
Delete covered one of my previous posts is not a single clean up policy in Apache Kafka. Another one is compaction which reduces the size of the segments by keeping the last value for every key.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this blog post I will focus on the compaction implementation. In the beginning, you will see when and by who it's triggered. After that, you will discover some implementation details, especially from the memory pressure point of view.
High-level view
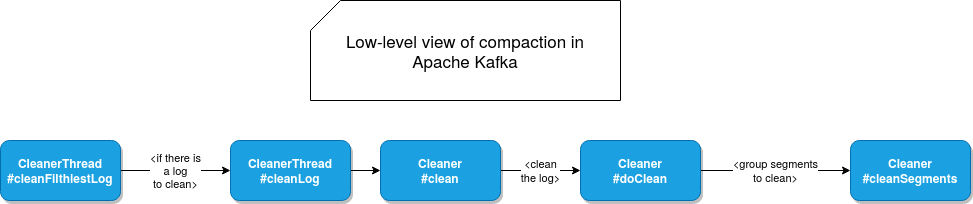
Since the compaction belongs to the same clean up family of processes, it has a very similar sequence to the one I presented previously in logs compaction in Apache Kafka - delete and cleanup policy. At the beginning LogCleanerManager selects one log that will be cleaned and passes it to the LogCleaner's cleanLog() method.
Once resolved, the log is later passed to Cleaner's clean() method calling the physical cleaning from doClean(). At the end of the chain, cleanInto() method performs the physical segments compaction.
The low level flow inside LogCleaner and Cleaner classes look like that:
What is it all about?
How does Apache Kafka compact the records? When I discovered it, I was really amazed by the simplicity of the solution! Internally, the cleaner creates a map being an instance of SkimpyOffsetMap which is a put-only space-efficient map, optimized thanks to the use of cryptographically secure hashes of the keys as proxies. It's invoked in doClean() method where:
- The cleaner initializes a new instance of the map. The map exposes a property defining the max number of entries it can contain, depending on the buffer reserved to the compaction (log.cleaner.dedupe.buffer.size),the number of cleaner threads (log.cleaner.threads and the size of every entry which depends on the hashing algorithm. All these properties are used to compute the size of the map that way:
// depends on the hash algorithm val bytesPerEntry = hashSize + 8 // memory = MIN(log.cleaner.dedupe.buffer.size / log.cleaner.threads, Int.MaxValue) val slots: Int = memory / bytesPerEntry // slots multiplied by a "security buffer" log.cleaner.io.buffer.load.factor, // so an expected number of extra entries that a map should // handle (= expected duplicates) val maxDesiredMapSize = (map.slots * this.dupBufferLoadFactor).toInt
- One initialized, this map is later used as a container for all records defined in the segments of the cleaned log. And it's here the magic happens 🧙
- Every time a record is met, the cleaner adds an entry to the map with the offset of the record. Since in the map, we can have only 1 entry for a given key and since the log segments are read in chronological order (the oldest entries at the beginning), after reading all the segments, we're sure that everything we have in the map corresponds to the latest known records for every key!
After building the map, the cleaner compacts the segments. First, it retrieves all segments to compact and groups them to generate evenly partitioned files:
val upperBoundOffset = cleanable.firstUncleanableOffset
buildOffsetMap(log, cleanable.firstDirtyOffset, upperBoundOffset, offsetMap, stats)
val endOffset = offsetMap.latestOffset + 1
stats.indexDone()
// determine the timestamp up to which the log will be cleaned
// this is the lower of the last active segment and the compaction lag
val cleanableHorizonMs = log.logSegments(0, cleanable.firstUncleanableOffset).lastOption.map(_.lastModified).getOrElse(0L)
// group the segments and clean the groups
info("Cleaning log %s (cleaning prior to %s, discarding tombstones prior to %s)...".format(log.name, new Date(cleanableHorizonMs), new Date(deleteHorizonMs)))
val transactionMetadata = new CleanedTransactionMetadata
val groupedSegments = groupSegmentsBySize(log.logSegments(0, endOffset), log.config.segmentSize,
log.config.maxIndexSize, cleanable.firstUncleanableOffset)
After that, every group is compacted. The compaction means here grouping multiple old segments into one new one. During that process, all records stored in the old segments are read and filtered. In the filter predicate, Kafka checks whether the offset of the record is greater or equal than the offset stored in the map. If it's the case, and also the new record has a value or cannot be deleted just now (tombstones and markers should be retained during the operation), the record is kept for the new segment. Otherwise, it's simply discarded.
if (record.hasKey) {
val key = record.key
val foundOffset = map.get(key)
/* First,the message must have the latest offset for the key
* then there are two cases in which we can retain a message:
* 1) The message has value
* 2) The message doesn't has value but it can't be deleted now.
*/
val latestOffsetForKey = record.offset() >= foundOffset
val isRetainedValue = record.hasValue || retainDeletes
latestOffsetForKey && isRetainedValue
} else {
stats.invalidMessage()
false
}
All kept records are later appended to the new segment and at the end flushed to disk. If all these operations succeed, the suffix of the new segment candidate changes from .clean to .swap. After this operation, old segments are physically removed and the candidates are renamed once again by removing the .swap suffix added previously.
Segments cut in the middle?
Before going to the transactions management, I would like to cover one problematic point, namely what happens if the last segment is only taken partially for the compaction? Nothing, because it's a non existing problem. Only the whole segments are resolved for compaction! In cleanableOffsets method of LogCleanerManager you can see that neither active segment nor the segments that don't reach the compaction lag (min.compaction.lag.ms):
// the first segment whose largest message timestamp is within a minimum time lag from now
if (minCompactionLagMs > 0) {
// dirty log segments
val dirtyNonActiveSegments = log.nonActiveLogSegmentsFrom(firstDirtyOffset)
dirtyNonActiveSegments.find { s =>
val isUncleanable = s.largestTimestamp > now - minCompactionLagMs
debug(s"Checking if log segment may be cleaned: log='${log.name}' segment.baseOffset=${s.baseOffset} " +
s"segment.largestTimestamp=${s.largestTimestamp}; now - compactionLag=${now - minCompactionLagMs}; " +
s"is uncleanable=$isUncleanable")
isUncleanable
}.map(_.baseOffset)
} else None
That's for the offsets resolution but it gives already a hint that all compaction operation apply to the whole log segments, like this one when the segments are grouped before the compaction:
val groupedSegments = groupSegmentsBySize(log.logSegments(0, endOffset), log.config.segmentSize,
log.config.maxIndexSize, cleanable.firstUncleanableOffset)
The key is logSegments method which gets all segments and not the records within them:
/**
* Get all segments beginning with the segment that includes "from" and ending with the segment
* that includes up to "to-1" or the end of the log (if to > logEndOffset)
*/
def logSegments(from: Long, to: Long): Iterable[LogSegment] = {
Compaction and transactions
A special behavior happens when the compacted records come from a transaction. Since I'm still not familiar with the transactions internals in Apache Kafka, please take my words with caution and correct them if I'm wrong.
Before compacting the segments, the cleaner initializes an instance of CleanedTransactionMetadata that is responsible for tracking transaction state during the compaction process. What does it mean concretely? First, it collects all aborted transactions related to the processed segment:
// cleanSegments
val startOffset = currentSegment.baseOffset
val upperBoundOffset = nextSegmentOpt.map(_.baseOffset).getOrElse(map.latestOffset + 1)
val abortedTransactions = log.collectAbortedTransactions(startOffset, upperBoundOffset)
transactionMetadata.addAbortedTransactions(abortedTransactions)
After that, the cleaner removes the transaction records as not transactional records. Every transaction also has an associated transaction marker and this one can be deleted only when the transaction has no more records in the segment and the delete.retention.ms has been passed. Also, the cleaner won't delete the last batch of records for a still-active producer because this batch contains the last sequence number for that producer. The second exception applies on the transaction markers (control batches) since it stores the last producer epoch.
I was always curious about the compaction in Apache Kafka. After this and the previous article, I know a little bit more now. I like the smart use case of a map data structure to build the offsets list to keep in the compacted segment and hope to discover more of such things in my next explorations!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Isolation level in Apache Kafka consumers
- Control messages in Apache Kafka
- Records writing in Apache Kafka
#ApacheKafka compaction is another great example of the power of the map data structure ? You can find more details in the new blog post https://t.co/XSC7oCBrml
— Bartosz Konieczny (@waitingforcode) August 30, 2020