
So far you learned about skew optimization and coalesce shuffle partition optimizations made by the Adaptive Query Execution engine. But they're not the single ones and the next one you will discover is also related to the shuffle.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this blog post you will discover the optimization rule called local shuffle reader which consists of avoiding shuffle when the sort-merge join transforms to the broadcast join after applying the AQE rules. To understand why this rule is useful, let's see first what happens when it's disabled (spark.sql.adaptive.localShuffleReader.enabled) and the sort-merge join changes to the broadcast join. To illustrate the issue, let's take the following snippet where the filtering on the big dataset transforms the join type:
val input4 = sparkSession.sparkContext.parallelize(
(1 to 200).map(nr => TestEntryKV(nr, nr.toString)), 2).toDF()
input4.createOrReplaceTempView("input4")
val input5 = sparkSession.sparkContext.parallelize(Seq(
TestEntryKV(1, "1"), TestEntryKV(1, "2"),
TestEntryKV(2, "1"), TestEntryKV(2, "2"),
TestEntryKV(3, "1"), TestEntryKV(3, "2")
), 2).toDF()
input5.createOrReplaceTempView("input5")
val sqlQuery = "SELECT * FROM input4 JOIN input5 ON input4.key = input5.key WHERE input4.value = '1'"
val selectFromQuery = sparkSession.sql(sqlQuery)
selectFromQuery.collect()
In the video you can see that the data is fetched from the nodes by the reducer's id which means that there is a shuffle happening. It doesn't make a lot of sense since the shuffle won't be useful here since the engine will use broadcast join strategy, so move only one side of the join. According to the benchmarks made in the PR associated with the local shuffle reader feature, this extra shuffle operation slows down the whole processing and without it, the query executes 1.76 times faster! The same snippet but with the local shuffle reader optimization enabled fetches all reducer files for the given mapper. Below you can find the summary of these 2 operations:
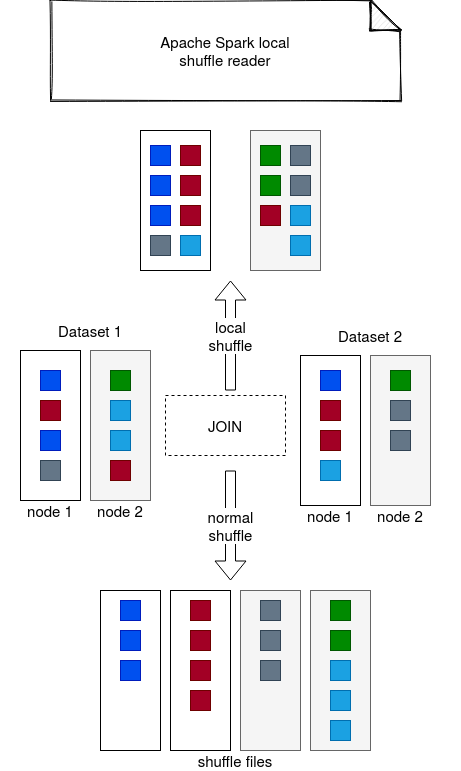
Local shuffle
The rule responsible for the local reader is defined in OptimizeLocalShuffleReader class. When the optimization is applied, a new partitions specification is generated. During this generation, the algorithm divides the number of reducer partitions by the max of the expected parallelism divided by the number of partitions on the mapper side (fallbacks to 1 to avoid the division by zero):
val expectedParallelism = advisoryParallelism.getOrElse(numReducers)
val splitPoints = if (numMappers == 0) {
Seq.empty
} else {
equallyDivide(numReducers, math.max(1, expectedParallelism / numMappers))
}
(0 until numMappers).flatMap { mapIndex =>
(splitPoints :+ numReducers).sliding(2).map {
case Seq(start, end) => PartialMapperPartitionSpec(mapIndex, start, end)
}
}
As you can see, every specification is done on the map side so that the reader could read the shuffle files simply from the local block manager. During the execution, the range shuffle reader is used at map-basic:
case PartialMapperPartitionSpec(mapIndex, startReducerIndex, endReducerIndex) =>
SparkEnv.get.shuffleManager.getReaderForRange(
dependency.shuffleHandle,
mapIndex,
mapIndex + 1,
startReducerIndex,
endReducerIndex,
context,
sqlMetricsReporter)
You can see then that it will take 1 map index (+1 is because the range does startMapIndex to endMapIndex - 1) and potentially multiple reducer files for the given map file. In consequence, the shuffle reader can read all necessary shuffle files from its local storage, actually without performing the shuffle across the network!
But why are we talking about the shuffle if the AQE optimized the query to the broadcast join? If you remember the introduction to the Adaptive Query Execution blog post, the AQE engine divides the query on stages and it executes them bottom-up. With every new stage executed, it has extra information that can help to create a new and more efficient plan. In the case discussed here, you will find 2 stages corresponding to the 2 sides of the join. Without the local shuffle reader, the plan can look like that:
*(3) BroadcastHashJoin [key#3], [key#13], Inner, BuildLeft
:- BroadcastQueryStage 2
: +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint))), [id=#92]
: +- ShuffleQueryStage 0
: +- Exchange hashpartitioning(key#3, 4), true, [id=#60]
: +- *(1) Filter (isnotnull(value#4) AND (value#4 = 1))
: +- *(1) SerializeFromObject [knownnotnull(assertnotnull(input[0, TestEntryKV, true])).key AS key#3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, TestEntryKV, true])).value, true, false) AS value#4]
: +- Scan[obj#2]
+- ShuffleQueryStage 1
+- Exchange hashpartitioning(key#13, 4), true, [id=#71]
+- *(2) SerializeFromObject [knownnotnull(assertnotnull(input[0, TestEntryKV, true])).key AS key#13, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, TestEntryKV, true])).value, true, false) AS value#14]
+- Scan[obj#12]
ShuffleQueryStage will execute an ShuffledRowRDD, so as the name indicates, an RDD involving shuffle:
case class ShuffleQueryStageExec(
override val id: Int,
override val plan: SparkPlan) extends QueryStageExec {
@transient val shuffle = plan match {
case s: ShuffleExchangeExec => s
case ReusedExchangeExec(_, s: ShuffleExchangeExec) => s
case _ =>
throw new IllegalStateException("wrong plan for shuffle stage:\n " + plan.treeString)
}
// ...
case class ShuffleExchangeExec(
override val outputPartitioning: Partitioning,
child: SparkPlan,
canChangeNumPartitions: Boolean = true) extends Exchange {
// ...
private var cachedShuffleRDD: ShuffledRowRDD = null
protected override def doExecute(): RDD[InternalRow] = attachTree(this, "execute") {
// Returns the same ShuffleRowRDD if this plan is used by multiple plans.
if (cachedShuffleRDD == null) {
cachedShuffleRDD = new ShuffledRowRDD(shuffleDependency, readMetrics)
}
cachedShuffleRDD
}
}
But the plan slightly changes with the local shuffle reader:
*(3) BroadcastHashJoin [key#3], [key#13], Inner, BuildLeft
:- BroadcastQueryStage 2
: +- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint))), [id=#93]
: +- CustomShuffleReader local
: +- ShuffleQueryStage 0
: +- Exchange hashpartitioning(key#3, 4), true, [id=#60]
: +- *(1) Filter (isnotnull(value#4) AND (value#4 = 1))
: +- *(1) SerializeFromObject [knownnotnull(assertnotnull(input[0, TestEntryKV, true])).key AS key#3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, TestEntryKV, true])).value, true, false) AS value#4]
: +- Scan[obj#2]
+- CustomShuffleReader local
+- ShuffleQueryStage 1
+- Exchange hashpartitioning(key#13, 4), true, [id=#71]
+- *(2) SerializeFromObject [knownnotnull(assertnotnull(input[0, TestEntryKV, true])).key AS key#13, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, TestEntryKV, true])).value, true, false) AS value#14]
+- Scan[obj#12]
Even though it still contains a ShuffleQueryStage (hence ShuffledRowRDD), it executes CustomShuffleReaderExec instead of the ShuffleExchangeExec and the ShuffledRowRDD is executed with map-based shuffle files that should already be present in the local block manager (hence local shuffle reader):
case class ShuffleExchangeExec(
override val outputPartitioning: Partitioning,
child: SparkPlan,
canChangeNumPartitions: Boolean = true) extends Exchange {
override protected def doExecute(): RDD[InternalRow] = {
if (cachedShuffleRDD == null) {
cachedShuffleRDD = child match {
case stage: ShuffleQueryStageExec =>
new ShuffledRowRDD(
stage.shuffle.shuffleDependency, stage.shuffle.readMetrics, partitionSpecs.toArray)
case _ =>
throw new IllegalStateException("operating on canonicalization plan")
}
}
cachedShuffleRDD
}
What is the guarantee that the partitions will be read once again by the executors that produced them? The answer to that question is hidden in the getPreferredLocations(partition: Partition): Seq[String] method of ShuffledRowRDD that will return the executor information before planning the task:
override def getPreferredLocations(partition: Partition): Seq[String] = {
val tracker = SparkEnv.get.mapOutputTracker.asInstanceOf[MapOutputTrackerMaster]
partition.asInstanceOf[ShuffledRowRDDPartition].spec match {
// ...
case PartialMapperPartitionSpec(mapIndex, _, _) =>
tracker.getMapLocation(dependency, mapIndex, mapIndex + 1)
}
}
The picture below summarizes what data is distributed and read for the local shuffle reader and map-based shuffle files:

Local shuffle reader is then an optimization to avoid shuffle execution when it's not necessary, ie. after the most recent switch from a sort-merge into a broadcast join. It reads the map files, so directly the ones that are located at the local block manager, avoiding then fetching the files from other executors.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.0 - local shuffle reader here:
- Optimize shuffle reader to local shuffle reader when smj converted to bhj in adaptive execution SPIP: Public APIs for extended Columnar Processing Support Remove duplication between columnar and ColumnarBatchScan Avoid changing SMJ to BHJ if the build side has a high ratio of empty partitions Spark SQL Adaptive Execution at 100 TB
Related blog posts:
- What's new in Apache Spark 3.0 - Kubernetes
- What's new in Apache Spark 3.0 - GPU-aware scheduling
- What's new in Apache Spark 3 - Structured Streaming
- What's new in Apache Spark 3.0 - UI changes
- What's new in Apache Spark 3.0 - dynamic partition pruning
Shuffle...local reader ? Before I discovered this new feature of #ApacheSpark #SparkSQL Adaptive Query Execution engine, "shuffle" always involved some network traffic. If you're curious about this local concept, you'll find more information here ? https://t.co/7iYAbbzB2R
— Bartosz Konieczny (@waitingforcode) August 29, 2020