
In my quest for understanding PySpark better, the JVM in the Python world is the must-have stop. In this first blog post I'll focus on Py4J project and its usage in PySpark.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Py4J
Unfortunately, there is no native way to write a Python code and run it on the JVM. Instead, the operation requires a proxy able to take the code from Python, pass it to the JVM, and get the results back if needed. The proxy layer used for that in PySpark is the Py4J library.
The library creates a bridge that consists of:
- Python application. The application has 2 roles. First, it defines the user business logic connecting to the Java classes. For Apache Spark, it'll be the data processing logic. Next to it, the application starts a JavaGateway that manages the JVM connection.
- Java application. Same as for Python, it has 2 parts. First, it defines the classes referenced by the Python business logic. Additionally, it starts a GatewayServer that exposes the network interface used by the JavaGateway, and the entrypoint. The entrypoint is the application accessible from Python JavaGateway entry_point field. For Apache Spark this part will expose components like SparkSession or SparkContext.
- Network connection. The Python application communicates with the JVM through a local network socket. By default, GatewayServer accepts the connection on the localhost:25333.
Although the design looks simple, it raises an important question. How is it possible to create a JVM object in Python and pass it to the Java application through the network socket? Py4J uses a system of commands. How to find them? In the protocol.py you'll see things like:
# Commands CALL_COMMAND_NAME = "c\n" FIELD_COMMAND_NAME = "f\n" CONSTRUCTOR_COMMAND_NAME = "i\n" SHUTDOWN_GATEWAY_COMMAND_NAME = "s\n" LIST_COMMAND_NAME = "l\n" REFLECTION_COMMAND_NAME = "r\n" MEMORY_COMMAND_NAME = "m\n" HELP_COMMAND_NAME = "h\n" ARRAY_COMMAND_NAME = "a\n" JVMVIEW_COMMAND_NAME = "j\n" EXCEPTION_COMMAND_NAME = "p\n" DIR_COMMAND_NAME = "d\n" STREAM_COMMAND_NAME = "S\n"
These constants are the prefixes passed to the JVM path from various Py4J Python components. For example, calling a Java method means invoking the following function:
class JavaMember(object):
# ...
def stream(self, *args):
"""
Call the method using the 'binary' protocol.
:rtype: The `GatewayConnection` that the call command was sent to.
"""
args_command, temp_args = self._build_args(*args)
command = proto.STREAM_COMMAND_NAME +\
self.command_header +\
args_command +\
proto.END_COMMAND_PART
answer, connection = self.gateway_client.send_command(
command, binary=True)
# parse the return value to throw an exception if necessary
get_return_value(
answer, self.gateway_client, self.target_id, self.name)
for temp_arg in temp_args:
temp_arg._detach()
return connection
The snippet sends a call command to the JVM where it's interpreted by one of the AbstractCommand implementations which is the CallCommand. Internally, it analyzes the incoming bytes array and extracts the object, method, and parameters to apply. Calling the method uses the Java reflection API and writes the results to the output buffer:
public class CallCommand extends AbstractCommand {
public final static String CALL_COMMAND_NAME = "c";
@Override
public void execute(String commandName, BufferedReader reader, BufferedWriter writer)
throws Py4JException, IOException {
String targetObjectId = reader.readLine();
String methodName = reader.readLine();
List<Object> arguments = getArguments(reader);
ReturnObject returnObject = invokeMethod(methodName, targetObjectId, arguments);
String returnCommand = Protocol.getOutputCommand(returnObject);
logger.finest("Returning command: " + returnCommand);
writer.write(returnCommand);
writer.flush();
}
The default exchange protocol format uses strings. Although it sounds surprising, the comment of the aforementioned protocol.py explains the reasons pretty clearly:
The protocol module defines the primitives and the escaping used by Py4J protocol. This is a text-based protocol that is efficient for general-purpose method calling, but very inefficient with large numbers (because they are text-based). Binary protocol (e.g., protobuf) was considered in the past, but internal benchmarking showed that it was less efficient in terms of size and time. This is due to the fact that a lot of small strings are exchanged (method name, class name, variable names, etc.).
The whole architecture can be summarized as in the schema below:
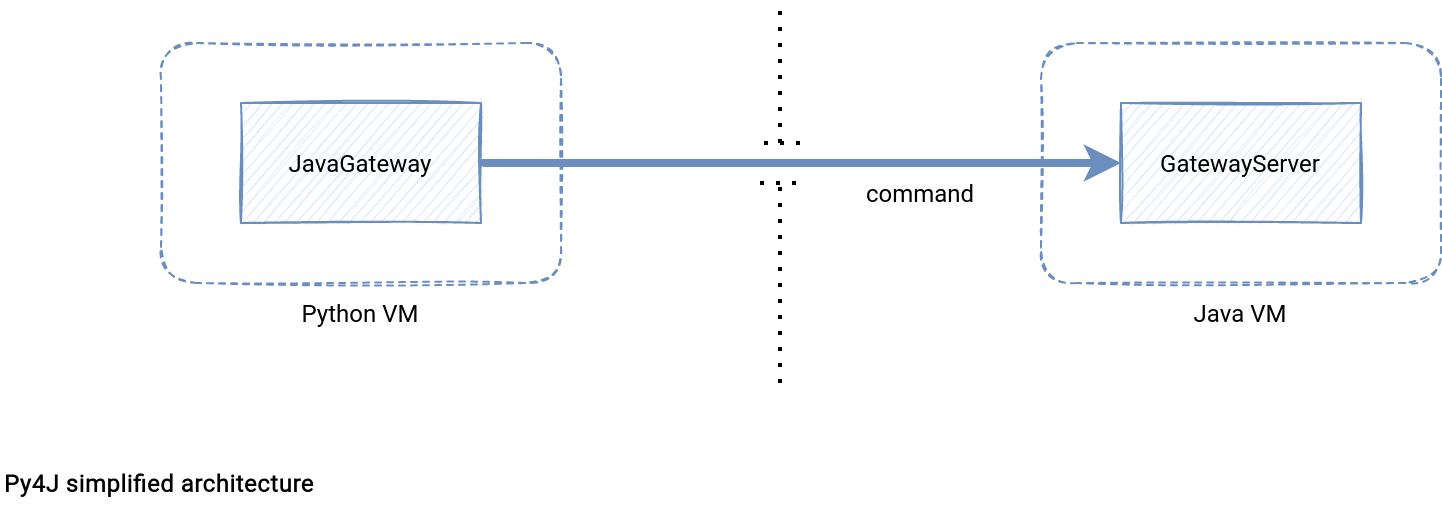
Py4J and PySpark
What about Apache Spark? How does PySpark connect to the JVM-based part of the framework? The starting point is the launch_gateway(conf=None, popen_kwargs=None) from pyspark/java_gateway.py file. It's called when you initialize SparkContext, so for example when you start a new SparkSession. The initialization code ensure the gateway is started only once:
def _ensure_initialized(cls, instance=None, gateway=None, conf=None):
with SparkContext._lock:
if not SparkContext._gateway:
SparkContext._gateway = gateway or launch_gateway(conf)
SparkContext._jvm = SparkContext._gateway.jvm
The launch_gateway method does the operations presented in the previous section. First, it starts a spark-submit command with pyspark-shell input file. It's the default value that can be overridden in the PYSPARK_SUBMIT_ARGS environment variable:
def launch_gateway(conf=None, popen_kwargs=None):
# ...
script = "./bin/spark-submit.cmd" if on_windows else "./bin/spark-submit"
command = [os.path.join(SPARK_HOME, script)]
if conf:
for k, v in conf.getAll():
command += ['--conf', '%s=%s' % (k, v)]
submit_args = os.environ.get("PYSPARK_SUBMIT_ARGS", "pyspark-shell")
# ...
command = command + shlex.split(submit_args)
# ...
proc = Popen(command, **popen_kwargs)
This spark-submit call starts the JVM and lands here:
private[spark] class SparkSubmit extends Logging {
private[deploy] def prepareSubmitEnvironment(
args: SparkSubmitArguments,
conf: Option[HadoopConfiguration] = None)
: (Seq[String], Seq[String], SparkConf, String) = {
// ...
// If we're running a python app, set the main class to our specific python runner
if (args.isPython && deployMode == CLIENT) {
if (args.primaryResource == PYSPARK_SHELL) {
args.mainClass = "org.apache.spark.api.python.PythonGatewayServer"
} else {
// If a python file is provided, add it to the child arguments and list of files to deploy.
// Usage: PythonAppRunner <main python file> [app arguments]
args.mainClass = "org.apache.spark.deploy.PythonRunner"
args.childArgs = ArrayBuffer(localPrimaryResource, localPyFiles) ++ args.childArgs
}
}
As you can see, Apache Spark starts a different backend depending on the input file. For the shell, it's PythonGatewayServer and for the specific file, the PythonRunner. Both start a Py4JServer that creates a ClientServer or GatewayServer under-the-hood. There is a difference between them, but I'll explain it in the next section.
Anyway, at this moment Apache Spark has already started the JVM gateway. The process can continue on the Python side where PySpark creates a Py4J client, which is the ClientServer or JavaGateway. In the end, it sets the reference to the spark-submit and imports the classes needed by Spark:
def launch_gateway(conf=None, popen_kwargs=None):
# ...
if os.environ.get("PYSPARK_PIN_THREAD", "true").lower() == "true":
gateway = ClientServer(
java_parameters=JavaParameters(
port=gateway_port,
auth_token=gateway_secret,
auto_convert=True),
python_parameters=PythonParameters(
port=0,
eager_load=False))
else:
gateway = JavaGateway(
gateway_parameters=GatewayParameters(
port=gateway_port,
auth_token=gateway_secret,
auto_convert=True))
# Store a reference to the Popen object for use by the caller (e.g., in reading stdout/stderr)
gateway.proc = proc
# Import the classes used by PySpark
java_import(gateway.jvm, "org.apache.spark.SparkConf")
java_import(gateway.jvm, "org.apache.spark.api.java.*")
java_import(gateway.jvm, "org.apache.spark.api.python.*")
java_import(gateway.jvm, "org.apache.spark.ml.python.*")
java_import(gateway.jvm, "org.apache.spark.mllib.api.python.*")
java_import(gateway.jvm, "org.apache.spark.resource.*")
# TODO(davies): move into sql
java_import(gateway.jvm, "org.apache.spark.sql.*")
java_import(gateway.jvm, "org.apache.spark.sql.api.python.*")
java_import(gateway.jvm, "org.apache.spark.sql.hive.*")
java_import(gateway.jvm, "scala.Tuple2")
return gateway
The communication between Python VM and Java VM is now ready. But as you see, the last thing remains to explain. What is this pinned thread from the environment variable present in the snippet above?
Pinned thread
By default, Py4J creates a new thread for each received command without any thread available. It can happen in the recursion calls when the threads are released:
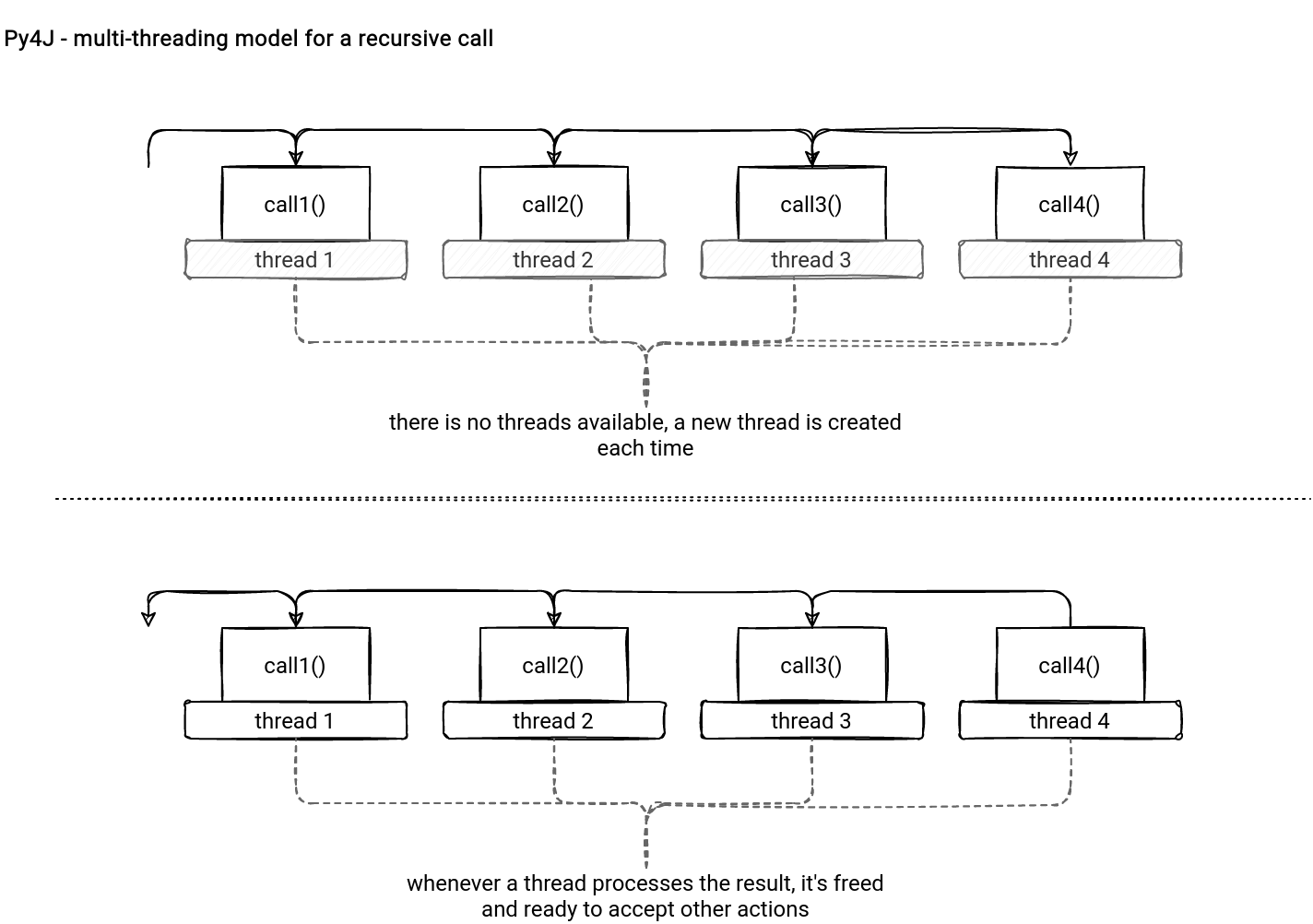
Not only the growing number of threads might be a problem here. Additionally, this model doesn't control the thread that will execute the code. It led to some problems in Apache Spark, like the one described in SPARK-22340, where assigning job id was unpredictable.
To overcome these issues, Py4J added the support for a single threading model, which in the code presented previously was represented by the ClientServer instance on the Python side, and the ClientServer instance on the Java side.
It was the first of 2 articles presenting the interaction between Python and Java Virtual Machines. The interaction is possible thanks to the Py4J library that works in a multi- or single-threading mode. Under-the-hood, PySpark will use one or another depending on the PYSPARK_PIN_THREAD configuration to create the required JVM server and PVM client gateways. In the next part, you'll what happens with the data processing code.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Abstracting column access in PySpark with Proxy design pattern
- Shuffle in PySpark
- Serializers in PySpark
I've started digging and instead of one blog post I'll probably end up with 2 ;) The first part of my PySpark interaction with the JVM is online, the next should be there in 3 weeks ? https://t.co/V7Y8xfLeEg
— Bartosz Konieczny (@waitingforcode) April 30, 2022