
Some weeks ago I presented correlated scalar subqueries in the example of PostgreSQL. However they can also be found in the Big Data processing systems, as for instance BigQuery or Apache Spark SQL.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
This post focuses on correlated scalar subqueries in Apache Spark SQL and presents them in 3 sections. The first two show some sample queries with correlated subquery. Both contain the code and the execution plan output. The final section summarizes them by explaining applied rules.
Correlated aggregation query
The first executed query will retrieve all articles with the number of views greater than the average number of view in their category. The query is defined in the following test case:
import SparkLocalSession.implicits._
private val SportId = 1
private val GlobalNewsId = 2
private val ArticlesDataFrame = Seq(
Article(1, SportId, "News about football", 30), Article(2, SportId, "News about tennis", 10),
Article(3, GlobalNewsId, "Global news 1", 20), Article(4, GlobalNewsId, "Global news 2", 40)
).toDF
private val CategoriesDataFrame = Seq(
Category(SportId, 2), Category(GlobalNewsId, 2)
).toDF
ArticlesDataFrame.createOrReplaceTempView("articles")
CategoriesDataFrame.createOrReplaceTempView("categories")
it should "should execute aggregation" in {
val sqlResult = SparkLocalSession.sql(
"""
|SELECT title, views FROM articles a WHERE a.views > (
| SELECT AVG(views) AS avg_views_category FROM articles WHERE categoryId = a.categoryId
| GROUP BY categoryId
|)
""".stripMargin)
val mappedResults = sqlResult.collect().map(row => s"${row.getString(0)};${row.getInt(1)}")
mappedResults should have size 2
mappedResults should contain allOf("News about football;30", "Global news 2;40")
}
The execution plan looks like that:
== Parsed Logical Plan ==
'Project ['title, 'views]
+- 'Filter ('a.views > scalar-subquery#31 [])
: +- 'Aggregate ['categoryId], ['AVG('views) AS avg_views_category#30]
: +- 'Filter ('categoryId = 'a.categoryId)
: +- 'UnresolvedRelation `articles`
+- 'SubqueryAlias a
+- 'UnresolvedRelation `articles`
== Analyzed Logical Plan ==
title: string, views: int
Project [title#6, views#7]
+- Filter (cast(views#7 as double) > scalar-subquery#31 [categoryId#5])
: +- Aggregate [categoryId#5], [avg(cast(views#7 as bigint)) AS avg_views_category#30]
: +- Filter (categoryId#5 = outer(categoryId#5))
: +- SubqueryAlias articles
: +- LocalRelation [articleId#4, categoryId#5, title#6, views#7]
+- SubqueryAlias a
+- SubqueryAlias articles
+- LocalRelation [articleId#4, categoryId#5, title#6, views#7]
== Optimized Logical Plan ==
Project [title#6, views#7]
+- Join Inner, ((cast(views#7 as double) > avg_views_category#30) && (categoryId#5#43 = categoryId#5))
:- LocalRelation [categoryId#5, title#6, views#7]
+- Filter isnotnull(avg_views_category#30)
+- Aggregate [categoryId#5], [avg(cast(views#7 as bigint)) AS avg_views_category#30, categoryId#5 AS categoryId#5#43]
+- LocalRelation [categoryId#5, views#7]
== Physical Plan ==
*(3) Project [title#6, views#7]
+- *(3) BroadcastHashJoin [categoryId#5], [categoryId#5#43], Inner, BuildRight, (cast(views#7 as double) > avg_views_category#30)
:- LocalTableScan [categoryId#5, title#6, views#7]
+- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[1, int, false] as bigint)))
+- *(2) Filter isnotnull(avg_views_category#30)
+- *(2) HashAggregate(keys=[categoryId#5], functions=[avg(cast(views#7 as bigint))], output=[avg_views_category#30, categoryId#5#43])
+- Exchange hashpartitioning(categoryId#5, 200)
+- *(1) HashAggregate(keys=[categoryId#5], functions=[partial_avg(cast(views#7 as bigint))], output=[categoryId#5, sum#46, count#47L])
+- LocalTableScan [categoryId#5, views#7]
After reading the execution plan we can see that Spark transforms the correlated subquery to an inner hash join where it broadcasts one part of the join side to executors. It happens in this specific case because one side of the relation is small enough to be send throughout the network. In other situations this plan could of course be different.
Correlated projection query
For the second example we'll see what happens with the correlated query used directly in the SELECT statement:
it should "be used in the projection" in {
val sqlResult = SparkLocalSession.sql(
"""
|SELECT a.title, a.categoryId, (
| SELECT FIRST(c.allArticles) FROM categories c WHERE c.categoryId = a.categoryId
|) AS allArticlesInCategory FROM articles a
""".stripMargin)
val mappedResults = sqlResult.collect().map(row => s"${row.getString(0)};${row.getInt(1)};${row.getInt(2)}")
mappedResults should have size 4
mappedResults should contain allOf("News about football;1;2", "News about tennis;1;2",
"Global news 1;2;2", "Global news 2;2;2")
}
The execution plan looks like:
== Parsed Logical Plan ==
'Project ['a.title, 'a.categoryId, scalar-subquery#38 [] AS allArticlesInCategory#39]
: +- 'Project [unresolvedalias(first('c.allArticles, false), None)]
: +- 'Filter ('c.categoryId = 'a.categoryId)
: +- 'SubqueryAlias c
: +- 'UnresolvedRelation `categories`
+- 'SubqueryAlias a
+- 'UnresolvedRelation `articles`
== Analyzed Logical Plan ==
title: string, categoryId: int, allArticlesInCategory: int
Project [title#6, categoryId#5, scalar-subquery#38 [categoryId#5] AS allArticlesInCategory#39]
: +- Aggregate [first(allArticles#16, false) AS first(allArticles, false)#50]
: +- Filter (categoryId#15 = outer(categoryId#5))
: +- SubqueryAlias c
: +- SubqueryAlias categories
: +- LocalRelation [categoryId#15, allArticles#16]
+- SubqueryAlias a
+- SubqueryAlias articles
+- LocalRelation [articleId#4, categoryId#5, title#6, views#7]
== Optimized Logical Plan ==
Project [title#6, categoryId#5, first(allArticles, false)#50 AS allArticlesInCategory#39]
+- Join LeftOuter, (categoryId#15 = categoryId#5)
:- LocalRelation [categoryId#5, title#6]
+- Aggregate [categoryId#15], [first(allArticles#16, false) AS first(allArticles, false)#50, categoryId#15]
+- LocalRelation [categoryId#15, allArticles#16]
== Physical Plan ==
*(3) Project [title#6, categoryId#5, first(allArticles, false)#50 AS allArticlesInCategory#39]
+- *(3) BroadcastHashJoin [categoryId#5], [categoryId#15], LeftOuter, BuildRight
:- LocalTableScan [categoryId#5, title#6]
+- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[1, int, false] as bigint)))
+- *(2) HashAggregate(keys=[categoryId#15], functions=[first(allArticles#16, false)], output=[first(allArticles, false)#50, categoryId#15])
+- Exchange hashpartitioning(categoryId#15, 200)
+- *(1) HashAggregate(keys=[categoryId#15], functions=[partial_first(allArticles#16, false)], output=[categoryId#15, first#53, valueSet#54])
+- LocalTableScan [categoryId#15, allArticles#16]
Here too the execution plan was transformed to a broadcast join and that for the same reasons as previously.
Correlated subqueries rules
Two rules related to the correlated subqueries are used in the code executed above. First of them concerns the rewriting. Both queries are rewritten to the joins because of the RewriteCorrelatedScalarSubquery rule:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.RewriteCorrelatedScalarSubquery === !Project [title#6, categoryId#5, scalar-subquery#38 [(categoryId#15 = categoryId#5)] AS allArticlesInCategory#39] Project [title#6, categoryId#5, first(allArticles, fa lse)#40 AS allArticlesInCategory#39] !: +- Aggregate [categoryId#15], [first(allArticles#16, false) AS first(allArticles, false)#40, categoryId#15] +- Project [articleId#4, categoryId#5, title#6, views #7, first(allArticles, false)#40] !: +- LocalRelation [categoryId#15, allArticles#16] +- Join LeftOuter, (categoryId#15 = categoryId#5) !+- LocalRelation [articleId#4, categoryId#5, title#6, views#7] :- LocalRelation [articleId#4, categoryId#5, ti tle#6, views#7] ! +- Aggregate [categoryId#15], [first(allArticle s#16, false) AS first(allArticles, false)#40, categoryId#15] ! +- LocalRelation [categoryId#15, allArticles #16]
The rewriting is based on the constructLeftJoins(child: LogicalPlan, subqueries: ArrayBuffer[ScalarSubquery]) method. The transformation logic is quite simple. The subquery is splitted in 2 parts: the query and the conditions joining inner and outer queries. From that it's quite easy to construct a left outer join:
subqueries.foldLeft(child) {
case (currentChild, ScalarSubquery(query, conditions, _)) =>
val origOutput = query.output.head
val resultWithZeroTups = evalSubqueryOnZeroTups(query)
if (resultWithZeroTups.isEmpty) {
// CASE 1: Subquery guaranteed not to have the COUNT bug
Project(
currentChild.output :+ origOutput,
Join(currentChild, query, LeftOuter, conditions.reduceOption(And)))
// ...
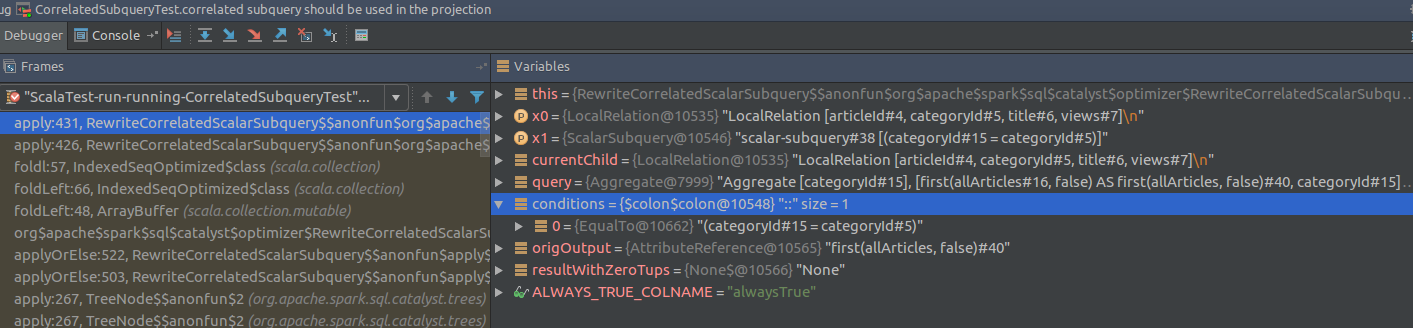
But apart this simple transformation the method handles also some bugs discovered 2 years ago that makes it more complicated than that.
Another applied rule is PullupCorrelatedPredicates. It moves the correlated predicates from the subquery to the outer query. We say then that the parts of the correlated subqueries are pulled up to the query above them. It's also known as unnesting or decorrelation. We can observe the use of this rule in the final physical plans where the filter clause was transformed to the ON condition. It's also visible earlier in the query optimization, as shown in this log fragment:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.PullupCorrelatedPredicates === !Project [title#6, categoryId#5, scalar-subquery#38 [categoryId#5] AS allArticlesInCategory#39] Project [title#6, categoryId#5, scalar-subquery#38 [(categoryId#15 = ca tegoryId#5)] AS allArticlesInCategory#39] !: +- Aggregate [first(allArticles#16, false) AS first(allArticles, false)#40] : +- Aggregate [categoryId#15], [first(allArticles#16, false) AS first (allArticles, false)#40, categoryId#15] !: +- Filter (categoryId#15 = outer(categoryId#5)) : +- SubqueryAlias c !: +- SubqueryAlias c : +- SubqueryAlias categories !: +- SubqueryAlias categories : +- LocalRelation [categoryId#15, allArticles#16] !: +- LocalRelation [categoryId#15, allArticles#16] +- LocalRelation [articleId#4, categoryId#5, title#6, views#7] !+- LocalRelation [articleId#4, categoryId#5, title#6, views#7]
The correlated subqueries in Spark SQL are rewritten to the queries where the subquery is joined to the outer one with the left outer join. It happens independently on the subquery location. As we could see in this post, the rewriting is done as well for the subqueries defined in the projection part as well for the ones from the filtering part. Two rules are involved in this transformation: RewriteCorrelatedScalarSubquery and PullupCorrelatedPredicate. The former one converts the correlated subquery to the left outer join while the latter one extracts the filtering clauses and moves them to the upper level.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Correlated scalar subqueries in Apache Spark SQL here:
- First phase: Deferring the correlated predicate pull up to Optimizer phase Support correlated scalar subquery Some correlated subqueries return incorrect answers
Related blog posts:
Correlated scalar subqueries are also present in #ApacheSparkSQL. Some examples in today's post https://t.co/3sreX5J1tk pic.twitter.com/W8vdo1zUxC
— bardev (@waitingforcode) June 24, 2018