
_SUCCESS file generated by Apache Spark SQL when you successfully generate a dataset, is often a big question for newcomers. Why does the framework need this file? How is it generated? I will cover these aspects in this article.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In the first part of this post I will explain the classes involved in writing files and the interaction between them during the stage of private processing. In the second part, I will go to the main topic of this post and check when and how _SUCCESS file is generated.
From attempt to candidates
To introduce the classes involved in the physical writing of the files, I will introduce this first diagram:
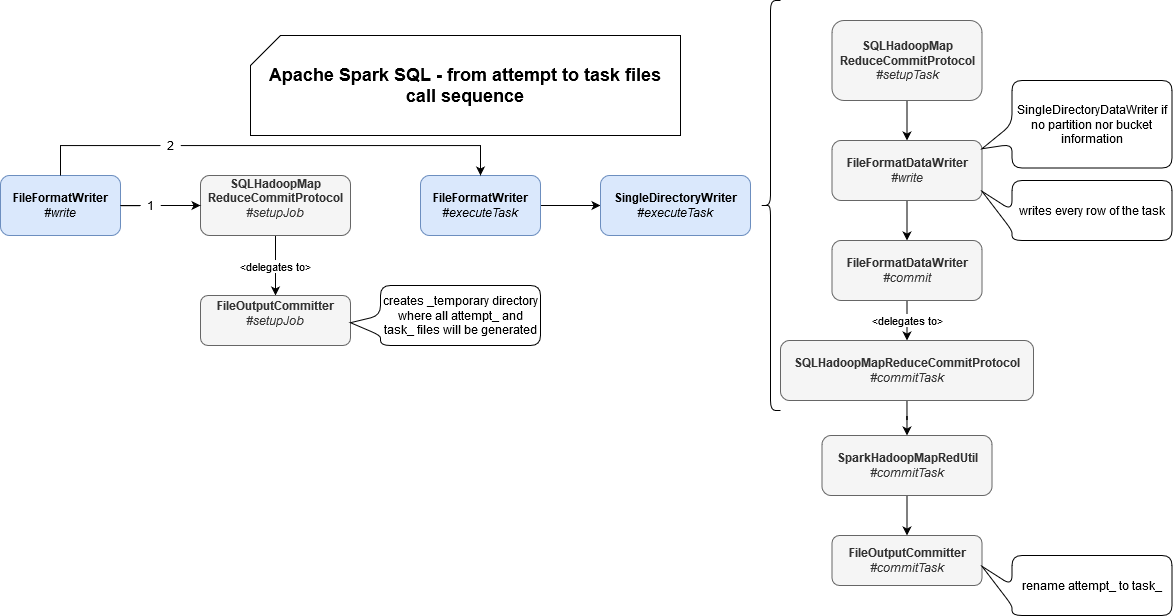
What happens here is that the first step made by the FileFormatWriter instance is to create a _temporary directory under the directory of your final destination. This temporary directory is attempt-based, since its name is exposed by getJobAttemptPath(JobContext context) method of FileOutputCommitter. Once created, the physical writing of files starts.
The physical write also starts with a setup stage where nothing happens for FileOutputCommitter called under-the-hood by SQLHadoopMapReduceCommitProtocol. Later, the real writing begins by creating an appropriate instance of the FileFormatDataWriter which for our case, ie. the case when we don't use partitions and buckets, will be SingleDirectoryDataWriter. It starts by creating a new file for the task in attempt_ directory. Data is first physically written to the attempt and once the task succeeds, it's committed in its turn from commitTask(taskContext: TaskAttemptContext). This commit consists on renaming attempt_ files into task_ files by delegating the call to SparkHadoopMapRedUtil.commitTask which, in its turn, will call FileOutputCommitter commitTask(TaskAttemptContext context, Path taskAttemptPath) method:
override def commitTask(taskContext: TaskAttemptContext): TaskCommitMessage = {
val attemptId = taskContext.getTaskAttemptID
SparkHadoopMapRedUtil.commitTask(
committer, taskContext, attemptId.getJobID.getId, attemptId.getTaskID.getId)
new TaskCommitMessage(addedAbsPathFiles.toMap -> partitionPaths.toSet)
}
// FileOutputCommitter
public void commitTask(TaskAttemptContext context, Path taskAttemptPath)
throws IOException {
// ...
if(!fs.rename(taskAttemptPath, committedTaskPath)) {
throw new IOException("Could not rename " + taskAttemptPath + " to "
+ committedTaskPath);
}
// ...
The whole operation of converting attempt to task files look like in this snippet (S3 tests):
# before task commit tmp/test-output-files/_temporary/0/_temporary/attempt_20200209133656_0000_m_000000_0/part-00000-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json tmp/test-output-files/_temporary/0/_temporary/attempt_20200209133656_0000_m_000001_1/part-00001-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json tmp/test-output-files/_temporary/0/_temporary/attempt_20200209133656_0000_m_000002_2/part-00002-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json tmp/test-output-files/_temporary/0/_temporary/attempt_20200209133656_0000_m_000003_3/part-00003-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json tmp/test-output-files/_temporary/0/_temporary/attempt_20200209133656_0000_m_000004_4/part-00004-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json tmp/test-output-files/_temporary/0/_temporary/attempt_20200209133656_0000_m_000005_5/part-00005-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json # VS # after task commit tmp/test-output-files/_temporary/0/task_20200209133656_0000_m_000000/part-00000-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json tmp/test-output-files/_temporary/0/task_20200209133656_0000_m_000001/part-00001-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json tmp/test-output-files/_temporary/0/task_20200209133656_0000_m_000002/part-00002-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json tmp/test-output-files/_temporary/0/task_20200209133656_0000_m_000003/part-00003-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json tmp/test-output-files/_temporary/0/task_20200209133656_0000_m_000004/part-00004-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json tmp/test-output-files/_temporary/0/task_20200209133656_0000_m_000005/part-00005-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json
Job confirmation
But Apache Spark doesn't stop here. It continues by following this path:
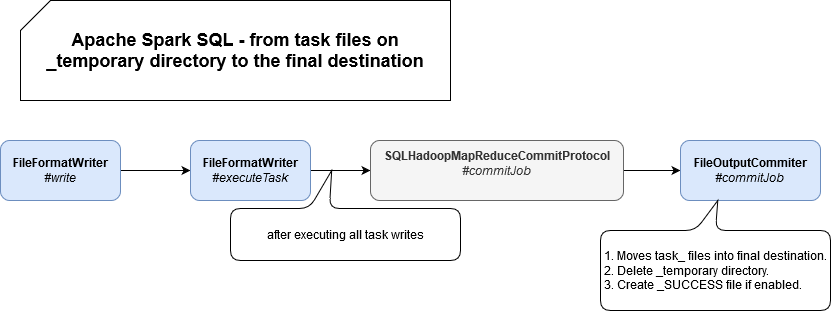
As you can see, file writer has a transactional context with the commitJob(jobContext: JobContext, taskCommits: Seq[TaskCommitMessage]) method which, once again, delegates most of its job to the FileOutputCommiter from Hadoop project. And that's where the "magic" happens. By "magic" I mean the fact of "renaming" files from a temporary location into the final place, cleaning temporary workspace and creating _SUCCESS file, that was the reason for this article. But the _SUCCESS is not created every time. Its generation is conditioned by mapreduce.fileoutputcommitter.marksuccessfuljobs property that by default is set to true.
I took a snapshot of S3 during the migration with aws s3 ls s3://test-bucket/tmp/test-output-files/ --recursive --human-readable where some of task files were promoted and some others still remained in the task_ directories:
2020-02-09 13:40:35 0 Bytes tmp/test-output-files/_temporary/0/_temporary/ 2020-02-09 13:41:15 0 Bytes tmp/test-output-files/_temporary/0/task_20200209133656_0000_m_000000/ 2020-02-09 13:41:21 0 Bytes tmp/test-output-files/_temporary/0/task_20200209133656_0000_m_000001/ 2020-02-09 13:41:24 0 Bytes tmp/test-output-files/_temporary/0/task_20200209133656_0000_m_000002/ 2020-02-09 13:41:27 0 Bytes tmp/test-output-files/_temporary/0/task_20200209133656_0000_m_000003/ 2020-02-09 13:40:34 27 Bytes tmp/test-output-files/_temporary/0/task_20200209133656_0000_m_000004/part-00004-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json 2020-02-09 13:40:35 27 Bytes tmp/test-output-files/_temporary/0/task_20200209133656_0000_m_000005/part-00005-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json 2020-02-09 13:41:14 27 Bytes tmp/test-output-files/part-00000-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json 2020-02-09 13:41:21 27 Bytes tmp/test-output-files/part-00001-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json 2020-02-09 13:41:24 27 Bytes tmp/test-output-files/part-00002-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json 2020-02-09 13:41:27 27 Bytes tmp/test-output-files/part-00003-d5cca9d3-361a-4505-953b-f0d641d2fb7a-c000.json
I wrote "transactional" not by mistake because the framework also manages the abort with FileOutputCommitter abortJob(JobContext context, JobStatus.State state). However, it's not a pure transaction because, in case of error, only the part containing temporary data is removed. It means that you can retrieve a part of copied files on your final destination, which explains, by the way, the motivation behind _SUCCESS. In other words, _SUCCESS is there to control whether downstream processes can consume the generated data.
Such logic of file generation is very helpful to quite easily start downstream processing as soon as the _SUCCESS file is generated. On the other hand, if you want to apply more reactive processing, like event-based and process every file as soon as it's written on the file system, it will be a little bit tricky. As you saw, abortJob doesn't clean up all created resources by only the ones in _temporary directory which can lead to partially generated and exposed datasets. This issue can be mitigated by the use of staging area but in that case, you will need to complexify your processing logic a little bit.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
Today I wrote an article with a clickbait title - "#ApacheSpark success anatomy". But no worries, it will be technical, and more exactly about _SUCCESS files ? https://t.co/kIi6k3Vt3I
— Bartosz Konieczny (@waitingforcode) March 28, 2020