
Under one of my posts I got an interesting question about ignoring maxPartitionBytes configuration entry by Apache Spark for text-based data sources. In this post I will try to answer it.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In this post I will try to explain what happens when Apache Spark reads line-based data sources like JSON line files. My goal is to prove that the framework won't split a single line, just because of the memory configuration properties and rather than that, it will take a whole line as a single unit.
Some context first
Under DataFrame and file bigger than available memory I got a pretty good comment:
1. val defaultMaxSplitBytes = 128 mb(default one,The maximum number of bytes to pack into a single partition when reading files)
2. val openCostInBytes = 4mb(The estimated cost to open a file, measured by the number of bytes could be scanned in the same time.This is used when putting multiple files into a partition. It is better to over-estimated, then the partitions with small files will be faster than partitions with bigger files (which is scheduled first)
3. val defaultParallelism = 3 [as we have mentioned 3 cores while running in local mode]
4. val totalBytes = 100 mb
5. val bytesPerCore = 100/3 = 33.3 mb
6. val maxSplitBytes = Math.min(128 mb,33.3 mb) = 33.3 mb
so if spark sql will go according to its config and setting ,then each line should be read as it will be 33.3 mb data from 100mb, i dont think any reason why it will read 100 mb instead of 33.3 mb. please resolve my confusion or any unclarity.
Just to recall, in the post, I tested Spark's behavior for the files with few very long lines. According to the comment, Spark should read every line partially but it wasn't the case. Why?
Line is line
In that specific context (.textFile data source), we work with line-separated files. The reading operation is made mainly by Hadoop classes, like shown in this schema:
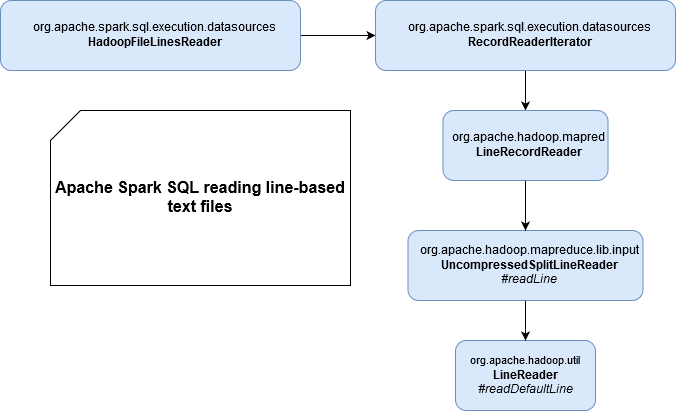
And if you analyze the call stack, you'll see that the property responsible for limiting the length of read data per line is called maxLineLength and it's set by Hadoop's mapreduce.input.linerecordreader.line.maxlength property, so Spark configuration has nothing to do here. You can see that pretty clearly in this test where we're reading at most 20 characters of the file, despite the fact of configuring spark.sql.files.maxPartitionBytes to 5000000 (or another big value):
override def beforeAll(): Unit = {
val testData =
"""1AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz
|2AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz
|3AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz
|4AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz
|5AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz""".stripMargin
FileUtils.writeStringToFile(new File(testInputFilePath), testData)
val testDataWithShortText =
s"""${testData}
|1234
|abcd""".stripMargin
FileUtils.writeStringToFile(new File(testInputFileShortDataPath), testDataWithShortText)
}
override def afterAll(): Unit = {
FileUtils.forceDelete(new File(testInputFilePath))
FileUtils.forceDelete(new File(testInputFileShortDataPath))
}
"Hadoop line length configuration" should "be taken into account when reading the files" in {
val sparkSession: SparkSession = SparkSession.builder()
.appName("Test too long lines")
.config("spark.sql.files.maxPartitionBytes ", "5000000")
.master("local[1]").getOrCreate()
sparkSession.sparkContext.hadoopConfiguration.set("mapreduce.input.linerecordreader.line.maxlength", "20")
val readText = sparkSession.read.textFile(testInputFilePath)
.collect()
readText shouldBe empty
}
As you can see, the output is empty. Before, I would expect to see here the truncated lines up to "20" characters but after analyzing the implementation, the empty result is quite logical. How does the algorithm work? It starts by looking for the newline character iteratively, going line by line. It updates then the variable storing the number of bytes to read from the input stream. The whole process is present in readDefaultLine(Text str, int maxLineLength, int maxBytesToConsume) of org.apache.hadoop.util.LineReader class:
for (; bufferPosn < bufferLength; ++bufferPosn) { //search for newline
if (buffer[bufferPosn] == LF) {
newlineLength = (prevCharCR) ? 2 : 1;
++bufferPosn; // at next invocation proceed from following byte
break;
}
if (prevCharCR) { //CR + notLF, we are at notLF
newlineLength = 1;
break;
}
prevCharCR = (buffer[bufferPosn] == CR);
}
int readLength = bufferPosn - startPosn;
if (prevCharCR && newlineLength == 0) {
--readLength; //CR at the end of the buffer
}
bytesConsumed += readLength;
Later, it truncates the line depending on the allowed length:
int appendLength = readLength - newlineLength;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
if (appendLength > 0) {
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
Logically then, Spark should return the lines with 20 characters. However, the reading part doesn't stop here. The readDefaultLine method returns the bytes consumed from the file and it's called by LineRecordReader's nextKeyValue() method which in its turn is called by RecordReaderIterator hasNext method. nextKeyValue tries to find the next valid line to return to the client, thus it's here where too long lines are skipped:
while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {
// ...
// BK: newSize = bytesConsumed from above snippets, ie.
// the whole line length, even if it's longer
// than the limit
if ((newSize == 0) || (newSize < maxLineLength)) {
break;
}
// Note BK: break from the previous line ensures
// that the line length is fine.
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " +
(pos - newSize));
}
if (newSize == 0) {
key = null;
value = null;
return false;
} else {
return true;
}
And if you check the logs, you will retrieve the logged text inside:
INFO Skipped line of size 55 at pos 55 (org.apache.hadoop.mapreduce.lib.input.LineRecordReader:195) INFO Skipped line of size 55 at pos 110 (org.apache.hadoop.mapreduce.lib.input.LineRecordReader:195) INFO Skipped line of size 55 at pos 165 (org.apache.hadoop.mapreduce.lib.input.LineRecordReader:195) INFO Skipped line of size 53 at pos 220 (org.apache.hadoop.mapreduce.lib.input.LineRecordReader:195) INFO Skipped line of size 55 at pos 218 (org.apache.hadoop.mapreduce.lib.input.LineRecordReader:195)
The nextKeyValue never returns true because it always reaches the end of the file and is unable to find any valid line before! The behavior will be different for the lines fitting into the maxlength limit. Let's confirm that on another learning test where the maxlength property is bigger than the lines from the file (4):
"a line shorter than the limit" should "be returned at reading" in {
val sparkSession: SparkSession = SparkSession.builder()
.appName("Test too long lines with one good line")
.config("spark.sql.files.maxPartitionBytes ", "5000000")
.master("local[1]").getOrCreate()
sparkSession.sparkContext.hadoopConfiguration.set("mapreduce.input.linerecordreader.line.maxlength", "20")
val readText = sparkSession.read.textFile(testInputFileShortDataPath)
.collect()
readText should have size 2
readText should contain allOf("1234", "abcd")
}
And to prove my sayings, you can see the execution of the 2 above tests with debug mode. The first execution, for the files with longer lines, shows that there is a single pass on nextKeyValue() which returns false because it reached the end of the file. The second execution shows the opposite - every nextKeyValue() call corresponds to one read line, since the boundaries are respected:
As you can see, reading text and line-based files is a little bit special. The configuration that you should use to control the amount of read data is mapreduce.input.linerecordreader.line.maxlength. What about maxPartitionBytes then? I planned to write something about it soon.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
In the first post in 2020 (Happy New Year btw ?) I analyzed why #ApacheSpark #SparkSQL can skip some lines for text files processing https://t.co/BSN9vGHhsu
— Bartosz Konieczny (@waitingforcode) January 4, 2020