
Gnocchi writes data partitioned by split key. But often such splitted data must be merged back for reading operations. This post focuses on "how" and "when" of this process.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post explains what happens in Gnocchi when an end user requests for aggregated measures. It's composed of 2 parts. In the first one we can discover the implementation of reading data logic. The next one shows how the data is organized in local filesystem storage engine.
Reading path
The reading path including some implementation details is summarized in the following picture:
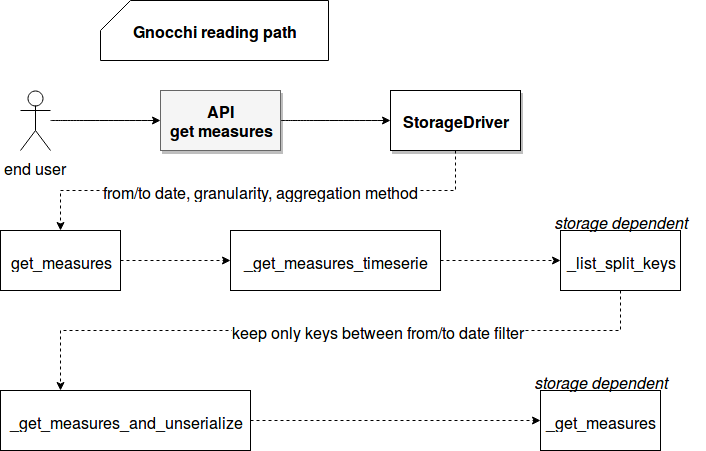
As you can see, everything starts by preparing the query context with date filters and aggregations to retrieve. Such context is passed later to StorageDriver's method responsible for getting the queried results. Split keys are involved here. The first step consists on reading all split keys belonging to given metric, the aggregation and the expected granularity. If we're supposed to store small chunks of aggregated data for small granularity (e.g. 1 sec), this operation could be the first analysis step for performance issues. The used reading method depends on the underlying storage. For the local filesystem it consists on reading and filtering all files from the metric's aggregation directory. For Redis it iterates over the registered paths.
In the next steps the retrieved keys are filtered and only the ones included between from/to date criteria are kept. Later the data corresponding for each key is read and unserialized to the AggregatedTimeSerie instance. In the next step all objects are concatenated and a single AggregatedTimeSerie instance containing all values from the read data is returned. And just before returning the results to the end user, this AggregatedTimeSerie instance is truncated to avoid to return too many points. It can occur when the archive policy was resized and the aggregates weren't be processed with the new specification.
Data organization in local filesystem
To see the data organization, let's run the Gnocchi's Docker image and add some measures with the API:
# Create a 1 second per day policy first
curl -d '{
"aggregation_methods": ["sum", "count"],
"back_window": 0,
"definition": [
{
"granularity": "1s",
"timespan": "7 day"
},
{
"granularity": "30s",
"timespan": "7 day"
}
],
"name": "1_week_policy"
}' -H "Content-Type: application/json" -X POST http://admin:admin@localhost:8041/v1/archive_policy
# Create now a metric with this policy
curl -d '{
"archive_policy_name": "1_week_policy",
"name": "tested_metric"
}' -H "Content-Type: application/json" -X POST http://admin:admin@localhost:8041/v1/metric
# ... and not its id: d2aaaf98-617d-4f1a-bdec-23ac1463b278
Now we can push the measures to this metric with the following Python script:
import datetime
import random
import requests
import json
from requests.auth import HTTPBasicAuth
start_time = datetime.datetime.utcnow()
number_of_seconds_to_push = 14400 # 2 days
measures = []
for seconds_number in range(0, number_of_seconds_to_push):
measure_time = start_time + datetime.timedelta(seconds=seconds_number)
measure_value = random.randint(1, 100)
measures.append({"timestamp": measure_time.strftime('%Y-%m-%dT%H:%M:%S'), "value": float(measure_value)})
chunk_length = 300
endpoint = 'http://localhost:8041/v1/metric/d2aaaf98-617d-4f1a-bdec-23ac1463b278/measures'
headers = {'content-type': 'application/json'}
for chunk_start_index in range(0, len(measures), chunk_length):
if chunk_length > len(measures):
chunk_length = len(measures)
measures_to_send = measures[chunk_start_index: chunk_start_index+chunk_length]
post_response = requests.post(url=endpoint, data=json.dumps(measures_to_send),
auth=HTTPBasicAuth('admin', 'admin'), headers=headers)
print('response was {response}'.format(response=post_response.content))
After looking at the files organization inside /var/lib/gnocchi/d2aaaf98-617d-4f1a-bdec-23ac1463b278 we can find the files composed of: first stored timestamp, granularity and version. Such organization proves the sayings from the first section about getting all keys belonging to given granularity and filtering them later to get the data between specified time ranges:
1524744000.0_30.0_v3 1524826800.0_1.0_v3 1524834000.0_1.0_v3 1524823200.0_1.0_v3 1524830400.0_1.0_v3 1524837600.0_1.0_v3
The concept of split key makes that the aggregation results can be fetched at once. As shown in the first section, when some data is requested, the first step made by Gnocchi consists on retrieving the split keys containing the time range of the query. Only after that the data is read from the files, unserialized, merged and eventually truncated.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Resources and metrics in Gnocchi
- Sacks - data parallelization unit in Gnocchi
- Carbonara storage format
- Gnocchi architecture
- Choosing time-series database for study
Another post explaining #Gnocchi internals. This time it's about reading aggregates https://t.co/sy24UATBBX pic.twitter.com/bCww0NgUGN
— bardev (@waitingforcode) July 15, 2018