
Last week you could read about data reading in Delta Lake. Today it's time to cover this part in Apache Iceberg!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Table types
I better understood the reading part after getting the table types part right. In Apache Iceberg you'll find 2 kinds of tables: metadata and data tables. The former represents any metadata query, such as the one targeting the table history, snapshot, or manifests. The data table on the other hand works on the stored dataset. The classes hierarchy of both types looks like in the schema below:
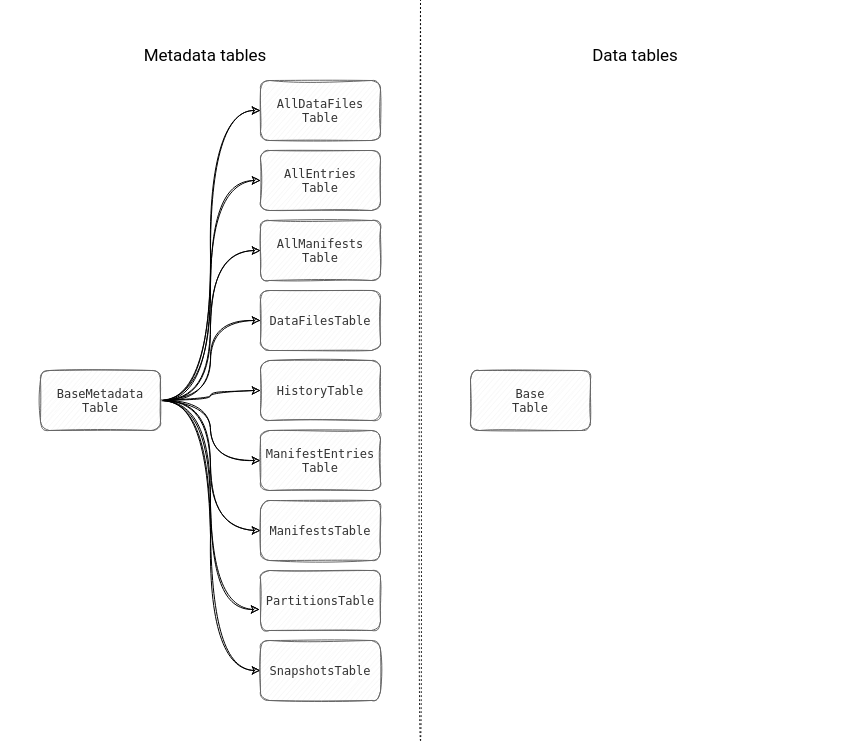
The tables are just classes that don't materialize the data as long as they're not queried. During the analysis stage the query execution creates a new instance of the table in the CachingCatalog#loadTable(TableIdentifier ident) method. Inside, you'll find the logic for distinguishing between data and metadata tables. The logic looks at the name of the table and if it exists among the MetadataTableType, the loader considers it as a metadata table:
public class CachingCatalog implements Catalog {
// ...
@Override
public Table loadTable(TableIdentifier ident) {
TableIdentifier canonicalized = canonicalizeIdentifier(ident);
// ...
if (MetadataTableUtils.hasMetadataTableName(canonicalized)) {
// ...
}
public enum MetadataTableType {
ENTRIES,
FILES,
HISTORY,
SNAPSHOTS,
MANIFESTS,
PARTITIONS,
ALL_DATA_FILES,
ALL_MANIFESTS,
ALL_ENTRIES;
// ...
}
public class MetadataTableUtils {
// ...
public static boolean hasMetadataTableName(TableIdentifier identifier) {
return MetadataTableType.from(identifier.name()) != null;
}
}
Later, the loader calls a switch case to initialize the table corresponding to the type:
private static Table createMetadataTableInstance(TableOperations ops, Table baseTable, String metadataTableName,
MetadataTableType type) {
switch (type) {
case ENTRIES:
return new ManifestEntriesTable(ops, baseTable, metadataTableName);
case FILES:
return new DataFilesTable(ops, baseTable, metadataTableName);
case HISTORY:
return new HistoryTable(ops, baseTable, metadataTableName);
// ...
}
The things are a bit simpler for the data table that gets loaded directly from the Catalog instance wrapped by the CachingCatalog, for example HadoopCatalog.
Scans
Tables are static things, though. They won't read the data. The component responsible for the physical data processing are TableScans. Each Table exposes its own scan implementing this TableScan interface:
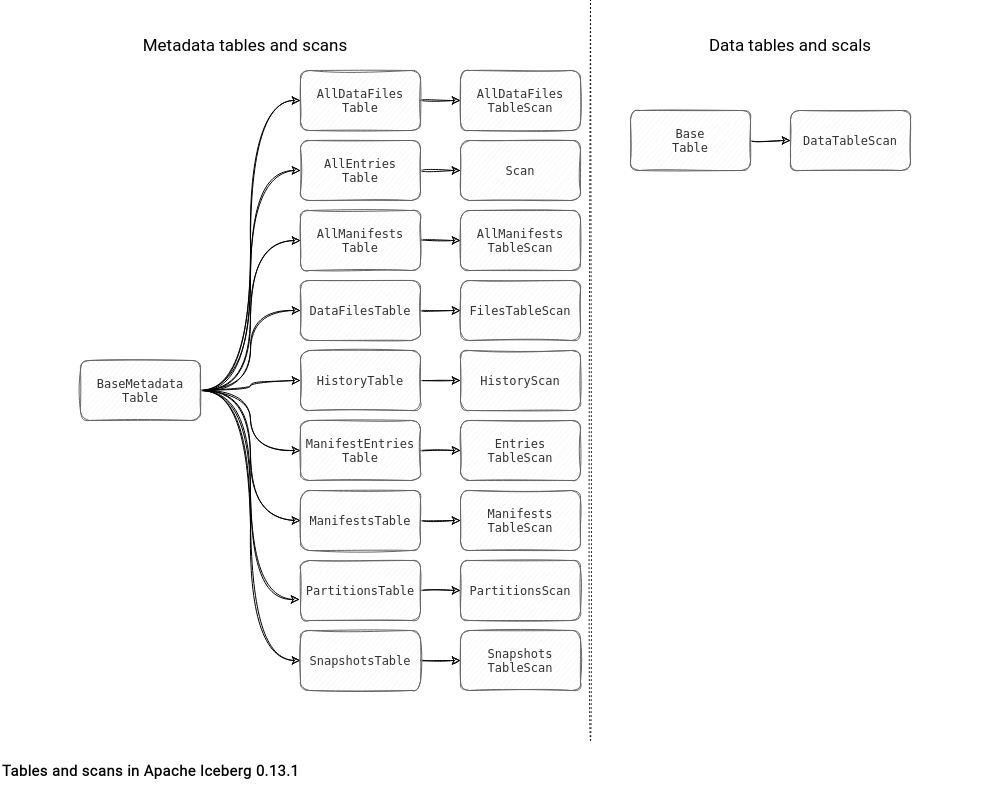
The TableScan interface defines 2 important things in Apache Iceberg data reading:
- Table context, so the things like snapshot to read, columns to select, or filters to apply. This part is rather descriptive, it doesn't make any action on the metadata nor the data layer.
public interface TableScan { // ... TableScan useSnapshot(long snapshotId); TableScan asOfTime(long timestampMillis); TableScan option(String property, String value); TableScan project(Schema schema); TableScan includeColumnStats(); default TableScan select(String... columns) { return select(Lists.newArrayList(columns)); } Expression filter(); TableScan ignoreResiduals(); // ... } - Table action, so the things that analyze the metadata layer and generate corresponding physical actions, like plans or tasks:
public interface TableScan { // ... /** * Plan the {@link FileScanTask files} that will be read by this scan. * <p> * Each file has a residual expression that should be applied to filter the file's rows. * <p> * This simple plan returns file scans for each file from position 0 to the file's length. For * planning that will combine small files, split large files, and attempt to balance work, use * {@link #planTasks()} instead. * * @return an Iterable of file tasks that are required by this scan */ CloseableIterable<FileScanTask> planFiles(); /** * Plan the {@link CombinedScanTask tasks} for this scan. ** Tasks created by this method may read partial input files, multiple input files, or both. * * @return an Iterable of tasks for this scan */ CloseableIterable<CombinedScanTask> planTasks();
But bad news, the reading doesn't stop here! I'm analyzing Apache Iceberg from the Apache Spark's runner perspective, so there is an extra component which is the glue between these two worlds. It's SparkBatchScan and more exactly one of its 3 implementations:
- SparkBatchQueryScan. It's the scan used by Apache Spark to access the data and create the DataFrame to process.
- SparkFilesScan. It's the scan reserved to the file-related operations, like REWRITE DATA. They do operate on the data but are responsible for changing the storage layout rather than overwriting the values.
- SparkMergeScan. It's the one that will be employed in the in-place change operations, like updates or deletes.
Tasks
The SparkBatchQueryScan is the abstraction exposed directly to Apache Spark for reading Apache Iceberg files. The interaction between these 2 components starts when Spark asks Iceberg to generate the list of input partitions. It does so by calling the SparkBatchQueryScan#planInputPartitions that does 2 major things, broadcasting the resolved Table and planning the scan tasks:
public InputPartition[] planInputPartitions() {
// ...
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
List<CombinedScanTask> scanTasks = tasks();
InputPartition[] readTasks = new InputPartition[scanTasks.size()];
Tasks.range(readTasks.length)
.stopOnFailure()
.executeWith(localityPreferred ? ThreadPools.getWorkerPool() : null)
.run(index -> readTasks[index] = new ReadTask(
scanTasks.get(index), tableBroadcast, expectedSchemaString,
caseSensitive, localityPreferred));
return readTasks;
}
The key part here is the tasks() method. Why? Take a look at the following schema that illustrates other interactions between Apache Iceberg and Apache Spark in this physical data reading:
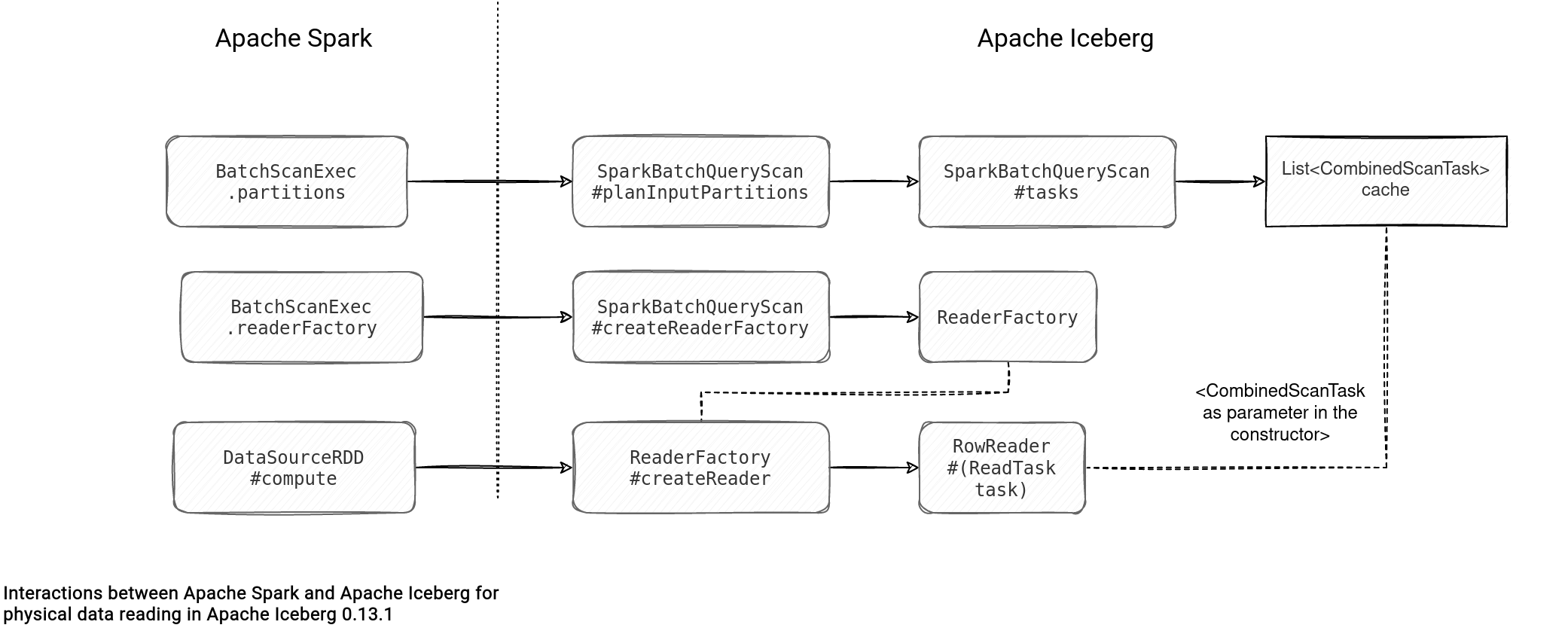
The tasks() is the generator of CombinedScanTasks that are later called by the RowReader which depending on the file type will operate on Apache Iceberg, Apache Orc, or Apache Avro. To be more precise, this tasks() method does 3 major steps to generate this CombinedScanTasks:
- Files planning. Here it retrieves all snapshots (manifest lists) with the associated manifest files (Apache Iceberg file system layout), and generates a list of FileScanTasks. Each of them contains the input query elements, such as filtering expression or partition information, and additionally, the information from the manifests, like the associated deleted files.
- Files splitting. In this step, the list of FileScanTask gets splitted according to the value defined in the read.split.target-size property (128MB by default). The action happens in TableScanUtil#splitFiles that calls the split(long splitSize) method of each of the input FileScanTask.
public class TableScanUtil { // ... public static CloseableIterable<FileScanTask> splitFiles(CloseableIterable<FileScanTask> tasks, long splitSize) { Preconditions.checkArgument(splitSize > 0, "Invalid split size (negative or 0): %s", splitSize); Iterable<FileScanTask> splitTasks = FluentIterable .from(tasks) .transformAndConcat(input -> input.split(splitSize)); // Capture manifests which can be closed after scan planning return CloseableIterable.combine(splitTasks, tasks); } public interface FileScanTask extends ScanTask { // ... Iterable<FileScanTask> split(long splitSize); - Tasks planning. It's the final step where the operation creates the final list of CombinedScanTasks. It uses a bin-packing iterator to optimize the smaller splitted FileScanTasks and put them together in the input partition, therefore reducing the number of Apache Spark tasks.
The whole algorithm, but as a code, looks like:
abstract class BaseTableScan implements TableScan {
// ...
@Override
public CloseableIterable<CombinedScanTask> planTasks() {
CloseableIterable<FileScanTask> fileScanTasks = planFiles();
CloseableIterable<FileScanTask> splitFiles = TableScanUtil.splitFiles(fileScanTasks, targetSplitSize());
return TableScanUtil.planTasks(splitFiles, targetSplitSize(), splitLookback(), splitOpenFileCost());
}
And starting from that the RowReader enters into action and processes the associated files in the task.
After analyzing this reading part I must admit to be less surprised by the snapshot-related features than before discovering it in Delta Lake, but was very amazed by the integration with Apache Spark. Knowing that Apache Spark was only one of the supported runtime environments and having to find the right abstractions and the glue to connect these separate parts, was a challenging software engineering part! I can't wait now to see what Apache Hudi reserves to me in this field!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Table file formats - reading path: Apache Iceberg here:
Related blog posts:
- Table file formats - Z-Order compaction: Apache Iceberg
- Table file formats - compaction: Apache Iceberg
- ACID file formats - writing: Apache Iceberg
Different tables and associated scans are 2 important parts of data reading in #ApacheIceberg . Sounds interesting? You'll find more details in the new blog post ? https://t.co/z1nyLFRzG7
— Bartosz Konieczny (@waitingforcode) September 25, 2022