
It's time for the 2 of 3 parts dedicated to the shuffle configuration in Apache Spark.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Data corruption
Well, maybe not this one. Most of the data corruption configs have been added recently, in Apache Spark 3.2.0. To start, it got spark.shuffle.checksum.enabled and spark.shuffle.checksum.algorithm to respectively, enable the checksum and define the used algorithm for the checksum generation. The checksum is generated as a file in the map shuffle task commit stage, inside the same method that generates the shuffle index file:
def writeMetadataFileAndCommit(shuffleId: Int, mapId: Long, lengths: Array[Long], checksums: Array[Long], dataTmp: File): Unit = {
val indexFile = getIndexFile(shuffleId, mapId)
val indexTmp = Utils.tempFileWith(indexFile)
// ...
checksumTmpOpt.zip(checksumFileOpt).foreach { case (checksumTmp, checksumFile) =>
try {
writeMetadataFile(checksums, checksumTmp, checksumFile, false)
} catch {
case e: Exception =>
// It's not worthwhile to fail here after index file and data file are
// already successfully stored since checksum is only a best-effort for
// the corner error case.
logError("Failed to write checksum file", e)
}
}
The enabled checksum also helps detect the block corruption reasons in the shuffle reading stage. When something wrong happens with the shuffle block reading, the reader generates the checksum for the streamed block and sends it to the node exposing the corrupted data. It later calls ShuffleChecksumHelper.diagnoseCorruption and checks whether the error may be a disk, network, or an unknown issue.
Besides these 2 new entries, the framework also has some old ones added in the version 2.2.0. The first of them is spark.shuffle.detectCorrupt and it enables data corruption in the fetched blocks. The second is spark.shuffle.detectCorrupt.useExtraMemory and extends the corruption detection to the large blocks by adding an early check. The method responsible for that will download the compressed block data and apply the copyStreamUpTo on the spark.reducer.maxSizeInFlight/3 bytes to check for corrupted parts:
private[spark]
final class ShuffleBlockFetcherIterator
// ...
override def next(): (BlockId, InputStream) = {
// ...
input = streamWrapper(blockId, in)
// If the stream is compressed or wrapped, then we optionally decompress/unwrap the
// first maxBytesInFlight/3 bytes into memory, to check for corruption in that portion
// of the data. But even if 'detectCorruptUseExtraMemory' configuration is off, or if
// the corruption is later, we'll still detect the corruption later in the stream.
streamCompressedOrEncrypted = !input.eq(in)
if (streamCompressedOrEncrypted && detectCorruptUseExtraMemory) {
// TODO: manage the memory used here, and spill it into disk in case of OOM.
input = Utils.copyStreamUpTo(input, maxBytesInFlight / 3)
}
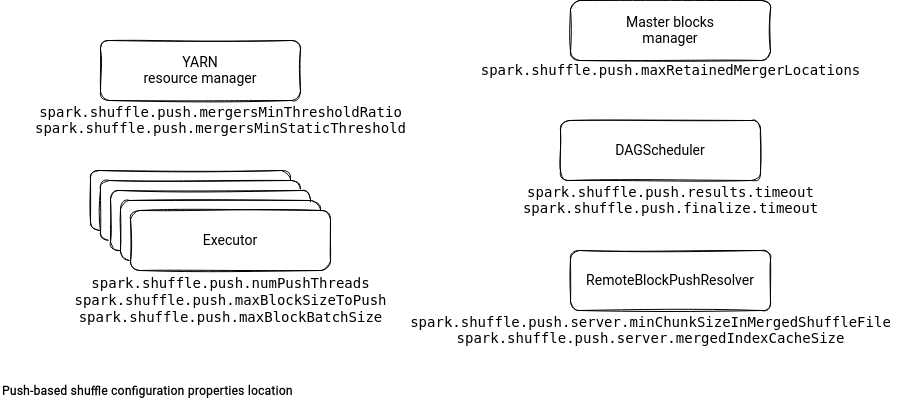
Push-based shuffle - mergers locations
The second category of properties concerns the push-based shuffle added in Apache Spark 3.2.0. The feature consists of merging shuffle files on a remote service to optimize the I/O throughput for TB and PB scenarios.
To enable the push-based shuffle you have to set the spark.shuffle.push.enabled property to true. In addition to it, you can also configure the shuffle context.
The first configuration group controls the number shuffle mergers. A shuffle merger is the physical node that will receive the shuffle push request for one or multiple shuffle ids. The first property used here is spark.shuffle.push.mergersMinThresholdRatio. It defaults to 5% and defines the ratio between the number of shuffle partitions and shuffle mergers. For example, the default number of shuffle partitions (200) will require at least 10 unique shuffle mergers locations.
Besides, the configuration also has a static number of shuffle locations set in the spark.shuffle.push.mergersMinStaticThreshold entry. YARN scheduler uses these two properties as follows:
private[spark] abstract class YarnSchedulerBackend(scheduler: TaskSchedulerImpl, sc: SparkContext) extends CoarseGrainedSchedulerBackend(scheduler, sc.env.rpcEnv) {
// ...
override def getShufflePushMergerLocations(
numPartitions: Int,
resourceProfileId: Int): Seq[BlockManagerId] = {
//...
val tasksPerExecutor = sc.resourceProfileManager
.resourceProfileFromId(resourceProfileId).maxTasksPerExecutor(sc.conf)
val numMergersDesired = math.min(
math.max(1, math.ceil(numPartitions / tasksPerExecutor).toInt), maxExecutors)
val minMergersNeeded = math.max(minMergersStaticThreshold,
math.floor(numMergersDesired * minMergersThresholdRatio).toInt)
The aforementioned properties define the minimum numbers of merger locations. The max is present in spark.shuffle.push.maxRetainedMergerLocations. This property controls the number of the host and shuffle merger service mapping pairs stored in the cache on the master block manager. It can also act as a cache eviction mechanism because whenever a new location is proposed and the cache is full, the most recent entry will be removed:
private[spark]
class BlockManagerMasterEndpoint(override val rpcEnv: RpcEnv, val isLocal: Boolean, conf: SparkConf, listenerBus: LiveListenerBus, externalBlockStoreClient: Option[ExternalBlockStoreClient], blockManagerInfo: mutable.Map[BlockManagerId, BlockManagerInfo], mapOutputTracker: MapOutputTrackerMaster, isDriver: Boolean) extends IsolatedRpcEndpoint with Logging {
private val shuffleMergerLocations = new mutable.LinkedHashMap[String, BlockManagerId]()
private def addMergerLocation(blockManagerId: BlockManagerId): Unit = {
if (!blockManagerId.isDriver && !shuffleMergerLocations.contains(blockManagerId.host)) {
val shuffleServerId = BlockManagerId(BlockManagerId.SHUFFLE_MERGER_IDENTIFIER,
blockManagerId.host, externalShuffleServicePort)
if (shuffleMergerLocations.size >= maxRetainedMergerLocations) {
shuffleMergerLocations -= shuffleMergerLocations.head._1
}
shuffleMergerLocations(shuffleServerId.host) = shuffleServerId
}
}
Additionally, it also impacts the push-based shuffle itself. If the number of cached merger locations is smaller than the minMergersNeeded from the previous snippet, YARN will return an empty list in the getShufflePushMergerLocations method:
private[spark] abstract class YarnSchedulerBackend(scheduler: TaskSchedulerImpl, sc: SparkContext) extends CoarseGrainedSchedulerBackend(scheduler, sc.env.rpcEnv) {
// ...
override def getShufflePushMergerLocations(
numPartitions: Int,
resourceProfileId: Int): Seq[BlockManagerId] = {
// …
// Request for numMergersDesired shuffle mergers to BlockManagerMasterEndpoint
// and if it's less than minMergersNeeded, we disable push based shuffle.
val mergerLocations = blockManagerMaster
.getShufflePushMergerLocations(numMergersDesired, scheduler.excludedNodes())
if (mergerLocations.size < numMergersDesired && mergerLocations.size < minMergersNeeded) {
Seq.empty[BlockManagerId]
} else {
logDebug(s"The number of shuffle mergers desired ${numMergersDesired}" +
s" and available locations are ${mergerLocations.length}")
mergerLocations
}
}
Push-based shuffle - push
Besides the mergers locations properties, Apache Spark also configures the push process. To start, you can define the number of threads that will push shuffle blocks to the mergers locations in the spark.shuffle.push.numPushThreads. By default, the process will use all executor cores.
In the spark.shuffle.push.maxBlockSizeToPush the push process controls the allowed size of the block to push. If the block is bigger than this value, the reducers will have to fetch it the usual way.
The spark.shuffle.push.maxBlockBatchSize defines the maximal size of the push merge request. Hence, it specifies how many blocks will be sent to the shuffle merger in a single request. Since the feature was designed to handle the issue of many small shuffle blocks, these 2 configuration properties have relatively small values which are 1MB for maxBlockSizeToPush and 3MB for maxBlockBatchSize.
Push-based shuffle - the driver
Let's terminate this 2nd part with a short section dedicated to the driver, and more exactly to the DAGScheduler class. When all shuffle map tasks terminate, the scheduler will trigger the shuffle merge finalization task. But instead of running immediately, the start time will be delayed by spark.shuffle.push.finalize.timeout seconds.
Once this delay passes, the DAGScheduler will start the finalization by asking all mappers to finalize the merge process. The mappers have up to spark.shuffle.push.results.timeout to return a response. After that time, DAGScheduler will continue its work and set up the reducer stage. The non merged blocks will be simply ignored and fetched the old way.
Push-based shuffle - the servers
Besides the already presented push-based shuffle configurations, you will find some of them prefixed by the spark.shuffle.push.server in the network package.
The spark.shuffle.push.server.mergedShuffleFileManagerImpl is the first property from this server family. It defines the class implementing the MergedShuffleFileManager interface that is going to be responsible for merging pushed shuffle files. To enable the feature, this property must be set to org.apache.spark.network.shuffle.RemoteBlockPushResolver.
The manager uses two other attributes. The spark.shuffle.push.server.minChunkSizeInMergedShuffleFile indicates the minimum size of the chunk served from the merged shuffle file. The spark.shuffle.push.server.mergedIndexCacheSize defines the size of the cache storing the index merge files. The merged data reading process uses these files to get the offsets to return:
public class RemoteBlockPushResolver implements MergedShuffleFileManager {
// ...
@Override
public ManagedBuffer getMergedBlockData(
String appId, int shuffleId, int shuffleMergeId, int reduceId, int chunkId) {
// ...
// If we get here, the merged shuffle file should have been properly finalized. Thus we can
// use the file length to determine the size of the merged shuffle block.
ShuffleIndexInformation shuffleIndexInformation = indexCache.get(indexFile);
ShuffleIndexRecord shuffleIndexRecord = shuffleIndexInformation.getIndex(chunkId);
return new FileSegmentManagedBuffer(
conf, dataFile, shuffleIndexRecord.getOffset(), shuffleIndexRecord.getLength());
Initially, I wanted to include 2 more configuration families here but the article would end up being too long. That's why you will see the last part of shuffle configuration entries next week!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Shuffle configuration demystified - part 2 here:
Related blog posts:
- Shuffle in PySpark
- Radix and Tim sort
- Shuffle configuration demystified - part 1
- Shuffle reading in Apache Spark SQL - wrapping iterators and beyond
- Shuffle reading in Apache Spark SQL
Data corruption in shuffle files? It's another configuration property, covered alongside the push-based shuffle in the new #ApacheSpark blog post ? https://t.co/OSPmbxRoVM
— Bartosz Konieczny (@waitingforcode) March 19, 2022