
The .withColumn function is apparently an inoffensive operation, just a way to add or change a column. True, but also hides some points that can even lead to the memory issues and we'll see them in this blog post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
To demonstrate some of the withColumn specificites I'll use the following schema taken from web sessions data generator I wrote 2 years ago:
root |-- visit_id: string (nullable = true) |-- user_id: long (nullable = false) |-- event_time: timestamp (nullable = true) |-- page: struct (nullable = true) | |-- current: string (nullable = true) | |-- previous: string (nullable = true) |-- source: struct (nullable = true) | |-- site: string (nullable = true) | |-- api_version: string (nullable = true) |-- user: struct (nullable = true) | |-- ip: string (nullable = true) | |-- latitude: double (nullable = false) | |-- longitude: double (nullable = false) |-- technical: struct (nullable = true) | |-- browser: string (nullable = true) | |-- os: string (nullable = true) | |-- lang: string (nullable = true) | |-- network: string (nullable = true) | |-- device: struct (nullable = true) | | |-- type: string (nullable = true) | | |-- version: string (nullable = true) |-- keep_private: boolean (nullable = false)
And this small dataset:
{"visit_id": "1", "source": {"site": "localhost"}, "technical": {"browser": {"name": "Firefox", "language": "en"}, "device": {"type": "smartphone"}, "network": "network 1"}}
{"visit_id": "2", "source": {"site": "localhost"}, "technical": {"browser": "Firefox", "lang": "en", "device": {"type": "smartphone"},"network": {"short_name": "n1", "long_name": "network 1"}}}
{"visit_id": "3", "source": {"site": "www.localhost"}, "technical": {"browser": "Firefox", "lang": "en", "device": {"type": "smartphone"}, "network": "network 1"}}
{"visit_id": "4", "source": {"site": "localhost"}, "technical": {"browser": "Firefox", "lang": "en", "device": {"type": {"name": "smartphone"}}, "network": "network 1"}}
{"visit_id": "5", "source": {"site": "localhost"}, "technical": {"browser": "Firefox", "lang": "en", "device": {"type": "smartphone"}, "network": "network 1"}}
As you can see, some of the fields are inconsistent, and for example the network for the 2nd visit is a struct instead of string. The code used to illustrate different specificities of the .withColumn tends to fix them. You can do pretty much the same with a map operation, and probably it will be a clearer solution. Why? Let me show you the problems I faced while transforming a map-based cleansing into the one relying on the withColumn method.
Memory problem
Can we face a memory problem with the dataset of 6 lines running on a local machine? Unfortunately, yes. But the problem will arise only with a specific usage of the withColumn method which can be one of the following:
-
testSparkSession.read.text(outputDir) .select(functions.from_json($"value", EventLog.Schema).as("value")) .withColumn("value", anonymizeUser()) .withColumn("value", cleanseBrowser()) .withColumn("value", cleanseDevice()) .withColumn("value", cleanseNetwork()) .withColumn("value", cleanseSource()) .withColumn("value", functions.to_json($"value")) def cleanseBrowser(): Column = { functions.when(col("value.technical.browser").startsWith("{"), col("value").withField("technical.browser", get_json_object(col("value.technical.browser"), "$.name")) .withField("technical.lang", get_json_object(col("value.technical.browser"), "$.language")) ).otherwise(col("value")).write.mode("overwrite").text("/tmp/some_output") } def cleanseDevice(): Column = { functions.when(col("value.technical.device.type").startsWith("{"), col("value").withField("technical.device.type", get_json_object(col("value.technical.device.type"), "$.name")) ).otherwise(col("value")) } def cleanseNetwork(): Column = { functions.when(col("value.technical.network").startsWith("{"), col("value").withField("technical.network", get_json_object(col("value.technical.network"), "$.long_name")) ).otherwise(col("value")) } def cleanseSource(): Column = { val wwwPrefix = "www." functions.when(col("value.source.site").startsWith(wwwPrefix), col("value").withField("source.site", functions.ltrim(col("value.source.site"), wwwPrefix)) ).otherwise(col("value")) } def anonymizeUser(): Column = { functions.when(functions.col("value.keep_private").eqNullSafe(true), functions.col("value").withField("user", functions.lit(null: String))) .otherwise(functions.col("value")) } -
testSparkSession.read.text(outputDir) .select(functions.from_json($"value", EventLog.Schema).as("value")) .withColumn("value", $"value" .withField("technical.browser", CleanserFunctionsStudy.cleanseBrowserValue("name")) .withField("technical.lang", CleanserFunctionsStudy.cleanseBrowserValue("lang")) .withField("technical.device.type", CleanserFunctionsStudy.cleanseDeviceValue()) .withField("technical.network", CleanserFunctionsStudy.cleanseNetworkValue()) ) .write.mode("overwrite").json("/tmp/some_output") def cleanseBrowserValue(t: String): Column = { if (t == "name") { functions.when(col("value.technical.browser").startsWith("{"), get_json_object(col("value.technical.browser"), "$.name") ).otherwise(col("value.technical.browser")) } else { functions.when(col("value.technical.browser").startsWith("{"), get_json_object(col("value.technical.browser"), "$.language") ).otherwise(col("value.technical.lang")) } } def cleanseDeviceValue(): Column = { functions.when(col("value.technical.device.type").startsWith("{"), get_json_object(col("value.technical.device.type"), "$.name") ).otherwise(col("value.technical.device.type")) } def cleanseNetworkValue(): Column = { functions.when(col("value.technical.network").startsWith("{"), get_json_object(col("value.technical.network"), "$.long_name") ).otherwise(col("value.technical.network")) } def cleanseSourceValue(): Column = { val wwwPrefix = "www." functions.when(col("value.source.site").startsWith(wwwPrefix), functions.ltrim(col("value.source.site"), wwwPrefix) ).otherwise(col("value.source.site")) } -
testSparkSession.read.text(outputDir) .select(functions.from_json($"value", EventLog.Schema).as("value")) .select("value.*") .withColumn("user", CleanserFunctionsStudy.anonymizeUserExtracted()) .withColumn("technical", CleanserFunctionsStudy.cleanseBrowserExtracted()) .withColumn("technical", CleanserFunctionsStudy.cleanseDeviceExtracted()) .withColumn("technical", CleanserFunctionsStudy. cleanseNetworkExtracted()) .withColumn("source", CleanserFunctionsStudy.cleanseSourceExtracted()) .withColumn("value", functions.to_json(functions.struct("*"))) .select("value") .write.mode("overwrite").text("/tmp/some_output") def cleanseBrowserExtracted(): Column = { functions.when(col("technical.browser").startsWith("{"), col("technical").withField("browser", get_json_object(col("technical.browser"), "$.name")) .withField("lang", get_json_object(col("technical.browser"), "$.language")) ).otherwise(col("technical")) } def cleanseDeviceExtracted(): Column = { functions.when(col("technical.device.type").startsWith("{"), col("technical").withField("device.type", get_json_object(col("technical.device.type"), "$.name")) ).otherwise(col("technical")) } def cleanseNetworkExtracted(): Column = { functions.when(col("technical.network").startsWith("{"), col("technical").withField("network", get_json_object(col("technical.network"), "$.long_name")) ).otherwise(col("technical")) } def cleanseSourceExtracted(): Column = { val wwwPrefix = "www." functions.when(col("source.site").startsWith(wwwPrefix), col("source").withField("site", functions.ltrim(col("source.site"), wwwPrefix)) ).otherwise(col("source")) } def anonymizeUserExtracted(): Column = { functions.when(functions.col("keep_private").eqNullSafe(true), functions.lit(null: String)) .otherwise(functions.col("user")) }
After running these snippets, I was always getting the Heap space error:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3332)
at java.lang.AbstractStringBuilder.ensureCapacityInternal(AbstractStringBuilder.java:124)
at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:448)
at java.lang.StringBuilder.append(StringBuilder.java:136)
//...
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at scala.collection.immutable.List.map(List.scala:298)
at org.apache.spark.sql.catalyst.expressions.CaseWhen.toString(conditionalExpressions.scala:179)
at java.lang.String.valueOf(String.java:2994)
at scala.collection.mutable.StringBuilder.append(StringBuilder.scala:203)
at scala.collection.immutable.Stream.addString(Stream.scala:675)
at scala.collection.TraversableOnce.mkString(TraversableOnce.scala:328)
at scala.collection.TraversableOnce.mkString$(TraversableOnce.scala:327)
at scala.collection.immutable.Stream.mkString(Stream.scala:760)
at org.apache.spark.sql.catalyst.util.package$.truncatedString(package.scala:185)
// ...
As you can see, there is something wrong with the string construction. After digging a bit into the stack trace, we can find that the class responsible for the error is PlanChangeLogger, and more exactly, the highlighted lines:
class PlanChangeLogger[TreeType <: TreeNode[_]] extends Logging {
private val logLevel = SQLConf.get.planChangeLogLevel
private val logRules = SQLConf.get.planChangeRules.map(Utils.stringToSeq)
private val logBatches = SQLConf.get.planChangeBatches.map(Utils.stringToSeq)
def logRule(ruleName: String, oldPlan: TreeType, newPlan: TreeType): Unit = {
if (!newPlan.fastEquals(oldPlan)) {
if (logRules.isEmpty || logRules.get.contains(ruleName)) {
def message(): String = {
s"""
|=== Applying Rule $ruleName ===
|${sideBySide(oldPlan.treeString, newPlan.treeString).mkString("\n")}
""".stripMargin
}
logBasedOnLevel(message)
}
}
}
As you can see, the function logs the plans comparison, so what's wrong with that, except that I'm testing the snippet with the TRACE log level? After all, the logging is supposed to be a light operation. Yes, it is, but our withColumn transformation was poorly written. Why? Let's see in the next section.
CollapseProject
Apache Spark has a logical optimization rule called CollapseProject. It'll concatenate multiple not conflicting select statements into a single node in the query plan, like in the following simplified example:
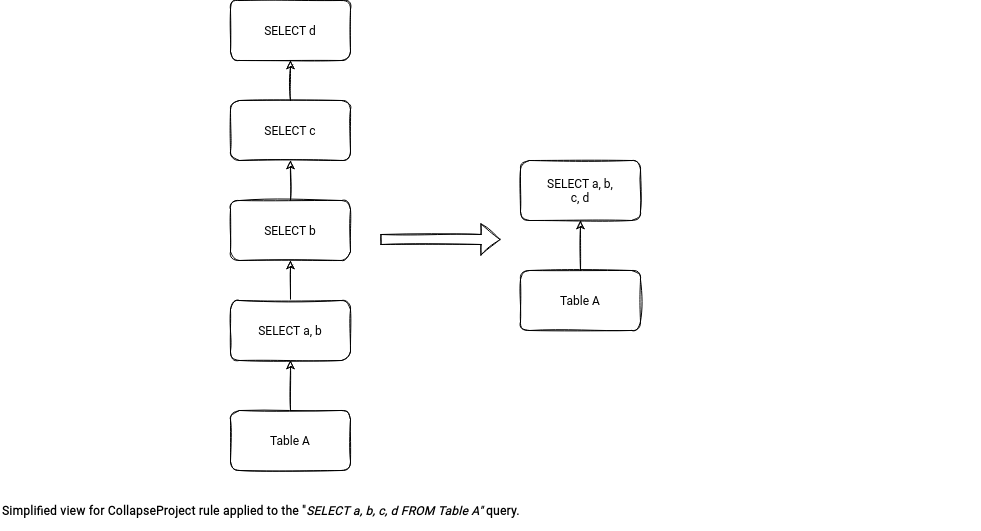
What happens with our transformation is that the value column of the struct type is never materialized for the .withColumn operations! Below you can find a fragment of the planning where you can notice plenty of from_json invocations on the stringified value column:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.CollapseProject ===
GlobalLimit 21 GlobalLimit 21
+- LocalLimit 21 +- LocalLimit 21
! +- Project [cast(value#24 as string) AS value#27] +- Project [cast(to_json(
CASE WHEN StartsWith(
CASE WHEN StartsWith(
CASE WHEN StartsWith(
CASE WHEN StartsWith(
CASE WHEN (
from_json(
StructField(visit_id,StringType,true), StructField(user_id,LongType,false), StructField(event_time,TimestampType,true),
StructField(page,StructType(StructField(current,StringType,true), StructField(previous,StringType,true)),true),
StructField(source,StructType(StructField(site,StringType,true), StructField(api_version,StringType,true)),true),
StructField(user,StructType(StructField(ip,StringType,true), StructField(latitude,DoubleType,false), StructField(longitude,DoubleType,false)),true),
StructField(technical,
StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true),
StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true
), StructField(keep_private,BooleanType,false), value#0, Some(Europe/Paris)
).keep_private <=> true)
THEN cast(
update_fields(
from_json(
StructField(visit_id,StringType,true), StructField(user_id,LongType,false), StructField(event_time,TimestampType,true),
StructField(page,StructType(StructField(current,StringType,true), StructField(previous,StringType,true)),true),
StructField(source,StructType(StructField(site,StringType,true), StructField(api_version,StringType,true)),true),
StructField(user,StructType(StructField(ip,StringType,true), StructField(latitude,DoubleType,false), StructField(longitude,DoubleType,false)),true),
StructField(technical,
StructType(StructField(browser,StringType,true), StructField(os,StringType,true),
StructField(lang,StringType,true), StructField(network,StringType,true),
StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true
), StructField(keep_private,BooleanType,false), value#0, Some(Europe/Paris)), WithField(user, null))
as struct
,source:struct,
user:struct,
technical:struct>,keep_private:boolean>
) ELSE
from_json(
StructField(visit_id,StringType,true), StructField(user_id,LongType,false), StructField(event_time,TimestampType,true),
StructField(page,StructType(StructField(current,StringType,true), StructField(previous,StringType,true)),true),
StructField(source,StructType(StructField(site,StringType,true), StructField(api_version,StringType,true)),true),
StructField(user,StructType(StructField(ip,StringType,true), StructField(latitude,DoubleType,false), StructField(longitude,DoubleType,false)),true),
StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true), StructField(network,StringType,true),
StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true),
StructField(keep_private,BooleanType,false), value#0, Some(Europe/Paris))
END.technical.browser, {)
THEN update_fields(
CASE WHEN (
from_json(
StructField(visit_id,StringType,true), StructField(user_id,LongType,false), StructField(event_time,TimestampType,true),
StructField(page,StructType(StructField(current,StringType,true), StructField(previous,StringType,true)),true),
StructField(source,StructType(StructField(site,StringType,true), StructField(api_version,StringType,true)),true),
StructField(user,StructType(StructField(ip,StringType,true), StructField(latitude,DoubleType,false), StructField(longitude,DoubleType,false)),true),
StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true),
StructField(lang,StringType,true), StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true),
StructField(version,StringType,true)),true)),true), StructField(keep_private,BooleanType,false), value#0, Some(Europe/Paris)).keep_private <=> true) THEN cast(update_fields(from_json(StructField(visit_id,StringType,true), StructField(user_id,LongType,false), StructField(event_time,TimestampType,true),
// ...
But should it lead to memory problems for a 6 rows dataset? No, this operation will definitely introduce some I/O but the memory overhead remains small in this case. The heap space error comes from the plans comparison line. The pre- and post- optimized plans became so huge that building a string for them led to the memory problems. That's the first point to keep in mind while using the .withColumn. Apache Spark, unless you somehow turn off the CollapseProject rule, will flatten the projections into a single task and any reference of the transformed column will simply copy the transformation, not the value! It's not like a variable in software programs.
.withColumn as a new column
One of the ways to solve the issue is to increase the logging level to, for example, INFO. But fixing a bug by increasing the log level sounds a bit like a workaround. To fix the root cause, my initial reflex was "let's break the select into 2 parts, one with the struct value, and one with the cleansing functions". I've done it - but I'm not proud of it, since it's also a bit hacky - by transforming the batch source into a streaming one and simulating the batch-like execution with a Trigger.Once:
def cleanseDataAndWrite(microBatch: Dataset[Row], nr: Long): Unit = {
println("Writing micro-batch")
microBatch
.withColumn("value", $"value"
.withField("technical.browser", CleanserFunctionsStudy.cleanseBrowserValue("name"))
.withField("technical.lang", CleanserFunctionsStudy.cleanseBrowserValue("lang"))
.withField("technical.device.type", CleanserFunctionsStudy.cleanseDeviceValue())
.withField("technical.network", CleanserFunctionsStudy.cleanseNetworkValue())
)
.show(false)
}
testSparkSession.readStream.text(outputDir)
.select(functions.from_json($"value", EventLog.Schema).as("value"))
.writeStream.trigger(Trigger.Once()).foreachBatch(cleanseDataAndWrite _).start().awaitTermination()
Although it works, it's still a hack. Why should we consider batch processing in terms of the streaming API? There is a proper solution using the withColumn but really creating a new column in the dataset from the from_json(value) call:
testSparkSession.read.text(outputDir)
.select(functions.from_json($"value", EventLog.Schema).as("value"))
.withColumn("cleansed_value", functions.struct(
$"value.visit_id", $"value.user_id", $"value.event_time", $"value.page", $"value.keep_private",
functions.struct(
CleanserFunctionsStudy.cleanseSourceValue().as("site"), $"value.source.api_version"
).as("source"),
functions.struct(
CleanserFunctionsStudy.cleanseBrowserValue("name"),
CleanserFunctionsStudy.cleanseBrowserValue("lang"),
CleanserFunctionsStudy.cleanseDeviceValue(),
CleanserFunctionsStudy.cleanseNetworkValue()
).as("technical")
))
.explain(true)
As you can see, the code looks very similar to the one you could write in the map function. The difference is that the input column is deserialized multiple times:
Project [
from_json(StructField(visit_id,StringType,true), StructField(user_id,LongType,false), StructField(event_time,TimestampType,true),
StructField(page,StructType(StructField(current,StringType,true), StructField(previous,StringType,true)),true),
StructField(source,StructType(StructField(site,StringType,true), StructField(api_version,StringType,true)),true),
StructField(user,StructType(StructField(ip,StringType,true), StructField(latitude,DoubleType,false), StructField(longitude,DoubleType,false)),true),
StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true),
StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true),
StructField(keep_private,BooleanType,false), value#0, Some(Europe/Paris)) AS value#2,
struct(visit_id, from_json(StructField(visit_id,StringType,true), value#0, Some(Europe/Paris)).visit_id, user_id,
from_json(StructField(user_id,LongType,false), value#0, Some(Europe/Paris)).user_id, event_time, from_json
(StructField(event_time,TimestampType,true), value#0, Some(Europe/Paris)).event_time, page, from_json
(StructField(page,StructType(StructField(current,StringType,true), StructField(previous,StringType,true)),true), value#0, Some(Europe/Paris)).page, keep_private,
from_json(StructField(keep_private,BooleanType,false), value#0, Some(Europe/Paris)).keep_private, source, struct(site, CASE WHEN
StartsWith(from_json(StructField(source,StructType(StructField(site,StringType,true), StructField(api_version,StringType,true)),true), value#0, Some(Europe/Paris)).source.site, www.) THEN
ltrim(from_json(StructField(source,StructType(StructField(site,StringType,true), StructField(api_version,StringType,true)),true), value#0, Some(Europe/Paris)).source.site, Some(www.))
ELSE from_json(StructField(source,StructType(StructField(site,StringType,true), StructField(api_version,StringType,true)),true), value#0, Some(Europe/Paris)).source.site END,
api_version,
from_json(StructField(source,StructType(StructField(site,StringType,true), StructField(api_version,StringType,true)),true), value#0, Some(Europe/Paris)).source.api_version), technical, struct(col1, CASE WHEN StartsWith(from_json(StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true), StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true), value#0, Some(Europe/Paris)).technical.browser, {) THEN get_json_object(from_json(StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true), StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true), value#0, Some(Europe/Paris)).technical.browser, $.name) ELSE from_json(StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true), StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true), value#0, Some(Europe/Paris)).technical.browser END, col2, CASE WHEN StartsWith(from_json(StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true), StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true), value#0, Some(Europe/Paris)).technical.browser, {) THEN get_json_object(from_json(StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true), StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true), value#0, Some(Europe/Paris)).technical.browser, $.language) ELSE from_json(StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true), StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true), value#0, Some(Europe/Paris)).technical.lang END, col3, CASE WHEN StartsWith(from_json(StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true), StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true), value#0, Some(Europe/Paris)).technical.device.type, {) THEN get_json_object(from_json(StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true), StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true), value#0, Some(Europe/Paris)).technical.device.type, $.name) ELSE from_json(StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true), StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true), value#0, Some(Europe/Paris)).technical.device.type END, col4, CASE WHEN StartsWith(from_json(StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true), StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true), value#0, Some(Europe/Paris)).technical.network, {) THEN get_json_object(from_json(StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true), StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true), value#0, Some(Europe/Paris)).technical.network, $.long_name) ELSE from_json(StructField(technical,StructType(StructField(browser,StringType,true), StructField(os,StringType,true), StructField(lang,StringType,true), StructField(network,StringType,true), StructField(device,StructType(StructField(type,StringType,true), StructField(version,StringType,true)),true)),true), value#0, Some(Europe/Paris)).technical.network END)) AS cleansed_value#7]
+- FileScan text [value#0] Batched: false, DataFilters: [], Format: Text, Location: InMemoryFileIndex(1 paths)[file:/tmp/spark-if-else], PartitionFilters: [], PushedFilters: [], ReadSchema: struct
The plan is still long but if you compare it with the previous one, you'll see there is no nesting. The created cleansed_value struct column indeed, calls the from_json multiple times, but these from_jsons are independent. Besides these multiple calls drawback, there is also a need to copy the input structure manually, which can be error prone.
Having that said, there is no reason to blame the .withColumn because it remains an efficient way to generate new columns from the existing ones. But keep in mind the CollapseProject rule and the fact there is no such a thing as a materialized variable. Therefore, defining all the transformations with SQL functions can be less efficient and readable than using the mapping function.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
Some time ago I tried to replace a map-based #ApacheSpark transformation by a withColumn-based one. It led to a surprising OOM error from the...logger. If you're curious about the root cause, you'll find some details in the new blog post ? https://t.co/tSidlxPDc9
— Bartosz Konieczny (@waitingforcode) April 9, 2022