
Some time ago I was thinking how to partition the data and ensure that we can reprocess it easily. Overwrite mode was not an option since the data of one partition could be generated by 2 different batch executions. That's why I started to think about implementing an idempotent file output generator and, therefore, discover file sink internals in practice.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The problem I will try to solve looks like in this schema:
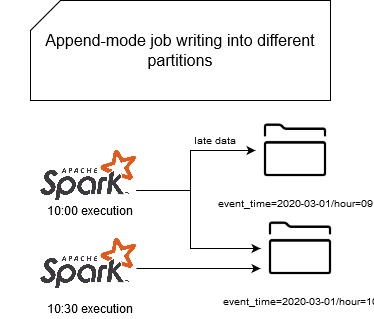
This problem can be resolved in various manners like with internal index storage that will store the generated files and delete all of them before the reprocessing. But let's suppose that we don't want to manage this extra component. Unfortunately, we cannot do that with an actual file sink because if we need to reprocess the data, it will generate the files with different names, so the duplicates. The solution that I will test here, and discover Apache Spark internals, will consist of generating the files with the same names every time. Of course, it implies that:
- tasks always process the same data - a tricky part but let's suppose that we control that aspect with, for instance, the max number of processed elements and immutable partitions for an Apache Kafka source and that the data has long enough retention period to not disappear between its first and second processings
- a task always generates the same number of files - put another way, we don't change the logic that defines the partitioning
Even though these 2 requirements are quite strong assumptions about the processing, let's suppose that they're true. As I explained at the beginning, this article is more a practical exercise to deep delve into the file sink rather than a prod-ready solution. So, the question is how, under these assumptions, always generate the same files?
Committers and commit protocols
First, if you look at the classes involved in writing data into files, you will apperceive 2 slightly similar objects, a FileCommitProtocol and an OutputCommitter. But despite their similarities, they're different. The former one comes from Apache Spark world whereas the latter from Hadoop's one. FileCommitProtocol is a wrapper for OutputCommitter since it intercepts every call from Apache Spark API and delegates its physical execution to corresponding OutputCommitter. How this relationship is present in the code? Let's take a look at some important methods of FileCommitProtocol:
override def abortJob(jobContext: JobContext): Unit = {
committer.abortJob(jobContext, JobStatus.State.FAILED)
if (hasValidPath) {
val fs = stagingDir.getFileSystem(jobContext.getConfiguration)
fs.delete(stagingDir, true)
}
}
override def setupTask(taskContext: TaskAttemptContext): Unit = {
committer = setupCommitter(taskContext)
committer.setupTask(taskContext)
// ...
}
override def abortTask(taskContext: TaskAttemptContext): Unit = {
committer.abortTask(taskContext)
// best effort cleanup of other staged files
// ...
}
As you can see, every time something happens with a task or a job, FileCommitProtocol invokes its OutputCommitter companion. You don't see it in the code because I should insert a lot of lines, but believe me (you can check if you want ;-) - HadoopMapReduceCommitProtocol.scala) that FileCommitProtocol acts more like an adapter of Hadoop writer to Apache Spark logic. You can see it for instance here, with dynamicPartitionOverwrite flag enabled:
val filesToMove = allAbsPathFiles.foldLeft(Map[String, String]())(_ ++ _)
logDebug(s"Committing files staged for absolute locations $filesToMove")
if (dynamicPartitionOverwrite) {
val absPartitionPaths = filesToMove.values.map(new Path(_).getParent).toSet
logDebug(s"Clean up absolute partition directories for overwriting: $absPartitionPaths")
absPartitionPaths.foreach(fs.delete(_, true))
}
To sum-up, in case I was unclear, FileCommitProtocol is the wrapper that controls data organization logic. OutputCommiter is the class responsible for physical data writing.
Why new file for reprocessed job?
Before we go to the part of implementation, let's stop a while and answer why a file generated for the same input dataset, with the same business rules, has a different name? The answer is hidden in InsertIntoHadoopFsRelationCommand's run(sparkSession: SparkSession, child: SparkPlan) method when the FileCommitProtocol is initialized:
val committer = FileCommitProtocol.instantiate(
sparkSession.sessionState.conf.fileCommitProtocolClass,
jobId = java.util.UUID.randomUUID().toString,
outputPath = outputPath.toString,
dynamicPartitionOverwrite = dynamicPartitionOverwrite)
An intrinsic part of the file name is the job id which, as you can see, is every time a random UUID. And that's the reason why HadoopMapReduceCommitProtocol which is one of the implementations of FileCommitProtocol, generates different names:
private def getFilename(taskContext: TaskAttemptContext, ext: String): String = {
// The file name looks like part-00000-2dd664f9-d2c4-4ffe-878f-c6c70c1fb0cb_00003-c000.parquet
// Note that %05d does not truncate the split number, so if we have more than 100000 tasks,
// the file name is fine and won't overflow.
val split = taskContext.getTaskAttemptID.getTaskID.getId
f"part-$split%05d-$jobId$ext"
}
Let me show you that I'm right by overriding the jobId at runtime:
Finally, the names generated by my hacked code were:
part-00000-xyz-c000.json part-00001-xyz-c000.json part-00002-xyz-c000.json part-00003-xyz-c000.json
What is this c000 at the end? It's the number of the file written by a given task. A task can write multiple files?! Yes! Apache Spark SQL comes with a property called spark.sql.files.maxRecordsPerFile that defines the maximal number of records per file. It's optional and by default set to 0 so it means that there is no limit but if you want to control the number of items in every file, it can be an option.
Extending committers and commit protocols
So, to guarantee the same name of the generated files, under the assumptions from the beginning of this blog post, we simply need to overwrite the job id. FileCommitProtocol.instantiate mentioned in the previous section is called on the driver. We could then use the same method we use often for Docker containers to adapt them to the executed environment (prod, staging, qa, ...) with environment variables. Below you can find my least-effort FileCommitProtocol class:
class IdempotentFileSinkCommitProtocol(jobId: String, path: String,
dynamicPartitionOverwrite: Boolean = false)
extends HadoopMapReduceCommitProtocol(jobId = System.getenv("JOB_ID"), path, dynamicPartitionOverwrite) {
}
And the code using it looks like that:
"custom commit protocol" should "always generate the same files even for append mode" in {
val sparkSession: SparkSession = SparkSession.builder()
.appName("Spark SQL custom file commit protocol")
.master("local[*]")
.config("spark.sql.sources.commitProtocolClass",
"com.waitingforcode.sql.customcommiter.IdempotentFileSinkCommitProtocol")
.getOrCreate()
import sparkSession.implicits._
val dataset = Seq(
(1, "a"), (1, "a"), (1, "a"), (2, "b"), (2, "b"), (3, "c"), (3, "c")
).toDF("nr", "letter")
dataset.write.mode(SaveMode.Append).json(outputDir)
import scala.collection.JavaConverters._
val allFiles = FileUtils.listFiles(new File(outputDir), Array("json"), false).asScala
allFiles should have size 4
// Write it once again to ensure that there are still 4 files
dataset.write.mode(SaveMode.Append).json(outputDir)
val allFilesAfterRewrite = FileUtils.listFiles(new File(outputDir), Array("json"), false).asScala
allFilesAfterRewrite should have size 4
}
object EnvVariableSimulation {
val JOB_ID = "file_committer_test"
}
Please notice that I'm simulating here the environment variables with a custom class because it's easier to make the tests executable. But in the test already you can see that despite the fact of executing the same code twice, in append mode, we always get the same outcome.
If you think that my assumptions from the introductory section are strong, I agree with you. It's hard to guarantee the same data generation logic across reprocessing. We can also have a case when some data will be expired in the source and therefore if we control the maximal number of records written per file, we can still end up with some data quality issues (phantom data in the files that shouldn't exist). Despite that, I hope you could see another way to enhance Apache Spark with your custom behavior.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
How to generate files with the same names in #ApacheSpark #SparkSQL, even in case of reprocessing? To see that, in my new blog post, I explored committers and commit protocols https://t.co/fWMAg2lzA6
— Bartosz Konieczny (@waitingforcode) May 2, 2020