
Even data distribution is one of the guarantees of performant data processing. However, it's not a golden rule and sometimes you can encounter uneven distribution called skews.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post is divided into 4 parts. The first one presents the concept of skewed data. The next 3 parts show how to deal with skewed data in Hive, Apache Spark and GCP.
Skewed data
A good concept helping to understand data skews is Pareto principle. It's also known as 80/20 rule and states that 80% of the effects come from 20% of the causes. In the data context, it means that 80% of data is produced by 20% of producers. Do you see where is the problem? Imagine that you're making a JOIN. If 80% of the joined data is about the same keys, you will end up with unbalanced partitions and therefore, these unbalanced partitions will take more time to execute.
A great real-world example of skewed data is Power Law that I shortly described in the post about Graphs and data processing post. To illustrate it, let's take social media influencers who have often hundred of thousands or millions of followers. On the opposite side, you have other users who have at most dozens of thousands of followers. Now, if you make a group by key operation, you move all followers for the influential people on the same partition, you will retrieve skews, marked in red in the following image:
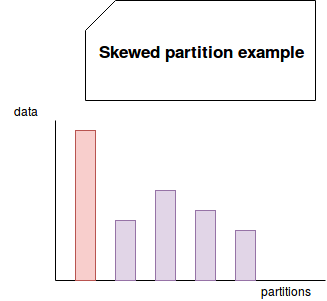
To put it short, skewed data occurs when most of the dataset rows are located on a small number of partitions.
Built-in solution in Hive
Since skewed data is not a new concept in data engineering, let's analyze different solutions proposed by data frameworks and community. Hive is one of the first Open Source solutions with built-in skew data management. It protects skews for 2 operations, joins and group by, both with different configuration entries:
- join with hive.optimize.skewjoin and hive.skewjoin.key
- group by with hive.groupby.skewindata
The implementation for both operations is similar because Hive simply creates an extra MapReduce job for skewed data. For group by operation, map output will be randomly distributed to the reducer in order to avoid skew and aggregates it with final reduce step. The logic behind skewed joins management uses the same principle. Hive determines whether the group of joined row is skewed and if it's the case, it writes them on HDFS in order to launch an additional MapReduce operation for them. The results of this operation are later included in the final output. The following images summarize both approaches:
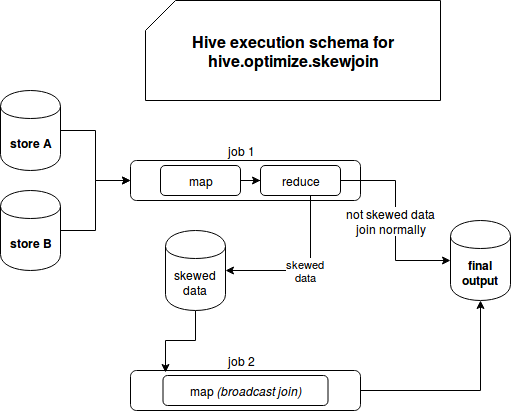
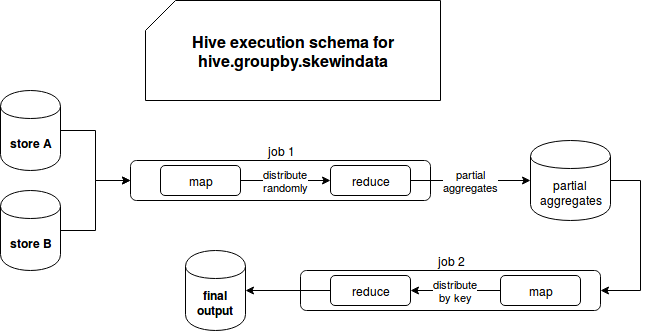
Custom solution - Apache Spark
After Hive, let's focus now on Apache Spark. The framework natively supports a kind of Hive's skew join hints but as of this writing, they're only available on Databricks platform. So the framework users working on different platforms will need other solutions. I will try to list some major proposals:
- broadcast - instead of making a join, so collocating all records on the same node, prefer to broadcast smaller dataset. By doing so you will avoid shuffle and have more chance to keep evenly distributed partitions.
- use salting - here the idea is to salt columns used in the join operation with some random number. You can see an example in the following snippet:
val users = Seq(("user1"), ("user2"), ("user3")).toDF("id") val orders = Seq((1L, "user1"), (2L, "user2"), (3L, "user3"), (4L, "user1"), (5L, "user1") , (6L, "user1"), (7L, "user1")).toDF("order_id", "user_id") // 1) Take a bigger dataset and add a column with some randomness // Here I'm simply adding a number between 0 and 2 val ordersWithSaltedCol = orders.withColumn("order_join_key", functions.concat($"user_id", functions.floor(functions.rand(2) * 2)) ) // 2) Later add a new column to cover all random possibilities. // Create one line for each possibility. Here I'm using explode function. val usersWithSaltedCol = users.withColumn("salt", functions.array(functions.lit(0), functions.lit(1), functions.lit(2))) .withColumn("user_salt", functions.explode($"salt")) .withColumn("user_join_key", functions.concat($"id", $"user_salt")) // 3) Make a join with the salted column val result = usersWithSaltedCol.join(ordersWithSaltedCol, $"user_join_key" === $"order_join_key") val mappedUsers = result.collect().map(row => s"${row.getAs[String]("id")}_${row.getAs[Int]("order_id")}") mappedUsers should have size 7 mappedUsers should contain allOf("user1_1", "user2_2", "user3_3", "user1_4", "user1_5", "user1_6", "user1_7") result.show(true) - filter data out - before performing a join or group by operation, filter out as many data as possible. It can reduce the amount of data on skewed partitions.
- adaptive partitioning - the idea comes from a Spark Summit 2016's talk where Zoltan Zvara proposed a method to perform repartitioning on skewed partitions just before executing the processing logic. Internally each executor collects local metrics and communicates them to the driver. The driver, depending on the distribution for given key, decides whether it needs to be repartitioned or not. You can find a link to the complete presentation in "Read also" section.
- reduce - above solutions work well for joins but are much harder to implement with group by operations. In such a case a good solution can be the use of partial aggregations.
Google guidelines
You will find some guidelines for skewed data management for Google products. Let's first see how it's managed in Apache Beam (not Google product but was heavily supported at the initial stage - that's why for simplicity I put it here). This library proposes a very similar method to the one used by Hive in group by operation. It's called combine with fanout and the idea is to avoid skewed partitions by partially aggregating the data. If you are interested by more technical details, I wrote a short post about Fanouts in Apache Beam's combine transform on February 2018.
The second guideline comes from BigQuery. This serverless data warehouse solution may encounter skewed operations as well. The official documentation advises 2 things. The first one is to filter out as many data as possible before making the join or group by operation. By doing so, you will probably eliminate a big part of skewed records. Another recommendation is to write 2 different queries, one for not skewed data and one for skewed data. You can then see the similarity with the approaches implemented in Hive where 2 different MapReduce jobs are executed to handle skews.
As you could learn here, skews slow down the processing logic considerably. Fortunately, they are not new and already some historical Big Data solutions like Hive implemented protection techniques against them. The general pattern you can see there is to compute skewed data in a separate step and integrate its results to the final output at the end.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Skewed data here:
- "Hadoop in practice" by Alex Holmes How to avoid skew on reducer for "Group-By" queries in Hive Hive - A Petabyte Scale Data Warehouse Using Hadoop BigQuery - Data skew Handling Data Skew Adaptively In Spark Using Dynamic Repartitioning Fighting the skew in Spark Skew join Does Spark support skew hints? Understanding the Pareto Principle (The 80/20 Rule)
Related blog posts:
- Project Oryx - Lambda architecture for data science
- Data validation frameworks - Great Expectations and orchestration
- Data validation frameworks - Great Expectations classes
Few people (nobody? ) like skews in #data In today's post I cover different solutions starting with #Hive built-in mechanism, and going through its alternatives in #ApacheSpark and #GCP https://t.co/IfSFxcwyM6
— Bartosz Konieczny (@waitingforcode) August 30, 2019