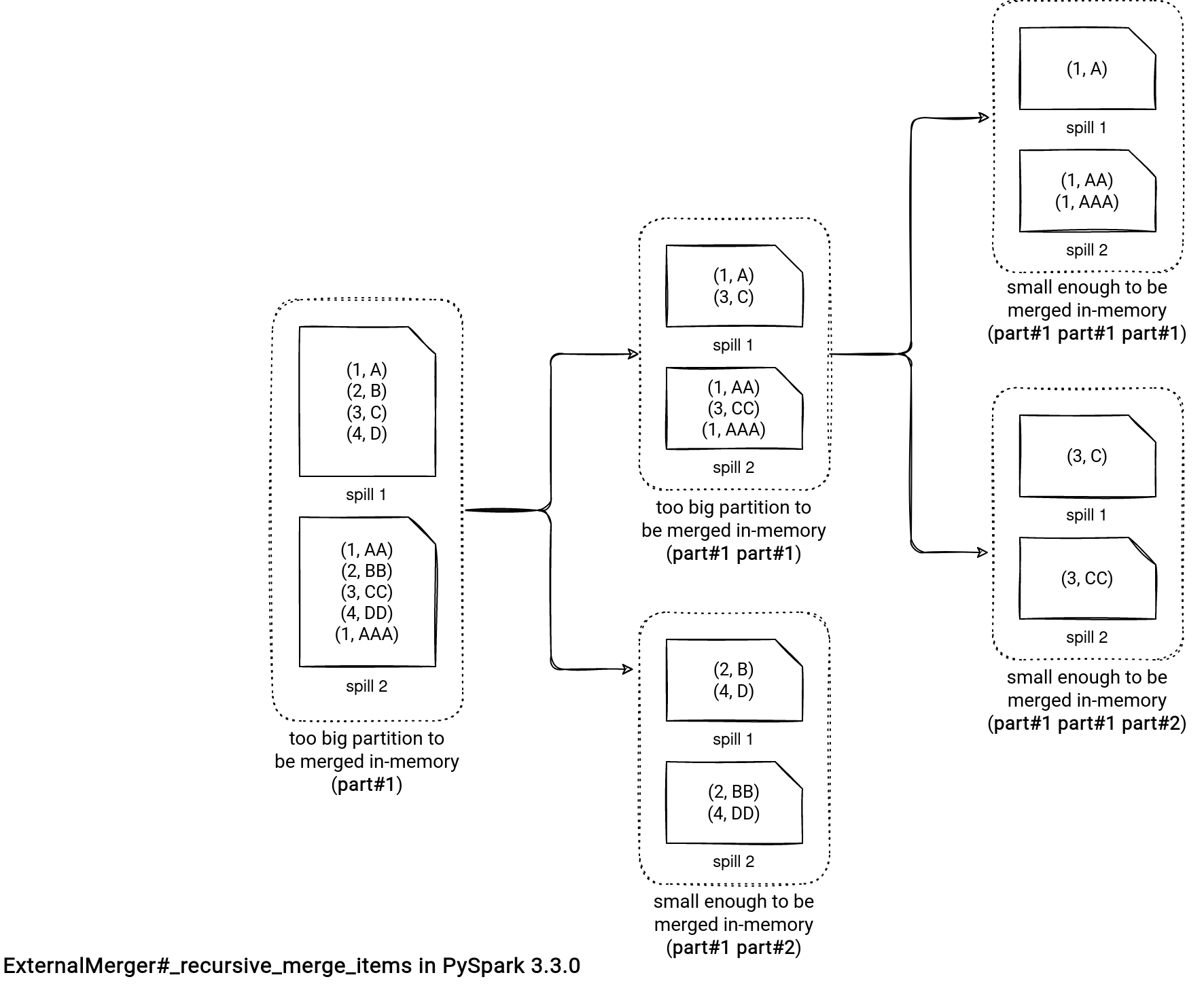
- For the next spill files, if the memory pressure is high, it fallbacks into a recursive merge. Otherwise, the operation continues by loading each file and merging its content with the in-memory data.
- When it comes to the recursive merge, it consists of subdividing the initial partition to the reasonable partition size that can be combined and returned without impacting the memory. The operation creates smaller partitions and regenerates corresponding smaller spill files if necessary. Let's take a look at a picture to understand it better.
After creating these groups, groupByKey uses yet another External* aggregator, the ExternalGroupBy. The first aggregator (ExternalMerger) is there to group rows sharing the same key while the ExternalGroupBy is there to apply the user function on top of these groups. The groups creation depends on the dataset:
- For small datasets where the number of keys is smaller than SORT_KEY_LIMIT (1000), the spilled files contain rows already sorted by key. Otherwise, the spilling writes them as they come.
- If the spilled files don't sort the groups, the operation calls ExternalSorter to make the final combination and generate the groups to the client code. I'll cover this external aggregator in the last section. Here, it's worth noticing that the ExternalSorter uses a FlattenedValuesSerializer to create an evenly sized subgroup of values for each key.
combineByKey
The combineByKey uses only the ExternalMerger. The single difference with the groupByKey is the lack of ExternalGroupBy, replaced in the last step by the mergeCombiners method from the ExternalMerger.
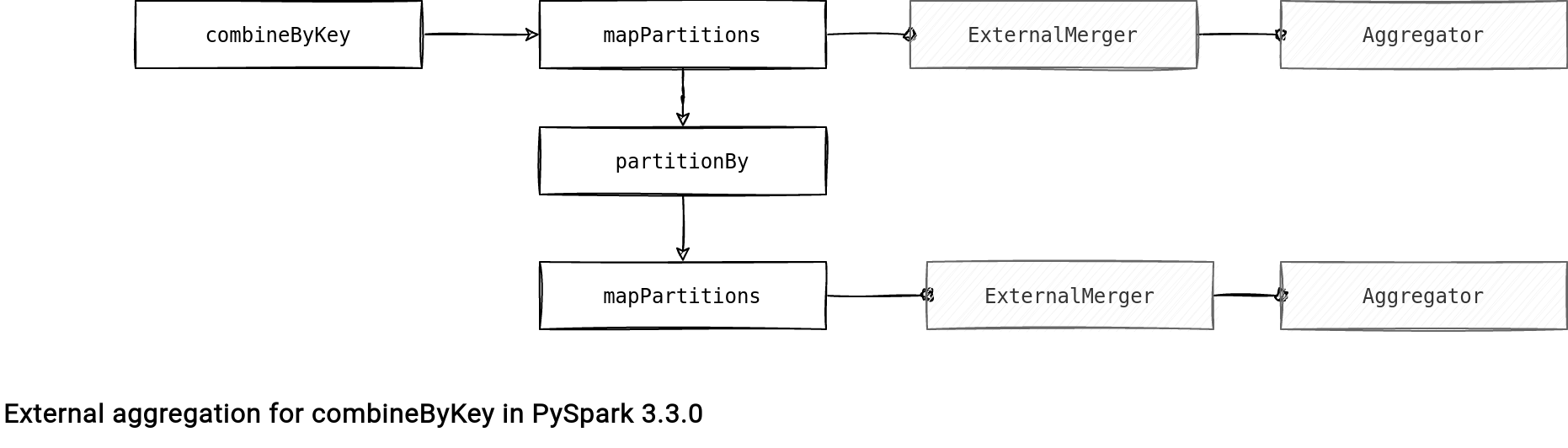
The first part where the ExternalMerger is involved behaves the same as in the groupByKey; it's a mergeValues() call followed by the items():
def combineByKey(
self: "RDD[Tuple[K, V]]", createCombiner: Callable[[V], U],
mergeValue: Callable[[U, V], U], mergeCombiners: Callable[[U, U], U],
numPartitions: Optional[int] = None, partitionFunc: Callable[[K], int] = portable_hash,
) -> "RDD[Tuple[K, U]]":
# ...
def combineLocally(iterator: Iterable[Tuple[K, V]]) -> Iterable[Tuple[K, U]]:
merger = ExternalMerger(agg, memory * 0.9, serializer)
merger.mergeValues(iterator)
return merger.items()
locally_combined = self.mapPartitions(combineLocally, preservesPartitioning=True)
shuffled = locally_combined.partitionBy(numPartitions, partitionFunc)
# ...
The things are different in the final mapPartitions step where the combineByKey calls ExternalMerger's mergeCombiners followed by the items():
def combineByKey(
self: "RDD[Tuple[K, V]]", createCombiner: Callable[[V], U],
mergeValue: Callable[[U, V], U], mergeCombiners: Callable[[U, U], U],
numPartitions: Optional[int] = None, partitionFunc: Callable[[K], int] = portable_hash,
) -> "RDD[Tuple[K, U]]":
# ...
def _mergeCombiners(iterator: Iterable[Tuple[K, U]]) -> Iterable[Tuple[K, U]]:
merger = ExternalMerger(agg, memory, serializer)
merger.mergeCombiners(iterator)
return merger.items()
return shuffled.mapPartitions(_mergeCombiners, preservesPartitioning=True)
The mergeCombiners is the method applying the merge functions on top of the previously created pre-shuffle partial aggregates. It can also lead to create spill files which would result in calling the aforementioned _recursive_merged_items for partitions too big to fit into the memory.
sortByKey
The logic for the last key-based operation doesn't involve an explicit spill. I mean, the code doesn't mention a spill but definitely does one. After all, the sorting logic also relies on an external-like class called ExternalSorter.
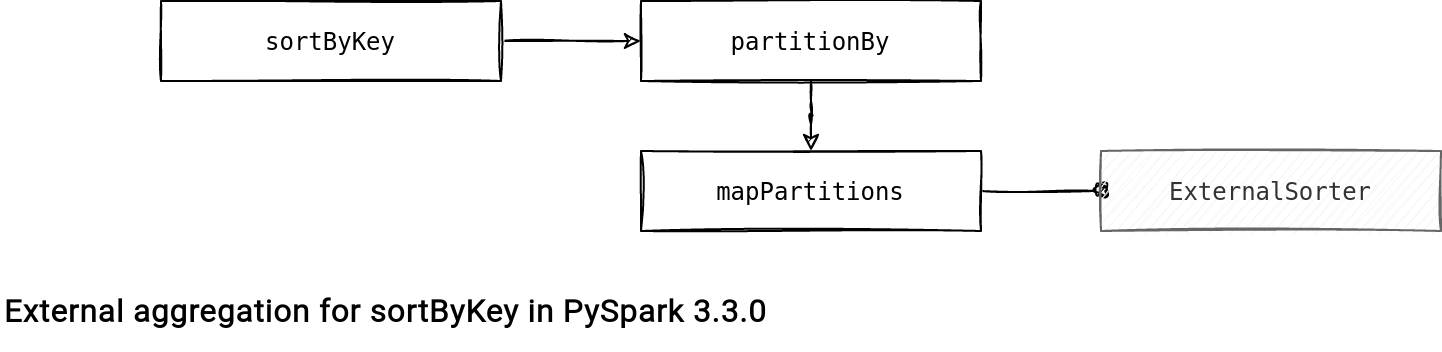
Under-the-hood, PySpark first partitions the data and only after bringing records with similar keys together, it applies the sorting logic from the ExternalSorter. The logic does the following:
- Divide the iterator to sort into multiple groups and accumulate them in memory as long as the memory usage doesn't reach the allowed threshold.
- After reaching the threshold, sort each group in memory with classical Python's .sort() method and serialize the result into a temporary sort file.
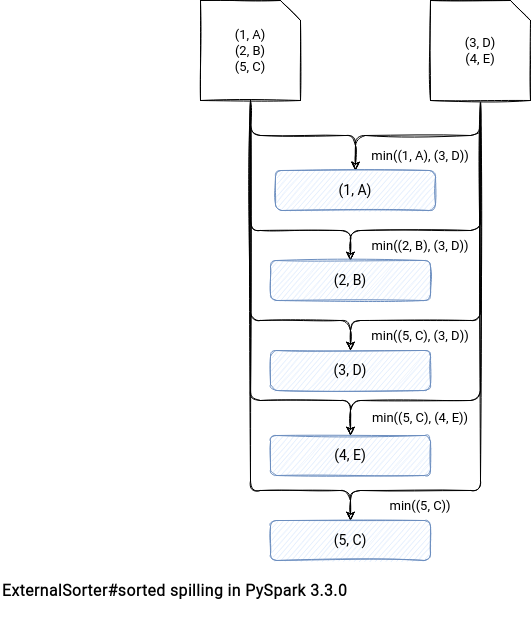
def sorted(self, iterator, key=None, reverse=False): # ... if used_memory > limit: # sort them inplace will save memory current_chunk.sort(key=key, reverse=reverse) path = self._get_path(len(chunks)) with open(path, "wb") as f: self.serializer.dump_stream(current_chunk, f) def load(f): for v in self.serializer.load_stream(f): yield v # close the file explicit once we consume all the items # to avoid ResourceWarning in Python3 f.close() chunks.append(load(open(path, "rb"))) current_chunk = []This part also adds the sorted data into chunks array as an open stream. It returns each entry lazily, with a generator (I've already blogged about the generators in PySpark). - Use the heap queue (priority queue) to merge the spilled files, hence, to return the chunks in order. This step calls the heapq.merge(*chunks, key=key, reverse=reverse) generator function and as before with the yield, doesn't materialize the whole data in-memory. Instead, it reads one record at a time from each chunk stream and returns the smallest/biggest one to PySpark. It works because the chunks are already sorted so there is no need to compare more than one chunk item each time.
This article brings another topic to the table. PySpark shuffle relies on the memory used by the PySpark worker and I haven't covered that division yet!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Shuffle in PySpark here:
Related blog posts:
- Radix and Tim sort
- Shuffle configuration demystified - part 2
- Shuffle configuration demystified - part 1
- Shuffle reading in Apache Spark SQL - wrapping iterators and beyond
- Shuffle reading in Apache Spark SQL
PySpark doesn't stop surprising me. After an interesting serializers topic, I've also discovered a ... shuffle py file! What is it for? It helps avoid OOM errors on the Python side. More details in this article ? https://t.co/6USWEyaEl8
— Bartosz Konieczny (@waitingforcode) December 3, 2022