
Lambda architecture is one of the first officially defined Big Data architectures. However, after few time it was replaced by simpler approaches like Kappa. But despite that, you can still find the projects on Lambda and one of them which grabbed my attention is Project Oryx.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Why Oryx? Because it's an architecture adapted to the data science projects and it's always good to know the alternatives to the classical approaches. The blog starts with a quick recall of Lambda architecture components and later uses this information to explain the different parts of Oryx architecture.
Lambda 101
The Lambda architecture is composed of 3 layers called batch, speed, and serving. The 2 former ones are responsible for the data processing whereas the latter one for the data exposition. The batch layer, as the name indicates, processes data from a batch data source like a distributed file system or an object store (master dataset). The speed layer works on fresher data, so more on the streaming brokers or message queue. The serving layer can be any data store (RDBMS, NoSQL) that will be queried by the end-user.
The batch and speed layer work on the same type of data but not on the same latency. The batch layer computes more exact results but it does it rarely, like every day. On the other hand, the speed layer works on more real-time data and does it with an incremental approach, so by adding the new information to the exposed dataset. Because of the streaming semantic and risks (late data, approximate algorithms use, ...), the results on the speed layer will be often approximate and that's why they will be replaced at some point by the batch layer computation. You can see an example of this in the following picture:
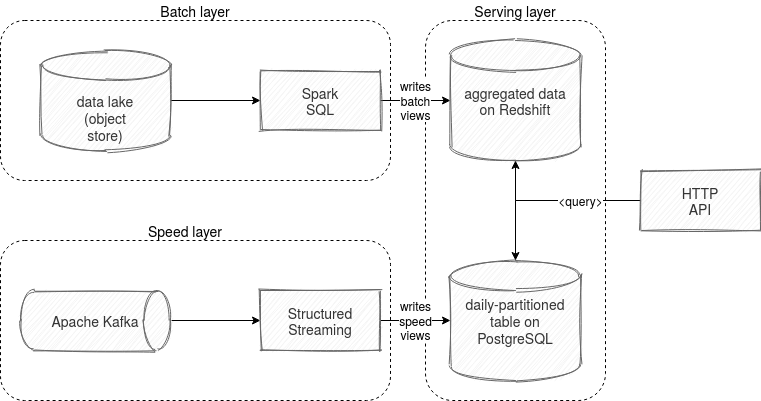
As you can see, our dataset is partitioned by the event time. The batch layer processes it once a day and in every execution, it invalidates the incremental results computed by the speed layer and generates a new, more exact view of the data. To do so, it uses a master dataset which is a resilient and immutable data store. The speed layer starts then the speed view for another day by creating a new time-based table, and this extra view is included in the serving layer. But how can it apply to data science projects? Let's see it with the help of the Project Oryx architecture.
Project Oryx 101
Oryx is an implementation of Lambda architecture for data science pipelines based on Apache Kafka and Apache Spark (you know now why I present it here ;-)). Even though it seems no longer maintained because its most recent release was in 2018, for the educational purpose it's interesting to see how to enhance the Lambda for other things than data analytics. And to understand that, let's focus on its components.
Batch layer
The first part of the batch layer. It has 2 responsibilities. First, it pulls the data from an Apache Kafka input topic and synchronizes it with the master dataset stored on HDFS. The data from this dataset is later used to train the ML models which are later persisted on HDFS.
Apart from training and model generation, the batch layer also communicates with the streaming broker to publish the information about a new generated model. The update is key-based, ie. the consumers listen for a specific key ("MODEL" or "MODEL-REF") and trigger an update action. But not all trained models are updated. Only the ones performing better are promoted:
Path bestCandidatePath = findBestCandidatePath(
sparkContext, newData, pastData, hyperParameterCombos, candidatesPath);
if (modelUpdateTopic == null) {
log.info("No update topic configured, not publishing models to a topic");
} else {
// Push PMML model onto update topic, if it exists
// ...
if (modelNotTooLarge) {
modelUpdateTopic.send("MODEL", PMMLUtils.toString(bestModel));
} else {
modelUpdateTopic.send("MODEL-REF", fs.makeQualified(bestModelPath).toString());
}
Since it's a *batch* layer, it will run less frequently than the speed layer presented in the next section.
Speed layer
Regarding the speed layer, it's internally managed by SpeedLayer class and it's mainly responsible for real-time data and model management. It's then supposed to run continuously (think about streaming). During the execution, it intercepts new input and passes it to SpeedLayerUpdate which processes the new data being an instance of JavaPairRDD<K,M> newData. At the end of this processing the updates are applied on the model stored in the speed layer and a model update record is created. After that, it's delivered to the topic with the record key called "UP".
The speed layer also listens for model updates ("MODEL", "MODEL-REF" record keys) and if it found one, it loads the new model to its in-memory representation. You can see an example of that in the KMeansSpeedModelManager:
switch (key) {
case "UP":
// do nothing, hearing our own updates
break;
case "MODEL":
case "MODEL-REF":
log.info("Loading new model");
PMML pmml = AppPMMLUtils.readPMMLFromUpdateKeyMessage(key, message, hadoopConf);
if (pmml == null) {
return;
}
KMeansPMMLUtils.validatePMMLVsSchema(pmml, inputSchema);
model = new KMeansSpeedModel(KMeansPMMLUtils.read(pmml));
log.info("New model loaded: {}", model);
break;
Serving layer
The responsibility of the serving layer is twofold. First, it answers user queries by using the model built from an Apache Kafka topic. When the serving layer starts, it consumes all records from this topic and starts to respond to the requests as soon as it finds the first valid model. The component can be then scaled seamlessly since it's stateless - the state is on the topic and it can be recomputed.
The second responsibility of the serving layer is to listen for "UP" keys, so for the model updates produced by the speed layer. When such a message is found, the serving layer applies it on the currently used model:
// RDFServingModelManager
@Override
public void consumeKeyMessage(String key, String message, Configuration hadoopConf) throws IOException {
switch (key) {
case "UP":
if (model == null) {
return; // No model to interpret with yet, so skip it
}
DecisionForest forest = model.getForest();
// ...
if (inputSchema.isClassification()) {
TerminalNode nodeToUpdate = (TerminalNode) forest.getTrees()[treeID].findByID(nodeID);
CategoricalPrediction predictionToUpdate =
(CategoricalPrediction) nodeToUpdate.getPrediction();
@SuppressWarnings("unchecked")
Map counts = (Map<String,Integer>) update.get(2); // JSON map keys are always Strings
counts.forEach((encoding, count) -> predictionToUpdate.update(Integer.parseInt(encoding), count));
Apart from that, the serving layer also listens for the model updates ("MODEL", "MODEL-REF") and if it encounters one, it reloads the stored model, updated so far with the features prepared by the speed layer.
The whole architecture can be summarized in this image:
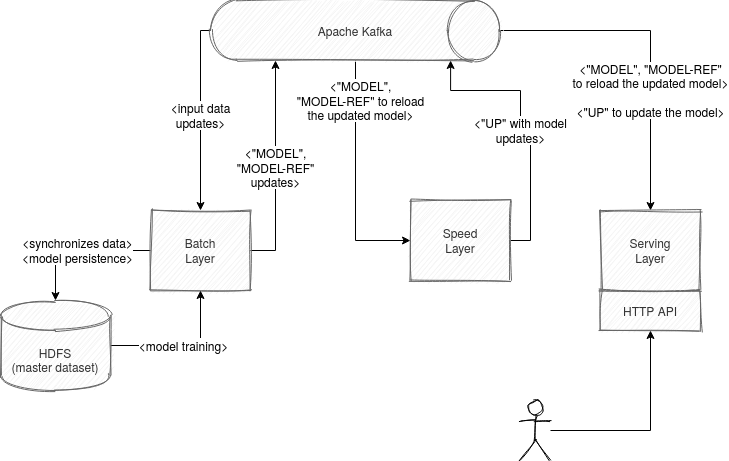
Project Oryx is an interesting illustration for the Lambda architecture applied to data science. It also shows, like other proposals from this category like Rendezvous architecture, how to leverage Apache Kafka and streaming capabilities for data science architectures.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Project Oryx - Lambda architecture for data science here:
Related blog posts:
- Data validation frameworks - Great Expectations and orchestration
- Data validation frameworks - Great Expectations classes
- Data validation frameworks - introduction to Great Expectations
I did it again ?♂️After losing myself on the internet (this time on Github), I found the next blog topic and analyzed how Project Oryx adapted Lambda architecture for data science pipelines ? https://t.co/2T9aw9F6hW
— Bartosz Konieczny (@waitingforcode) November 8, 2020