
Chain of responsibility design pattern is one of my favorite's alternatives to avoid too many nested calls. Some days ago I was wondering if it could be used instead of nested calls of multiple UDFs applied in column level in Spark SQL. And the response was affirmative.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post begins by the definition of chain of responsibility design pattern. This part provides also the example that will be used in the second section, in Spark SQL learning tests.
Chain of responsibility definition
The chain of responsibility can be understood as the collection of methods invoked sequentially (= one at once). Generally, this sequence of invokable methods is stored in a general container that is directly called by the client. Under-the-hood it invokes the first method from the sequence that, in its turn invokes the second that in its turn invokes the third and so on. Below image shows the general logic of the chain of responsibility:
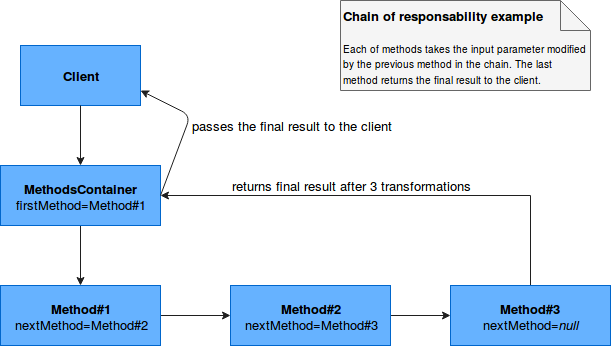
A better and more technical exploitation is described in the Chain of responsibility link added at the end of this post.
Now, let's imagine a concrete case. We want to pass a number through a series of mathematical transformations (division, subtraction, multiplication....). The basic class (= abstract Method#x from above image) could look like that:
abstract class Handler() {
private var nextHandler: Option[Handler] = None
def setNextHandler(nextHandler: Handler): Unit = {
this.nextHandler = Option(nextHandler)
}
def execute(number: Int): Int = {
val result = executeInternal(number)
if (nextHandler.isDefined) {
nextHandler.get.execute(result)
} else {
result
}
}
def executeInternal(number: Int): Int
}
As you can see, the implementations must only define the abstract executeInternal method that is invoked every time. If given handler has a successor, it computes the result variable and passes it to the next object in the chain. Concretely it leads to the following implementation:
case class MultiplicationHandler(factor: Int) extends Handler {
override def executeInternal(number: Int): Int = {
factor * number
}
}
case class SubstractionHandler(subtrahend: Int) extends Handler {
override def executeInternal(number: Int): Int = {
number - subtrahend
}
}
case class ExponentiationHandler(exponent: Int) extends Handler {
override def executeInternal(number: Int): Int = {
scala.math.pow(number, exponent).toInt
}
}
case class DivisionHandler(divisor: Int) extends Handler {
override def executeInternal(number: Int): Int = {
number/divisor
}
}
All could be orchestrated by the container implemented as so:
class ChainOfResponsibilityContainer(functions: Seq[Handler]) {
assert(functions.nonEmpty, "There should be at least 1 UDF passed to the chain of responsibility")
buildTheChain()
def execute(number: Int): Int = {
functions.head.execute(number)
}
private def buildTheChain(): Unit = {
var index = 0
while (index+1 < functions.size) {
val currentFunction = functions(index)
index += 1
val nextFunction = functions(index)
currentFunction.setNextHandler(nextFunction)
}
}
}
As you see, there are no magic here. We take the sequence of callable methods and later we build the chain by defining the dependencies between them. The execute(number) method is the departure point for chained computation.
Chain of responsibility example in Spark SQL
The example of use in Spark SQL is pretty straightforward:
val sparkSession = SparkSession.builder().appName("UDF test")
.master("local[*]").getOrCreate()
override def afterAll {
sparkSession.stop()
}
"chain of responsibility" should "be called as a container of UDFs" in {
val chainedFunctions = Seq(MultiplicationHandler(100), DivisionHandler(100), ExponentiationHandler(2),
SubstractionHandler(1))
sparkSession.udf.register("chain_of_responsibility_udf", new ChainOfResponsibilityContainer(chainedFunctions).execute _)
import sparkSession.implicits._
val letterNumbers = Seq(
("A", 50), ("B", 55), ("C", 60), ("D", 65), ("E", 70), ("F", 75)
).toDF("letter", "number")
val rows = letterNumbers.selectExpr("letter", "chain_of_responsibility_udf(number) as processedNumber")
.map(row => (row.getString(0), row.getInt(1)))
.collectAsList()
rows should contain allOf(("A", 2499), ("B", 3024), ("C", 3599), ("D", 4224), ("E", 4899), ("F", 5624))
}
Note that the code without chain of responsibility would contain 4 nested methods and it would look like in the snipped below:
val rows = letterNumbers.selectExpr("letter", "multiplication(division(exponentiation(substraction(number) as processedNumber")
.map(row => (row.getString(0), row.getInt(1)))
.collectAsList()
The chain of responsibility is a serious alternative to nested invocations of multiple unit functions. In most of cases, thanks to better separation of concerns, it improves code readability and flexibility. And as we could see through the second part of this post, this design pattern has also its utility in Spark SQL, especially for a lot of User Defined Functions applied in a single column.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Chain of responsibility design pattern in Spark SQL UDF here:
Related blog posts:
Using chain of responsibility design pattern as #ApacheSpark UDF https://t.co/Gnu0x9yz0v
— bardev (@waitingforcode) September 3, 2017