
The topic of this blog post is not new because the discussed sort algorithms are there from Apache Spark 2. But it happens that I've never had a chance to present them and today I'll try to do it now.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Algorithms logic
Radix and Tim sort algorithms rely on different principles. Let's begin with the Radix algorithm.
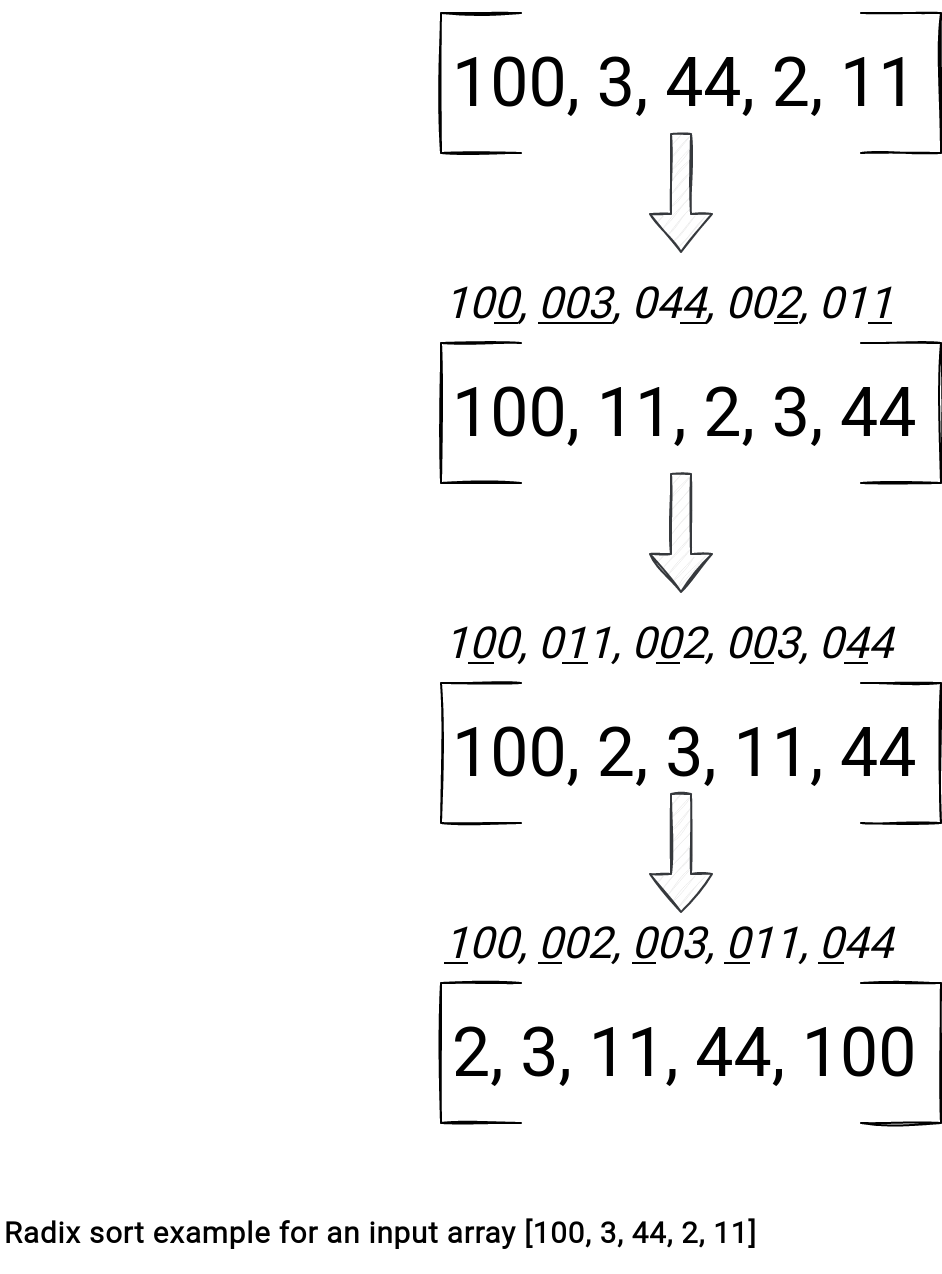
Have you noticed the implementation? Yes, the algorithm uses the least digit to sort the values. When the digit is missing, as for the smallest numbers from the example, the Radix sort uses 0.
The Tim sort implementation is different:
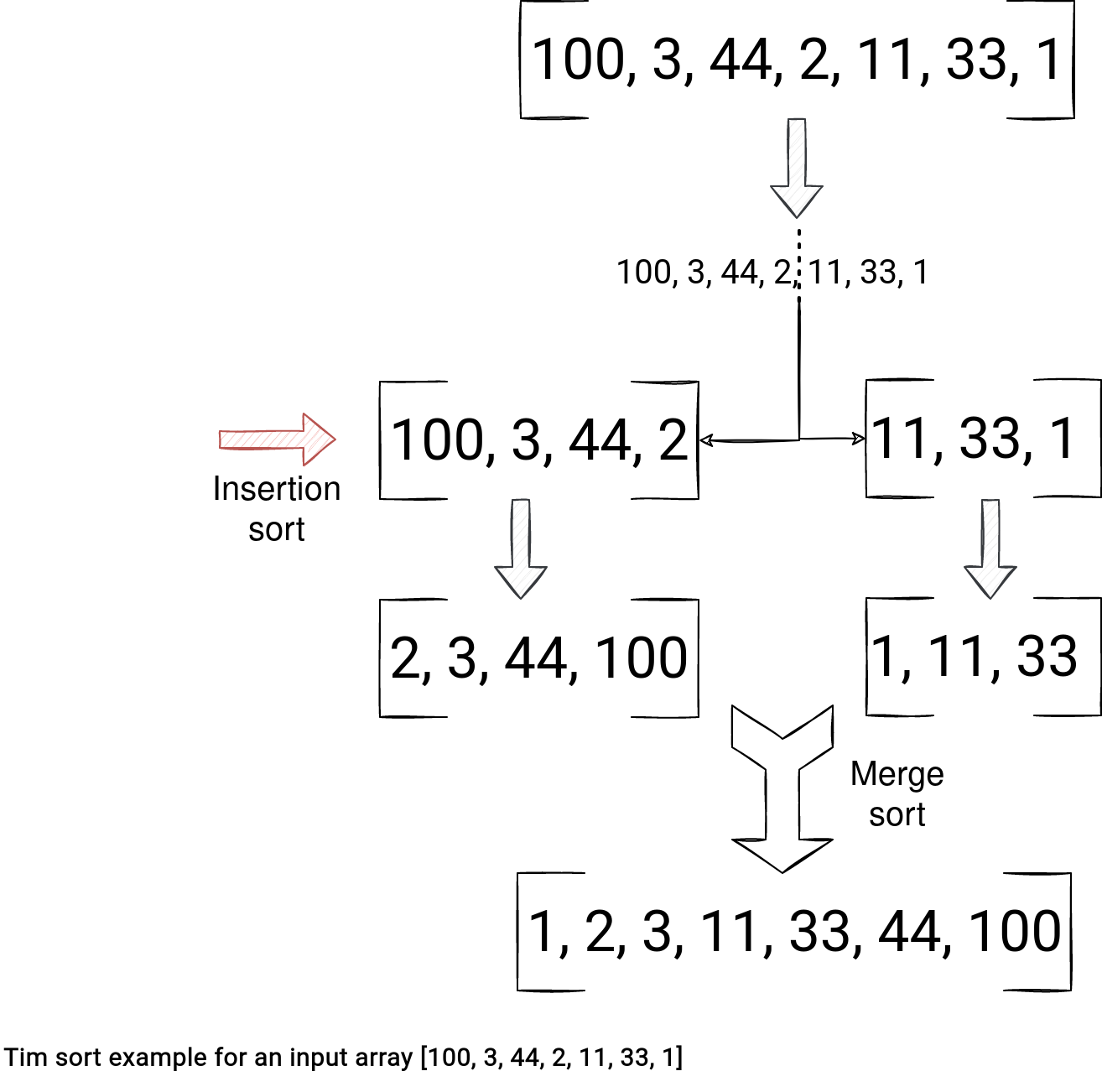
As you can notice, under-the-hood it uses insertion and merge sort algorithms. The idea is to divide the array into buckets called runs and whenever the run is small enough, sort it with the insertion-based algorithm. In the end, Tim sort merges the sorted chunks into the final array.
In addition to these high-level views, let me share some other interesting facts:
- Radix sort requires extra space at the end of the sorted array at least equal to the number of records. Apache Spark implementation in the RadixSort#sort(LongArray array, long numRecords, int startByteIndex, int endByteIndex, boolean desc, boolean signed) method checks this assumption:
public static int sort( LongArray array, long numRecords, int startByteIndex, int endByteIndex, boolean desc, boolean signed) { assert startByteIndex >= 0 : "startByteIndex (" + startByteIndex + ") should >= 0"; assert endByteIndex <= 7 : "endByteIndex (" + endByteIndex + ") should <= 7"; assert endByteIndex > startByteIndex; assert numRecords * 2 <= array.size(); - Tim sort has an extra optimization to avoid reordering already sorted runs. It merges them directly which can save some compute time.
- Galloping is a smart strategy in Tim sort to avoid comparing one index at a time in the merge stage. For example, if the left merged array is smaller than the right in the ascending order for x comparison in a row, the algorithm will turn on the galloping mode. In this strategy, it'll use binary search to locate the first greater value in the left array instead of doing it one element-at-a-time.
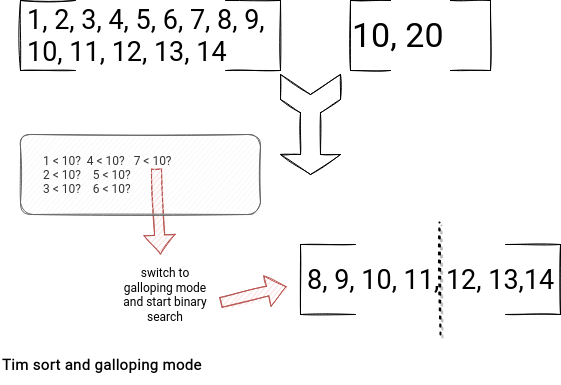
- Tim sort is better than quicksort for nearly sorted data. Quicksort was Apache Spark's sort algorithm until the version 1.1.
- Tim sort also has a concept of minimum run size (minrun) that determines merging efficiency. The merging works better when the number of runs is equal to, or slightly less than, a power of two. It's usually recommended to be set between 32 and 64.
Usage in Apache Spark
Apache Spark uses these sorting algorithms in the UnsafeShuffleWriter, so the object generating shuffle files for the Dataset API. The writer exists for each task and generates shuffle files by transferring each element of the shuffled records to ShuffleExternalSorter. The last class, in its turn, will use an instance of a ShuffleInMemorySorter that delegates the sorting logic to Tim or Redix sort algorithm.
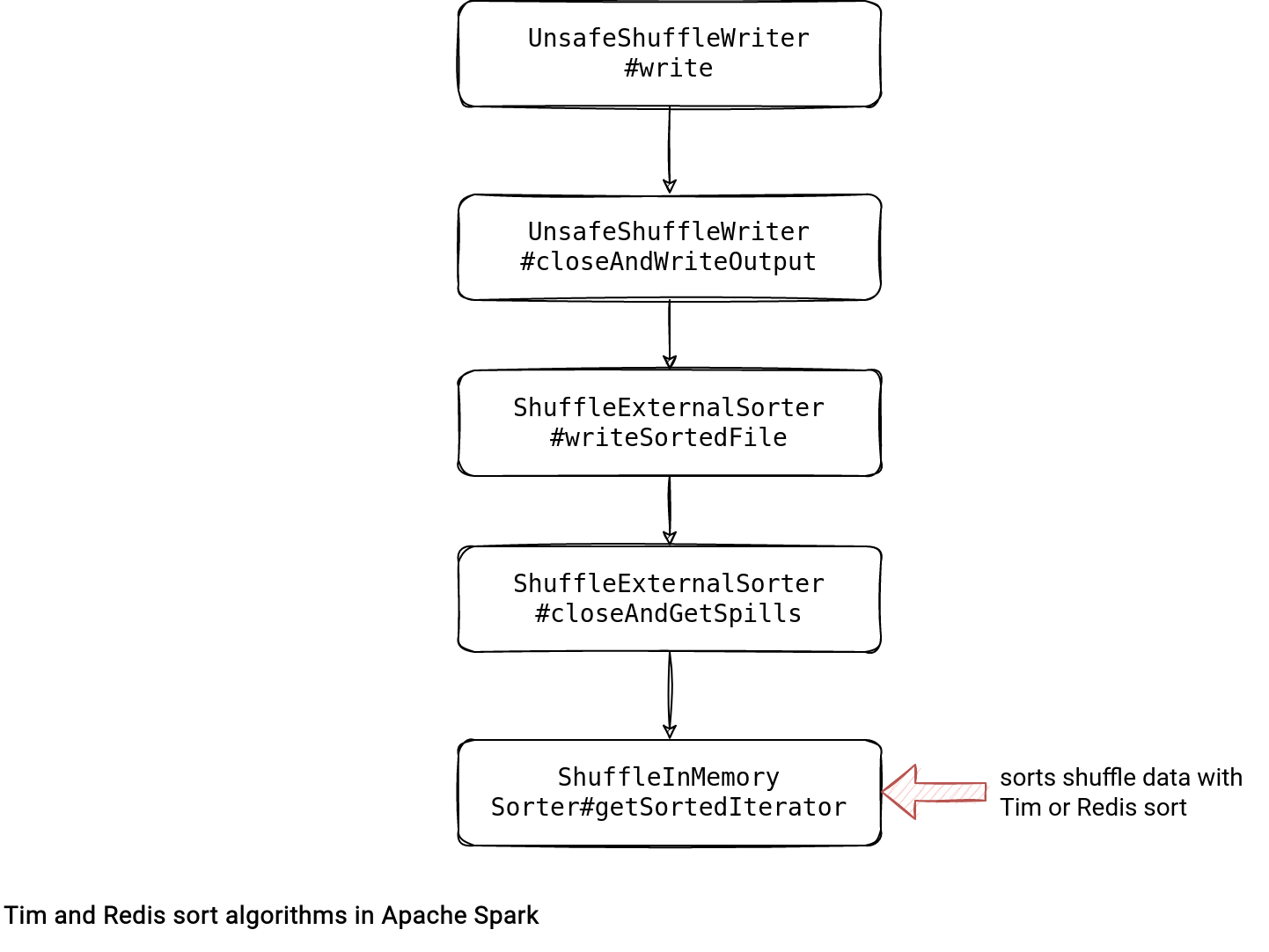
Even though the diagram above shows the write(scala.collection.Iterator<Product2<K, V>> records), so the one called to generate shuffle files, the sort doesn't happen for each element individually. Instead, it happens only for:
- The spilling due to the memory pressure has place. In that case, the writeSortedFile(boolean isLastFile) gets called with the isLastFile flag set to false.
- The spilling due to iterating the last shuffled record. In that scenario, the isLastFile flag is set to false.
Whenever one of them happens, the shuffle writer calls the Redix or Tim sort:
final class ShuffleInMemorySorter {
// ...
public ShuffleSorterIterator getSortedIterator() {
int offset = 0;
if (useRadixSort) {
offset = RadixSort.sort(
array, pos,
PackedRecordPointer.PARTITION_ID_START_BYTE_INDEX,
PackedRecordPointer.PARTITION_ID_END_BYTE_INDEX, false, false);
} else {
// ...
Sorter<PackedRecordPointer, LongArray> sorter =
new Sorter<>(new ShuffleSortDataFormat(buffer));
sorter.sort(array, 0, pos, SORT_COMPARATOR);
}
return new ShuffleSorterIterator(pos, array, offset);
}
The sorting doesn't operate on the records themselves. It works on an array storing the pairs of the shuffle partition id and the input row reference. However, technically, the sort applies only to the partition id, and there is no data access involved whatsoever.
Some numbers
Radix sort is enabled by default and there is a reason for that. When Eric Liang added this feature in SPARK-14724, he measured the impact on the existing benchmarking environment. He observed an overall improvement by ~10% for the TPCDS queries when the Radix sort was enabled.
Additionally, you can find the microbenchmark results showing better results for the Radix sort. For Apache Spark 3.1.2, the results look like:
================================================================================================ radix sort ================================================================================================ OpenJDK 64-Bit Server VM 1.8.0_282-b08 on Linux 5.4.0-1043-azure Intel(R) Xeon(R) CPU E5-2673 v4 @ 2.30GHz radix sort 25000000: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative ------------------------------------------------------------------------------------------------------------------------ reference TimSort key prefix array 13590 13887 420 1.8 543.6 1.0X reference Arrays.sort 3615 3644 40 6.9 144.6 3.8X radix sort one byte 501 505 3 49.9 20.1 27.1X radix sort two bytes 998 1011 21 25.1 39.9 13.6X radix sort eight bytes 3894 3912 26 6.4 155.8 3.5X radix sort key prefix array 7299 7316 23 3.4 292.0 1.9X
The sort algorithms don't evolve that often in Apache Spark. The previous major change comes from the 1.1 release when the framework switched from a quicksort to Tim sort. Another one was released in 2.0 with the Radix algorithm. It's nearly 1 change per major version. Should we expect something sort-related in Apache Spark 3.x.x? I haven't found any signs in the backlog yet but in case I missed something, feel free to share!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Radix and Tim sort here:
- Apache Spark the Fastest Open Source Engine for Sorting a Petabyte Understanding Timsort What Is Radix sort Algorithm: Pseudocode, Time Complexity, C Program & More
Related blog posts:
- Shuffle in PySpark
- Shuffle configuration demystified - part 2
- Shuffle configuration demystified - part 1
- Shuffle reading in Apache Spark SQL - wrapping iterators and beyond
- Shuffle reading in Apache Spark SQL
Tim and Radix are 2 sort algorithms available for shuffle files generation in #ApacheSpark You can discover them in the last blog post before "What's new in Apache Spark 3.3" series ? https://t.co/U8ujucdLrZ
— Bartosz Konieczny (@waitingforcode) June 18, 2022