
So far I've covered the writing part of the shuffle files. You've learned about 3 different shuffle writers, but what happens with their generated files? Who and how reads them? Is the reading an in-memory operation? I will try to answer this and some other questions in this blog post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
ShuffleRowRDD
I did mention "Apache Spark SQL" in the title of this article on purpose. Apache Spark has 2 abstractions responsible for dealing with shuffle files, the ShuffledRDD and ShuffleRowRDD. The former one interacts with the RDD API whereas the latter one with the Dataset API. Since the Dataset API is a recommended way to go in most of the cases, I've decided to focus only on it.
The ShuffleRowRDD is created by ShuffleExchangeExec with the following parameters:
class ShuffledRowRDD(
var dependency: ShuffleDependency[Int, InternalRow, InternalRow],
metrics: Map[String, SQLMetric],
partitionSpecs: Array[ShufflePartitionSpec])
The first important attribute is the ShuffleDependency instance. It brings the shuffle id parameter with an internal ShuffleHandle field. The second important attribute is the partitionSpecs array. It defines the type of the shuffle partitions which can be:
- CoalescedPartitionSpec used in coalesce shuffle partitions logical rule; I blogged about that in What's new in Apache Spark 3.0 - shuffle partitions coalesce
- PartialReducerPartitionSpec involved in the skew join optimization; I also blogged about that in What's new in Apache Spark 3.0 - join skew optimization
- PartialMapperPartitionSpec implemented in the local shuffle reader; I explained this feature in what's new in Apache Spark 3.0 - local shuffle reader
The partition specifications are important because they will define the shuffle reader's behavior. Technically speaking, they all share the same reader type which is an instance of ShuffleReader[K, C] but depending on the shuffle type, the reader will get different parameters:
- CoalescedPartitionSpec(startReducerIndex: Int, endReducerIndex: Int) reads all shuffle files generated by each map task for 1 or more reducers
- PartialReducerPartitionSpec(reducerIndex: Int, startMapIndex: Int, endMapIndex: Int) reads partial data for a reducer (= a part of its shuffle map files)
- PartialMapperPartitionSpec(mapIndex: Int, startReducerIndex: Int, endReducerIndex: Int) reads a part of shuffle map files (= between startReducerIndex and endReducerIndex)
Reader initialization
By calling SparkEnv.get.shuffleManager.getReader, the ShuffleRowRDD calls the SortShuffleManager. It does 2 things. First, it identifies the location of the shuffle blocks to fetch. It does it with the map output tracker component that I will detail in the next section. After that, the manager creates an instance of BlockStoreShuffleReader that will be responsible for passing shuffle files from the mappers to the reducer task.
The ShuffleRowRDD uses the read() method to iterate over the shuffle data and return it to the client's code:
class ShuffledRowRDD(
var dependency: ShuffleDependency[Int, InternalRow, InternalRow],
metrics: Map[String, SQLMetric],
partitionSpecs: Array[ShufflePartitionSpec])
extends RDD[InternalRow](dependency.rdd.context, Nil) {
override def compute(split: Partition, context: TaskContext): Iterator[InternalRow] = {
val tempMetrics = context.taskMetrics().createTempShuffleReadMetrics()
// `SQLShuffleReadMetricsReporter` will update its own metrics for SQL exchange operator,
// as well as the `tempMetrics` for basic shuffle metrics.
val sqlMetricsReporter = new SQLShuffleReadMetricsReporter(tempMetrics, metrics)
val reader = split.asInstanceOf[ShuffledRowRDDPartition].spec match {
// ...
reader.read().asInstanceOf[Iterator[Product2[Int, InternalRow]]].map(_._2)
}
Map output tracker
Apache Spark has 2 map output trackers. The first of them is MapOutputTrackerMaster. It resides in the driver and keeps track of the map outputs for each stage. It mainly communicates with DAGScheduler:
- DAGScheduler calls def registerShuffle(shuffleId: Int, numMaps: Int) when it creates a shuffle map stage - as the method indicates, the tracker will create a new ShuffleStatus(numPartitions: Int) instance for the corresponding shuffle step; numPartition represents here the number of map partitions:
private[spark] class DAGScheduler { def createShuffleMapStage[K, V, C]( shuffleDep: ShuffleDependency[K, V, C], jobId: Int): ShuffleMapStage = { val rdd = shuffleDep.rdd // ... if (!mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) { // Kind of ugly: need to register RDDs with the cache and map output tracker here // since we can't do it in the RDD constructor because # of partitions is unknown logInfo(s"Registering RDD ${rdd.id} (${rdd.getCreationSite}) as input to " + s"shuffle ${shuffleDep.shuffleId}") mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length) } } private[spark] class MapOutputTrackerMaster { def registerShuffle(shuffleId: Int, numMaps: Int): Unit = { if (shuffleStatuses.put(shuffleId, new ShuffleStatus(numMaps)).isDefined) { throw new IllegalArgumentException("Shuffle ID " + shuffleId + " registered twice") } } - so far, the tracker only knows that there is a shuffle somewhere in the execution plan; it doesn't know where the shuffle files live. Every time a task from the shuffle map stage terminates, the DAGScheduler sends a status update to the master MapOutputTrackerMaster. The tracker adds the information about the location and size for the particular shuffle file to the shuffleStatuses map initialized in the registration step:
private[spark] class DAGScheduler { private[scheduler] def handleTaskCompletion(event: CompletionEvent): Unit = { // ... event.reason match { case Success => case smt: ShuffleMapTask => val shuffleStage = stage.asInstanceOf[ShuffleMapStage] // ... // The epoch of the task is acceptable (i.e., the task was launched after the most // recent failure we're aware of for the executor), so mark the task's output as // available. mapOutputTracker.registerMapOutput( shuffleStage.shuffleDep.shuffleId, smt.partitionId, status) } } private[spark] class MapOutputTrackerMaster { def registerMapOutput(shuffleId: Int, mapIndex: Int, status: MapStatus): Unit = { shuffleStatuses(shuffleId).addMapOutput(mapIndex, status) } }
The second map output tracker is MapOutputTrackerWorker, located on the executors. It's responsible for fetching the shuffle metadata information from the master tracker. It happens when the worker tracker hasn't cached the shuffle information and has to send a GetMapOutputStatuses message to get it. The shuffle information contains a list of MapStatus. Each item defines the physical location and map task id. Thanks to this list, the tracker can communicate the fetchable elements to the shuffle reader:
class BlockManagerId private (
private var executorId_ : String,
private var host_ : String,
private var port_ : Int,
private var topologyInfo_ : Option[String])
private[spark] sealed trait MapStatus {
def location: BlockManagerId
// ...
def mapId: Long
}
private[spark] class MapOutputTrackerWorker(conf: SparkConf) extends MapOutputTracker(conf) {
private def getStatuses(shuffleId: Int, conf: SparkConf): Array[MapStatus] = {
/// ...
val statuses = mapStatuses.get(shuffleId).orNull
if (statuses == null) {
fetchingLock.withLock(shuffleId) {
var fetchedStatuses = mapStatuses.get(shuffleId).orNull
if (fetchedStatuses == null) {
logInfo("Doing the fetch; tracker endpoint = " + trackerEndpoint)
val fetchedBytes = askTracker[Array[Byte]](GetMapOutputStatuses(shuffleId))
fetchedStatuses = MapOutputTracker.deserializeMapStatuses(fetchedBytes, conf)
logInfo("Got the output locations")
mapStatuses.put(shuffleId, fetchedStatuses)
}
fetchedStatuses
// ...
}
}
The fetched information is passed to the BlockStoreShuffleReader as a list of shuffle blocks with their physical locations:
private[spark] class SortShuffleManager(conf: SparkConf) extends ShuffleManager with Logging {
override def getReader[K, C](
handle: ShuffleHandle,
startMapIndex: Int, endMapIndex: Int, startPartition: Int, endPartition: Int,
context: TaskContext,
metrics: ShuffleReadMetricsReporter): ShuffleReader[K, C] = {
val blocksByAddress = SparkEnv.get.mapOutputTracker.getMapSizesByExecutorId(
handle.shuffleId, startMapIndex, endMapIndex, startPartition, endPartition)
new BlockStoreShuffleReader(
handle.asInstanceOf[BaseShuffleHandle[K, _, C]], blocksByAddress, context, metrics,
shouldBatchFetch = canUseBatchFetch(startPartition, endPartition, context))
}
BlockStoreShuffleReader
At this point Apache Spark only knows the shuffle metadata. But thanks to it, it can now pass to the physical reading in the BlockStoreShuffleReader class. The reader initializes an instance of ShuffleBlockFetcherIterator that will be responsible for getting shuffle blocks from executors (external shuffle service is not covered in this blog post):
private[spark] class BlockStoreShuffleReader[K, C] {
// ...
override def read(): Iterator[Product2[K, C]] = {
val wrappedStreams = new ShuffleBlockFetcherIterator( /* ... */ )
val recordIter = wrappedStreams.flatMap { case (blockId, wrappedStream) =>
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
// ...
The BlockStoreShuffleReader has a few more lines with other iterators wrapping the raw shuffle data. However, to not make this article too long, I will cover this part in a follow-up blog post. Here, I'll only focus on the physical data retrieval, so on the ShuffleBlockFetcherIterator.
ShuffleBlockFetcherIterator
The first important observation about this iterator is the configuration. The constructor takes various configuration parameters to control the number of fetch calls. These controls are size-based (max size of pending reads in bytes) and count-based (max number of the pending fetch requests, max number of pending requests for every remote host), and memory-based (the max number of shuffle data to keep in memory).
When the shuffle reader creates the instance of the ShuffleBlockFetcherIterator, the iterator calls an initialization step defined in its initialize() method. It starts by defining a list of fetch requests from the list of blocksByAddress got from the map output tracker. Depending on the block storage - local or remote host - the block request can be skipped because the iterator will read the shuffle data directly from disk. The requests executed on a remote node are later randomly shuffled (BTW, you know why the shuffle retrieval is not deterministic!) and saved into val fetchRequests = new Queue[FetchRequest]:
private[this] def initialize(): Unit = {
// ...
// Partition blocks by the different fetch modes: local, host-local and remote blocks.
val remoteRequests = partitionBlocksByFetchMode()
// Add the remote requests into our queue in a random order
fetchRequests ++= Utils.randomize(remoteRequests)
After building the list of fetch requests, the iterator will start the first reading loop that will stop after reading the max number of in-flight bytes to read or pending requests.
Fetching
The physical fetching happens in the fetchUpToMaxBytes() and it consists in:
- processing deferred requests, if any - the iterator considers a request as deferred when the request applies on the overloaded executor. In other words, the total number of in-flight bytes or pending requests is not reached but the max number of pending connections for the executor is.
- processing normal requests, if the total limits of requests and in-flight bytes aren't reached - the fetching starts by taking the next available request to fetch from the list constructed in the previous step. The iterator takes the next request to process from the fetchRequests queue:
private def fetchUpToMaxBytes(): Unit = { // ... while (isRemoteBlockFetchable(fetchRequests)) { val request = fetchRequests.dequeue()Later, it verifies whether the request should be considered as deferred. If yes, it's added to a deferredFetchRequests. Otherwise, it continues and sends the request from the BlockStoreClient implementation (ExternalBlockStoreClient if shuffle service enabled, NettyBlockTransferService otherwise)
The client runs the fetching process in fetchBlocks() method with the help of another class called OneForOneBlockFetcher. Since there is a lot of going and comings between the classes, I will detail the algorithm in the list below:
- in the ShuffleBlockFetcherIterator's sendRequest(req: FetchRequest) method, the iterator creates a BlockFetchingListener that will be called after completing the request. For a successful execution, it will add block data to results variable. If an error happens, it will add a marker class indicating the fetching failure:
private[this] def sendRequest(req: FetchRequest): Unit = { // ... val blockFetchingListener = new BlockFetchingListener { override def onBlockFetchSuccess(blockId: String, buf: ManagedBuffer): Unit = { // ... remainingBlocks -= blockId results.put(new SuccessFetchResult(BlockId(blockId), infoMap(blockId)._2, address, infoMap(blockId)._1, buf, remainingBlocks.isEmpty)) // ... } override def onBlockFetchFailure(blockId: String, e: Throwable): Unit = { results.put(new FailureFetchResult(BlockId(blockId), infoMap(blockId)._2, address, e)) } }
Remember this results variable. We'll need it in the next section. - later, the iterator sends the fetch request by optionally defining an DownloadFileManager if the request size exceeds the max size of a request that can be stored in memory:
private[this] def sendRequest(req: FetchRequest): Unit = { // ... if (req.size > maxReqSizeShuffleToMem) { shuffleClient.fetchBlocks(address.host, address.port, address.executorId, blockIds.toArray, blockFetchingListener, this) } else { shuffleClient.fetchBlocks(address.host, address.port, address.executorId, blockIds.toArray, blockFetchingListener, null) } }If the manager is present, the shuffle data will be downloaded to a temporary file.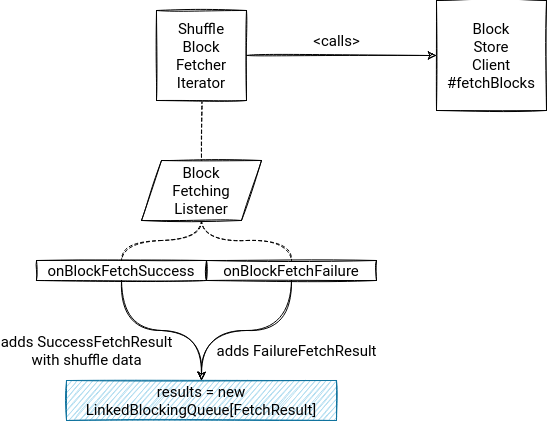
- I'm focusing here on the fetchBlocks implemented by NettyBlockTransferService, so the one used without the external shuffle service. It'll initialize an instance of RetryingBlockFetcher that will load shuffle files in this snippet:
override def fetchBlocks(host: String, port: Int, execId: String, blockIds: Array[String], listener: BlockFetchingListener, tempFileManager: DownloadFileManager) { // ... val blockFetchStarter = new RetryingBlockFetcher.BlockFetchStarter { override def createAndStart(blockIds: Array[String], listener: BlockFetchingListener): Unit = { try { val client = clientFactory.createClient(host, port, maxRetries > 0) new OneForOneBlockFetcher(client, appId, execId, blockIds, listener, transportConf, tempFileManager).start() } catch { - OneForOneBlockFetcher will be then responsible for the physical download of the shuffle data. But it's not a simple process. First, the fetcher will send a FetchShuffleBlocks message to the executor holding the shuffle files.
The executor will later register a new stream and return a StreamHandle message to the fetcher. The handle message has a streamId field related to the caller's socket:class NettyBlockRpcServer() { override def receive(client: TransportClient, rpcMessage: ByteBuffer, responseContext: RpcResponseCallback): Unit = { case fetchShuffleBlocks: FetchShuffleBlocks => // … val blocks = fetchShuffleBlocks.mapIds.zipWithIndex.flatMap { case (mapId, index) => if (!fetchShuffleBlocks.batchFetchEnabled) { fetchShuffleBlocks.reduceIds(index).map { reduceId => blockManager.getLocalBlockData( ShuffleBlockId(fetchShuffleBlocks.shuffleId, mapId, reduceId)) } } else { val startAndEndId = fetchShuffleBlocks.reduceIds(index) if (startAndEndId.length != 2) { throw new IllegalStateException(s"Invalid shuffle fetch request when batch mode " + s"is enabled: $fetchShuffleBlocks") } Array(blockManager.getLocalBlockData( ShuffleBlockBatchId( fetchShuffleBlocks.shuffleId, mapId, startAndEndId(0), startAndEndId(1)))) } } val numBlockIds = if (fetchShuffleBlocks.batchFetchEnabled) { fetchShuffleBlocks.mapIds.length } else { fetchShuffleBlocks.reduceIds.map(_.length).sum } val streamId = streamManager.registerStream(appId, blocks.iterator.asJava, client.getChannel) logTrace(s"Registered streamId $streamId with $numBlockIds buffers") responseContext.onSuccess( new StreamHandle(streamId, numBlockIds).toByteBuffer) - upon getting the StreamHandle response, the client will stream or load chunks:
for (int i = 0; i < streamHandle.numChunks; i++) { if (downloadFileManager != null) { client.stream(OneForOneStreamManager.genStreamChunkId(streamHandle.streamId, i), new DownloadCallback(i)); } else { client.fetchChunk(streamHandle.streamId, i, chunkCallback); } - for the case involving file manager, the result will be written to a temporary file; for the in-memory scenario, the shuffle bytes will go to an in-memory buffer. An interesting fact is that both will call the BlockFetchingListener defined in the ShuffleBlockFetcherIterator. The version using temporary files will do it from this place:
private class DownloadCallback implements StreamCallback { private DownloadFileWritableChannel channel = null; private DownloadFile targetFile = null; private int chunkIndex; DownloadCallback(int chunkIndex) throws IOException { this.targetFile = downloadFileManager.createTempFile(transportConf); this.channel = targetFile.openForWriting(); this.chunkIndex = chunkIndex; } @Override public void onData(String streamId, ByteBuffer buf) throws IOException { while (buf.hasRemaining()) { channel.write(buf); } } @Override public void onComplete(String streamId) throws IOException { listener.onBlockFetchSuccess(blockIds[chunkIndex], channel.closeAndRead()); if (!downloadFileManager.registerTempFileToClean(targetFile)) { targetFile.delete(); } }Whereas the in-memory version will do it from this callback:private class ChunkCallback implements ChunkReceivedCallback { @Override public void onSuccess(int chunkIndex, ManagedBuffer buffer) { listener.onBlockFetchSuccess(blockIds[chunkIndex], buffer); } }
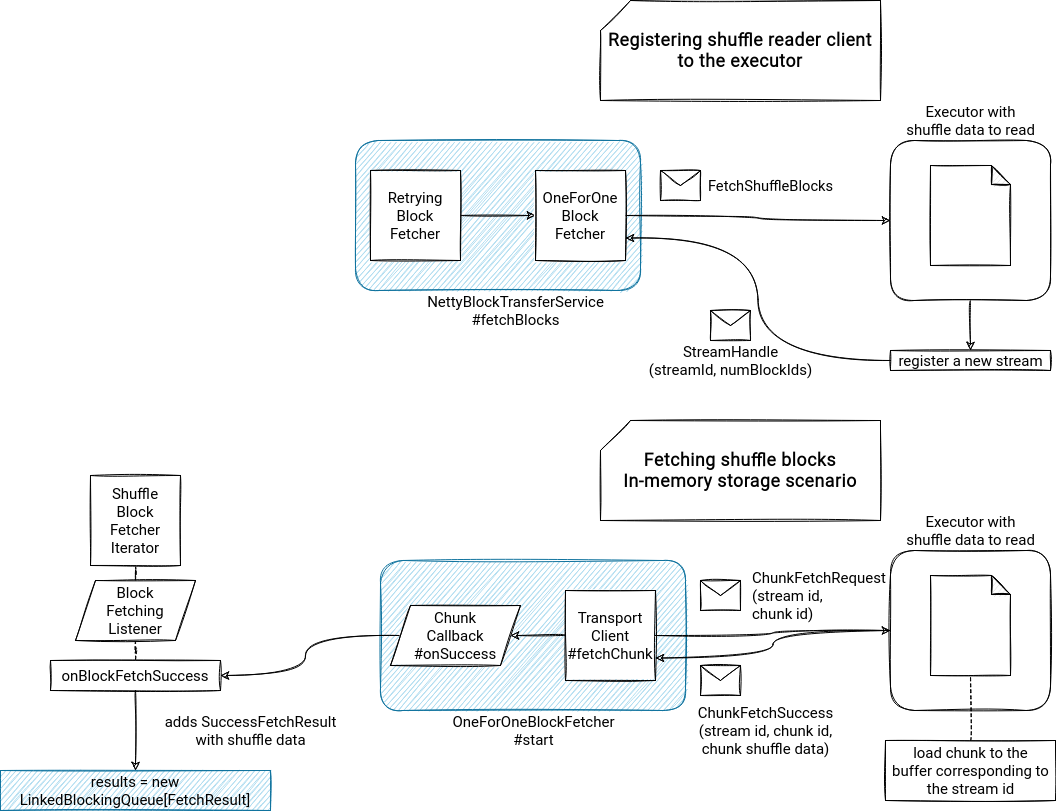
Fetched shuffle data is later put to the private[this] val results = new LinkedBlockingQueue[FetchResult] and returned to the caller from the next() method. If all available block data was already consumed, the iterator will execute the fetchUpToMaxBytes() presented before:
override def next(): (BlockId, InputStream) = {
if (!hasNext) {
throw new NoSuchElementException()
}
numBlocksProcessed += 1
var result: FetchResult = null
var input: InputStream = null
var streamCompressedOrEncrypted: Boolean = false
while (result == null) {
val startFetchWait = System.nanoTime()
result = results.take()
val fetchWaitTime = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startFetchWait)
shuffleMetrics.incFetchWaitTime(fetchWaitTime)
result match {
case r @ SuccessFetchResult(blockId, mapIndex, address, size, buf, isNetworkReqDone) =>
// ...
}
case FailureFetchResult(blockId, mapIndex, address, e) =>
throwFetchFailedException(blockId, mapIndex, address, e)
}
// Send fetch requests up to maxBytesInFlight
fetchUpToMaxBytes()
}
currentResult = result.asInstanceOf[SuccessFetchResult]
(currentResult.blockId,
new BufferReleasingInputStream(
input,
this,
currentResult.blockId,
currentResult.mapIndex,
currentResult.address,
detectCorrupt && streamCompressedOrEncrypted))
}
And I will stop here for today. As you can see, shuffle reading is not a straightforward action. It involves a lot of components controlling the executed logic and RPC calls. In the next blog post I'll focus on the part using the fetched shuffle blocks.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Shuffle in PySpark
- Radix and Tim sort
- Shuffle configuration demystified - part 2
- Shuffle configuration demystified - part 1
- Shuffle reading in Apache Spark SQL - wrapping iterators and beyond
So far I only wrote about shuffle file generation in #ApacheSpark. But the reading part is also interesting and I decided to catch up on it in the new blog post post ? https://t.co/G8bIQ4wu9L
— Bartosz Konieczny (@waitingforcode) August 14, 2021