
Shuffle partitions coalesce is not the single optimization introduced with the Adaptive Query Execution. Another one, addressing maybe one of the most disliked issues in data processing, is joins skew optimization that you will discover in this blog post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The structure of the article is the same as for the one about the coalesce. It starts with a short illustration of the problem. Later on, you can discover the configuration options involved in the optimization. Just after, you will see the skew optimization algorithm and its execution. In the last part, you will see a short demo of the feature.
Why?
I already described the problem of the skewed data. That's why here, I will shortly recall it. We say that we deal with skew problems when one partition of the dataset is much bigger than the others and that we need to combine one dataset with another. In the before-mentioned scenario, the skewed partition will have an impact on the network traffic and on the task execution time, since this particular task will have much more data to process.
All methods to deal with data skew in Apache Spark 2 were mainly manual. You could configure spark.sql.shuffle.partitions to balance the data more evenly. You could also play with the configuration and try to prefer broadcast join instead of the sort-merge join. Finally, you could also alter the skewed keys and change their distribution. But all of these methods required some human intervention. The join skew optimization does not and appears therefore as an easier alternative to put in place.
Configuration
Regarding the configuration, the first important entry is spark.sql.adaptive.skewJoin.enabled and as the name indicates, it enables or disables the skew optimization.
Next to it, you will retrieve 2 very important properties used to define whether a shuffle partition is skewed or not. The first of them is spark.sql.adaptive.skewJoin.skewedPartitionFactor and it controls the max size of non skewed partition:
size > medianSize * conf.getConf(SQLConf.SKEW_JOIN_SKEWED_PARTITION_FACTOR)
The second property is spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes and it also checks whether a shuffle partition is skewed or not:
size > conf.getConf(SQLConf.SKEW_JOIN_SKEWED_PARTITION_THRESHOLD)
Both tests are defined inside isSkewed(size: Long, medianSize: Long) method and if they're both true, the shuffle partition is considered as skewed.
The final property from the list is the one you already met in the previous article, the spark.sql.adaptive.advisoryPartitionSizeInBytes. It's used as a fallback value to define the targeted size of the shuffle partition after the optimization:
private def targetSize(sizes: Seq[Long], medianSize: Long): Long = {
val advisorySize = conf.getConf(SQLConf.ADVISORY_PARTITION_SIZE_IN_BYTES)
val nonSkewSizes = sizes.filterNot(isSkewed(_, medianSize))
// It's impossible that all the partitions are skewed, as we use median size to define skew.
assert(nonSkewSizes.nonEmpty)
math.max(advisorySize, nonSkewSizes.sum / nonSkewSizes.length)
}
Algorithm
The algorithm executes when all these conditions are met:
- skew join optimization is enabled with the configuration entry mentioned previously
- the query has only 2 joins - according to the code, with more than 2, there will be too many complex combinations to consider
- the optimized plan doesn't involve an extra shuffle stage - if it happens, the not optimized plan is preferred:
val optimizePlan = optimizeSkewJoin(plan) val numShuffles = ensureRequirements.apply(optimizePlan).collect { case e: ShuffleExchangeExec => e }.length if (numShuffles > 0) { logDebug("OptimizeSkewedJoin rule is not applied due" + " to additional shuffles will be introduced.") plan } - join is a sort merge join for one of the supported types (inner, left outer, right outer, cross, left anti, left semi)
- both datasets have the same number of shuffle partitions
- at least one of the sides have skews:
logDebug("number of skewed partitions: " + s"left ${leftSkewDesc.numPartitions}, right ${rightSkewDesc.numPartitions}") if (leftSkewDesc.numPartitions > 0 || rightSkewDesc.numPartitions > 0) { val newLeft = CustomShuffleReaderExec( left.shuffleStage, leftSidePartitions, leftSkewDesc.toString) val newRight = CustomShuffleReaderExec( right.shuffleStage, rightSidePartitions, rightSkewDesc.toString) smj.copy( left = s1.copy(child = newLeft), right = s2.copy(child = newRight), isSkewJoin = true) } else { smj }
What happens during the skew detection? First, the algorithm computes the median size for all partitions on every join side. After that, the targeted size for the partition is generated with the function mentioned in the previous section, involving advisory partition size configuration. Once resolved, the algorithm starts the iteration over all partitions.
In every iteration, the algorithm:
- verifies which of both sides is skewed
- checks whether left and right sides of the join were coalesced
val isLeftCoalesced = leftPartSpec.startReducerIndex + 1 < leftPartSpec.endReducerIndex val isRightCoalesced = rightPartSpec.startReducerIndex + 1 < rightPartSpec.endReducerIndex
If one of the sides was coalesced before, the skew optimization is skipped for the partition:val leftPartSpec = left.partitionsWithSizes(partitionIndex)._1 val leftParts = if (isLeftSkew && !isLeftCoalesced) { // ... skew optimization } else { Seq(leftPartSpec) } - if the skew exists and the partition wasn't coalesced, the createSkewPartitionSpecs is called and since it's the main logic of the skew management, you will discover it outside the bullet list
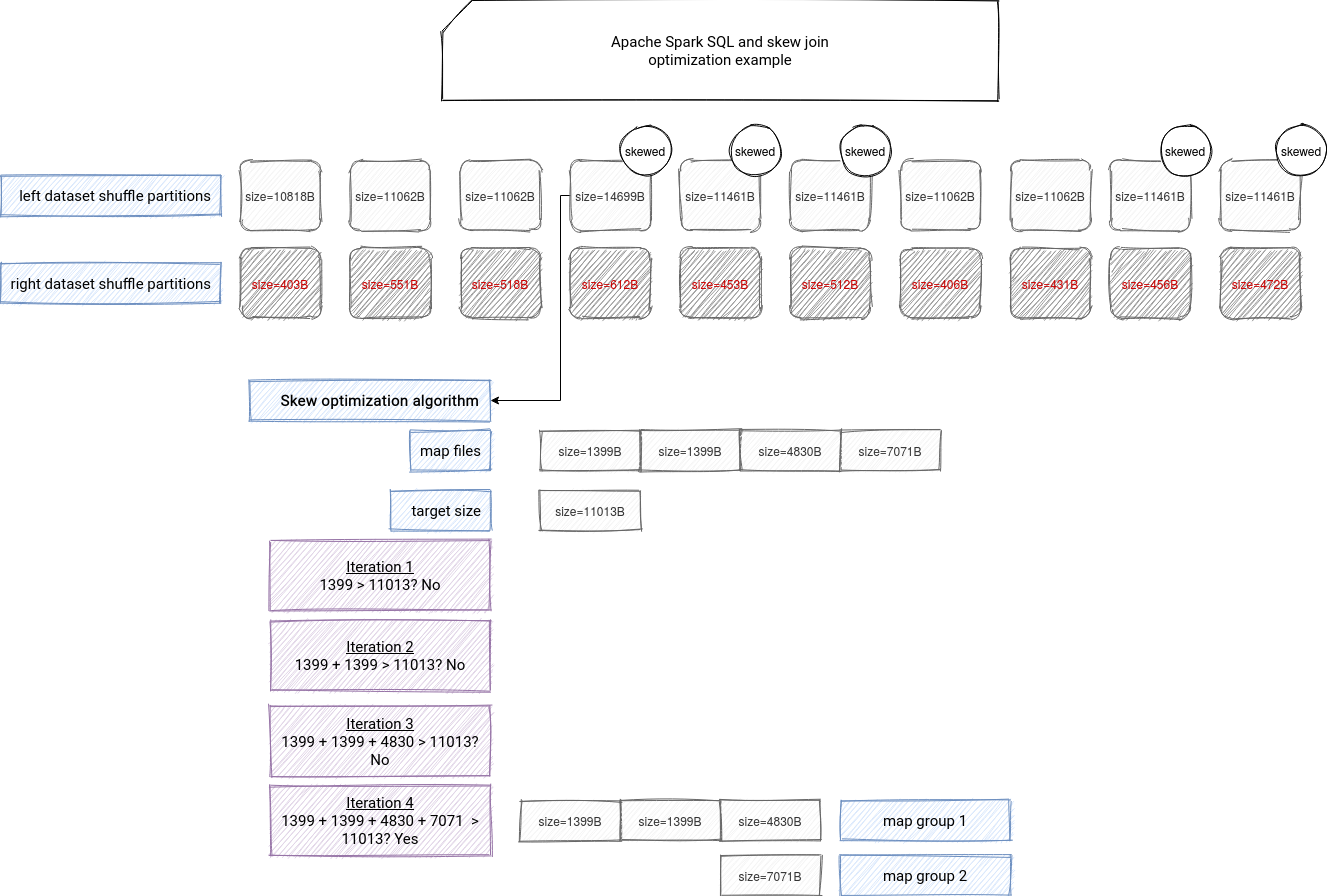
So, what happens in this createSkewPartitionSpecs method? First, it retrieves the size for the map files for given reducer and passes it to ShufflePartitionsUtil.splitSizeListByTargetSize method to split them into new parallel tasks:
val mapPartitionSizes = getMapSizesForReduceId(shuffleId, reducerId)
val mapStartIndices = ShufflePartitionsUtil.splitSizeListByTargetSize(
mapPartitionSizes, targetSize)
The split action consists on iterating over all map files and creating a new map group when the size of consecutive map files reaches the targeted size of the partition:
def splitSizeListByTargetSize(sizes: Seq[Long], targetSize: Long): Array[Int] = {
// …
val partitionStartIndices = ArrayBuffer[Int]()
partitionStartIndices += 0
while (i < sizes.length) {
// If including the next size in the current partition exceeds the target size, package the
// current partition and start a new partition.
if (i > 0 && currentPartitionSize + sizes(i) > targetSize) {
tryMergePartitions()
partitionStartIndices += i
currentPartitionSize = sizes(i)
} else {
currentPartitionSize += sizes(i)
}
i += 1
}
tryMergePartitions()
partitionStartIndices.toArray
As you can see in the snippet, in addition to map groups creation, the method can also merge small partitions with tryMergePartitions. Anyway, the function returns a list of the indices that will be used to create map group files represented by PartialReducerPartitionSpec(reducerId, startMapIndex, endMapIndex). You can find an illustration for this part in the image below:
After the iteration over the partitions, both sides are wrapped with the new node, CustomShuffleReaderExec, and the sort merge join node has the isSkewJoin set to true:
val newLeft = CustomShuffleReaderExec(
left.shuffleStage, leftSidePartitions, leftSkewDesc.toString)
val newRight = CustomShuffleReaderExec(
right.shuffleStage, rightSidePartitions, rightSkewDesc.toString)
smj.copy(
left = s1.copy(child = newLeft), right = s2.copy(child = newRight), isSkewJoin = true)
Physical execution
The result of the skew algorithm is then a physical plan with extra nodes wrapping all happening before the SortExec node:
SortMergeJoin(skew=true) [id4#4], [id5#10], Inner
:- Sort [id4#4 ASC NULLS FIRST], false, 0
: +- CustomShuffleReader 1 skewed partitions with size(max=14 KB, min=14 KB, avg=14 KB)
: +- ShuffleQueryStage 0
: +- Exchange hashpartitioning(id4#4, 10), true, [id=#40]
: +- LocalTableScan [id4#4]
+- Sort [id5#10 ASC NULLS FIRST], false, 0
+- CustomShuffleReader no skewed partition
+- ShuffleQueryStage 1
+- Exchange hashpartitioning(id5#10, 10), true, [id=#46]
+- LocalTableScan [id5#10]
The PartialReducerPartitionSpec created before are the key for the physical execution of the skewed joins because the shuffle files reader gets their location by calling getMapSizesByRange method. It's used by range shuffle reader using the indices from PartialReducerPartitionSpec, thanks to which the reader is able to read the map groups created by the algorithm:
override def getReaderForRange[K, C](
handle: ShuffleHandle,
startMapIndex: Int,
endMapIndex: Int,
startPartition: Int,
endPartition: Int,
context: TaskContext,
metrics: ShuffleReadMetricsReporter): ShuffleReader[K, C] = {
val blocksByAddress = SparkEnv.get.mapOutputTracker.getMapSizesByRange(
handle.shuffleId, startMapIndex, endMapIndex, startPartition, endPartition)
new BlockStoreShuffleReader(
handle.asInstanceOf[BaseShuffleHandle[K, _, C]], blocksByAddress, context, metrics,
shouldBatchFetch = canUseBatchFetch(startPartition, endPartition, context))
}
In consequence, the join will be executed as:
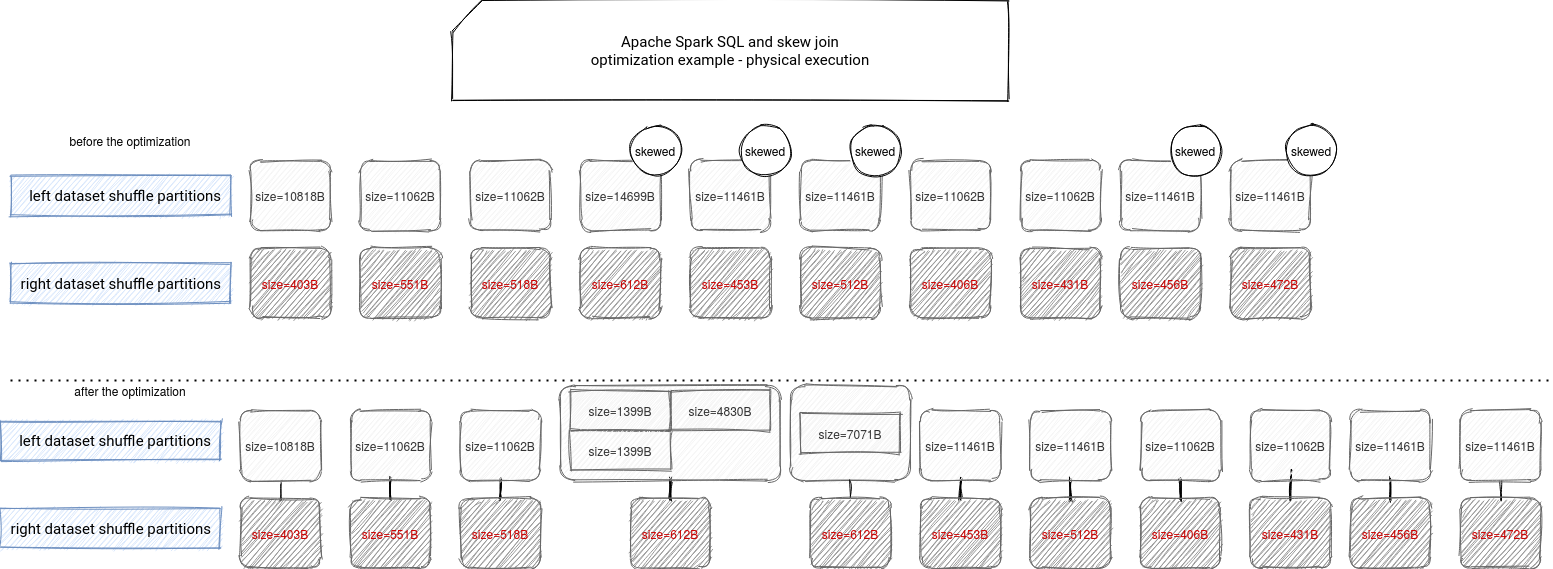
As you can see, some of the skewed partitions weren't split because the map files weren't much bigger than the targeted size. The drawback of this approach is that there is an additional cost of reading the same reducer file multiple times but this cost was estimated to be less important than the cost of shuffling skewed partitions.
Does it work like Skewed Join Optimization in Hive?
No, it doesn't because Apache Spark's solution works with sort-merge join and does not require the execution of 2 separate queries to handle the skew. In simpler terms, Apace Spark's approach can be understood as a sub-division of too big shuffle partitions at runtime.
Examples
Below you can find the code I'm using in the demo recorded just after:
object SkewedJoinOptimizationConfiguration {
val sparkSession = SparkSession.builder()
.appName("Spark 3.0: Adaptive Query Execution - join skew optimization")
.master("local[*]")
.config("spark.sql.adaptive.enabled", true)
// First, disable all configs that would create a broadcast join
.config("spark.sql.autoBroadcastJoinThreshold", "1")
.config("spark.sql.join.preferSortMergeJoin", "true")
.config("spark.sql.adaptive.logLevel", "TRACE")
// Disable coalesce to avoid the coalesce condition block the join skew
// optimization happen
.config("spark.sql.adaptive.coalescePartitions.enabled", "false")
// Finally, configure the skew demo
.config("spark.sql.shuffle.partitions", "10")
.config("spark.sql.adaptive.skewJoin.enabled", "true")
.config("spark.sql.adaptive.skewJoin.skewedPartitionFactor", "1")
.config("spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes", "10KB")
// Required, otherwise the skewed partitions are too small to be optimized
.config("spark.sql.adaptive.advisoryPartitionSizeInBytes", "1B")
.getOrCreate()
import sparkSession.implicits._
val input4 = (0 to 50000).map(nr => {
if (nr < 30000) {
1
} else {
nr
}
}).toDF("id4")
input4.createOrReplaceTempView("input4")
val input5 = (0 to 300).map(nr => nr).toDF("id5")
input5.createOrReplaceTempView("input5")
val input6 = (0 to 300).map(nr => nr).toDF("id6")
input6.createOrReplaceTempView("input6")
}
object SkewedJoinOptimizationNotAppliedDemo extends App {
SkewedJoinOptimizationConfiguration.sparkSession.sql(
"""
|SELECT * FROM input4 JOIN input5 ON input4.id4 = input5.id5
|JOIN input6 ON input6.id6 = input5.id5 """".stripMargin
).collect()
}
object SkewedJoinOptimizationAppliedDemo extends App {
SkewedJoinOptimizationConfiguration.sparkSession
.sql("SELECT * FROM input4 JOIN input5 ON input4.id4 = input5.id5")
.collect()
}
Skew join optimization is another building block of the brand new Adaptive Query Execution component. As you could see, under particular conditions, this optimization rule detects any skewed shuffle partitions and splits them into multiple groups to enable parallel processing and remove the skew. But that's not all. In the next post from the series about AQE, you will learn something new ;)
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.0 - join skew optimization here:
Related blog posts:
- What's new in Apache Spark 3.0 - Kubernetes
- What's new in Apache Spark 3.0 - GPU-aware scheduling
- What's new in Apache Spark 3 - Structured Streaming
- What's new in Apache Spark 3.0 - UI changes
- What's new in Apache Spark 3.0 - dynamic partition pruning
The second part of the Adaptive Query Execution features is online ? Today you can see how #ApacheSpark #SparkSQL can optimize skewed joins https://t.co/ak0J4n5KuV
— Bartosz Konieczny (@waitingforcode) August 15, 2020