
Despite working with Apache Spark for a while, I still have some undiscovered components. One of them crossed my path while I was writing the first blog post from the ACID file formats series. The lucky one is the Catalog API.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
When does Apache Spark needs catalogs?
I will start this blog post by analyzing where Apache Spark uses a catalog. For the sake of simplicity, let's keep the catalog term as something abstract, defining the tables and schemas interacting with the framework.
When does this interaction occur? To answer this question, let's analyze the stack trace of the code creating a table in a not existing namespace (CREATE TABLE inexisting.orders):
Exception in thread "main" org.apache.spark.sql.catalyst.analysis.NoSuchDatabaseException: Database 'inexisting' not found
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.requireDbExists(SessionCatalog.scala:218)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.getTableRawMetadata(SessionCatalog.scala:513)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.getTableMetadata(SessionCatalog.scala:500)
at org.apache.spark.sql.execution.datasources.v2.V2SessionCatalog.loadTable(V2SessionCatalog.scala:65)
at org.apache.spark.sql.connector.catalog.TableCatalog.tableExists(TableCatalog.java:119)
at org.apache.spark.sql.execution.datasources.v2.V2SessionCatalog.tableExists(V2SessionCatalog.scala:40)
at org.apache.spark.sql.connector.catalog.DelegatingCatalogExtension.tableExists(DelegatingCatalogExtension.java:78)
at org.apache.spark.sql.delta.catalog.DeltaCatalog.org$apache$spark$sql$delta$catalog$SupportsPathIdentifier$$super$tableExists(DeltaCatalog.scala:57)
at org.apache.spark.sql.delta.catalog.SupportsPathIdentifier.tableExists(DeltaCatalog.scala:618)
at org.apache.spark.sql.delta.catalog.SupportsPathIdentifier.tableExists$(DeltaCatalog.scala:610)
at org.apache.spark.sql.delta.catalog.DeltaCatalog.tableExists(DeltaCatalog.scala:57)
at org.apache.spark.sql.execution.datasources.v2.CreateTableExec.run(CreateTableExec.scala:40)
// ...
As you can see, the stack trace references DeltaCatalog and one of its methods checking the existence of a table. And that's the first use case, the DDL statements. The second place is the plan analysis, and more exactly the ResolveRelations logical rule:
object ResolveRelations extends Rule[LogicalPlan] {
private def lookupRelation(
identifier: Seq[String], options: CaseInsensitiveStringMap, isStreaming: Boolean): Option[LogicalPlan] = {
expandIdentifier(identifier) match {
case SessionCatalogAndIdentifier(catalog, ident) =>
lazy val loaded = CatalogV2Util.loadTable(catalog, ident).map {
case v1Table: V1Table =>
if (isStreaming) {
if (v1Table.v1Table.tableType == CatalogTableType.VIEW) {
throw QueryCompilationErrors.permanentViewNotSupportedByStreamingReadingAPIError(
identifier.quoted)
}
SubqueryAlias(
catalog.name +: ident.asMultipartIdentifier,
UnresolvedCatalogRelation(v1Table.v1Table, options, isStreaming = true))
} else {
v1SessionCatalog.getRelation(v1Table.v1Table, options)
}
case table =>
if (isStreaming) {
val v1Fallback = table match {
case withFallback: V2TableWithV1Fallback =>
Some(UnresolvedCatalogRelation(withFallback.v1Table, isStreaming = true))
case _ => None
}
SubqueryAlias(
catalog.name +: ident.asMultipartIdentifier,
StreamingRelationV2(None, table.name, table, options, table.schema.toAttributes,
Some(catalog), Some(ident), v1Fallback))
} else {
SubqueryAlias(
catalog.name +: ident.asMultipartIdentifier,
DataSourceV2Relation.create(table, Some(catalog), Some(ident), options))
}
}
Why?
Fine, the catalog gives precise information about the manipulated tables and views. But recently, it got an interesting rework aiming to facilitate the extension. Ryan Blue explained the reasons for this refactoring in the SPIP document associated to SPARK-27067. According to his analysis, the previous catalog implementation needed some evolution because of the following:
- Limits of the Catalog interface. It doesn't support partitioning and schema changes.
- DataSource V2 API inconsistency. The new API is designed to support an easier integration of new data stores in Apache Spark. However, it lacks the support for managing tables.
The implementation work has started in Apache Spark 3.0.0 and one of the master pieces of this evolution was CatalogPlugin.
CatalogPlugin
The CatalogPlugin is the primary interface for this reworked catalog abstraction. Without entering into details yet, you should understand what's going on with this component from the class hierarchy just below:
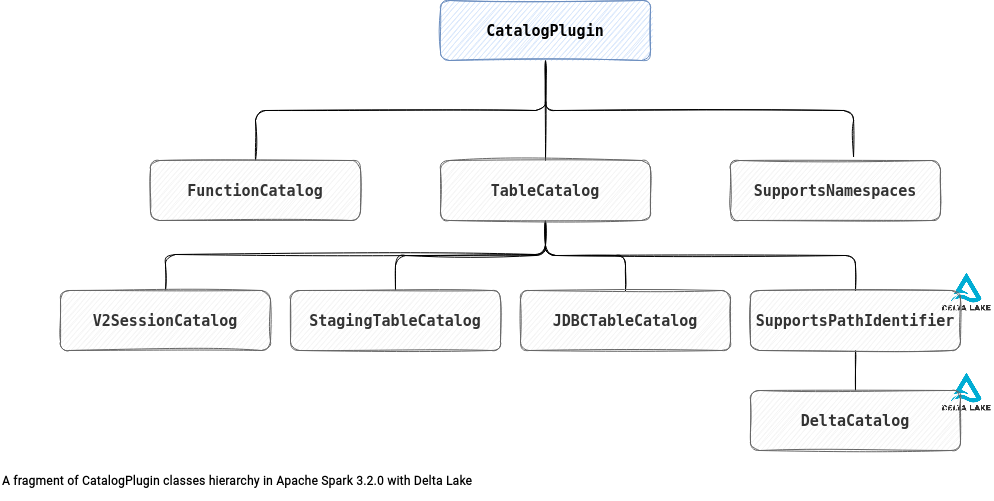
The CatalogPlugin itself is a simple and mainly descriptive interface:
public interface CatalogPlugin {
void initialize(String name, CaseInsensitiveStringMap options);
String name();
default String[] defaultNamespace() {
return new String[0];
}
}
However, the inherited interfaces and classes have more power and can perform actions on the physical data catalog. For example, the TableCatalog adds methods to manage tables (CRUD) whereas the FunctionCatalog interface exposes 2 methods to manage functions. In a short summary:
public interface FunctionCatalog extends CatalogPlugin {
Identifier[] listFunctions(String[] namespace) throws NoSuchNamespaceException;
UnboundFunction loadFunction(Identifier ident) throws NoSuchFunctionException;
}
public interface TableCatalog extends CatalogPlugin {
Identifier[] listTables(String[] namespace) throws NoSuchNamespaceException;
Table loadTable(Identifier ident) throws NoSuchTableException;
default void invalidateTable(Identifier ident) {
}
default boolean tableExists(Identifier ident) {
try {
return loadTable(ident) != null;
} catch (NoSuchTableException e) {
return false;
}
}
Table createTable(
Identifier ident,
StructType schema,
Transform[] partitions,
Map properties) throws TableAlreadyExistsException, NoSuchNamespaceException;
Table alterTable(
Identifier ident,
TableChange... changes) throws NoSuchTableException;
boolean dropTable(Identifier ident);
default boolean purgeTable(Identifier ident) throws UnsupportedOperationException {
throw new UnsupportedOperationException("Purge table is not supported.");
}
void renameTable(Identifier oldIdent, Identifier newIdent)
throws NoSuchTableException, TableAlreadyExistsException;
}
They're still the interfaces, so they're doing nothing concrete. To understand them better, let's see JdbcTableCatalog which is one of the implementations of the TableCatalog.
JdbcTableCatalog
Since RDBMS and JDBC are quite popular, analyzing the JdbcTableCatalog should be the best example to illustrate the idea of a pluggable catalog. To start, the initialization method is responsible for detecting the RDBMS type:
override def initialize(name: String, options: CaseInsensitiveStringMap): Unit = {
assert(catalogName == null, "The JDBC table catalog is already initialed")
catalogName = name
val map = options.asCaseSensitiveMap().asScala.toMap
this.options = new JDBCOptions(map + (JDBCOptions.JDBC_TABLE_NAME -> "__invalid_dbtable"))
dialect = JdbcDialects.get(this.options.url)
}
These 2 variables, options and dialect, are used throughout the code to establish a database connection, define a correct format for the table names, or control various query parameters such as timeout.
The JdbcTableCatalog is not the catalog implementation but a bridge between Apache Spark and the RDBMS. You can notice that in the table management operations. Each time, the table catalog opens a connection to the database and runs the appropriate SQL query within it:
class JDBCTableCatalog extends TableCatalog with SupportsNamespaces with Logging {
// ...
override def dropTable(ident: Identifier): Boolean = {
checkNamespace(ident.namespace())
withConnection { conn =>
try {
JdbcUtils.dropTable(conn, getTableName(ident), options)
true
} catch {
case _: SQLException => false
}
}
}
override def renameTable(oldIdent: Identifier, newIdent: Identifier): Unit = {
checkNamespace(oldIdent.namespace())
withConnection { conn =>
classifyException(s"Failed table renaming from $oldIdent to $newIdent") {
JdbcUtils.renameTable(conn, getTableName(oldIdent), getTableName(newIdent), options)
}
}
}
// ...
}
That's an example and I hope it's pretty meaningful. However, if you take a closer look at the configuration, you might see something confusing, the spark_catalog.
spark_catalog
Besides the pluggable catalog interface, the spark.sql.catalog.spark_catalog configuration property is another new thing in Apache Spark 3.0.0. The documentation explains that:
A catalog implementation that will be used as the v2 interface to Spark's built-in v1 catalog: spark_catalog. This catalog shares its identifier namespace with the spark_catalog and must be consistent with it; for example, if a table can be loaded by the spark_catalog, this catalog must also return the table metadata. To delegate operations to the spark_catalog, implementations can extend 'CatalogExtension'.
But I must admit, it's a bit confusing for a newcomer to the topic. To answer why we need this mix, v1 vs v2 catalogs, is again hidden in the code. Below, you can find a comment from the CatalogManager class that I will introduce in the next section. For now, it's sufficient to know that it manages catalog instances to use in the queries:
/**
* // ...
*
* There are still many commands (e.g. ANALYZE TABLE) that do not support v2 catalog API. They
* ignore the current catalog and blindly go to the v1 `SessionCatalog`. To avoid tracking current
* namespace in both `SessionCatalog` and `CatalogManger`, we let `CatalogManager` to set/get
* current database of `SessionCatalog` when the current catalog is the session catalog.
*/
private[sql]
class CatalogManager(
defaultSessionCatalog: CatalogPlugin,
val v1SessionCatalog: SessionCatalog) extends SQLConfHelper with Logging {
// ...
Not all the operations are ready to run against the V2 catalog. That's why Apache Spark still needs the V1 SessionCatalog and some abstraction to translate the V2 calls to V1. By default, this abstraction is V2SessionCatalog but if you need to replace it, you can do it inside the aforementioned spark.sql.catalog.spark_catalog configuration.
And this V1SessionCatalog can be used every time! Even when you define a custom implementation in the spark_catalog config, under-the-hood, you can extend this class with a CatalogExtension interface to delegate some of the logic to the V2SessionCatalog [= to interact with V1 catalog]. For example, DeltaCatalog uses this extension to delegate all catalog calls but the Delta Lake ones to V2SessionCatalog:
class DeltaCatalog extends DelegatingCatalogExtension with StagingTableCatalog with SupportsPathIdentifier with Logging {
// ...
override def loadTable(ident: Identifier): Table = {
try {
super.loadTable(ident) match {
case v1: V1Table if DeltaTableUtils.isDeltaTable(v1.catalogTable) =>
DeltaTableV2(
spark,
new Path(v1.catalogTable.location),
catalogTable = Some(v1.catalogTable),
tableIdentifier = Some(ident.toString))
case o => o
}
// ...
The class responsible for the delegation injection is CatalogManager:
class CatalogManager(
defaultSessionCatalog: CatalogPlugin,
val v1SessionCatalog: SessionCatalog) extends SQLConfHelper with Logging {
import CatalogManager.SESSION_CATALOG_NAME
import CatalogV2Util._
private def loadV2SessionCatalog(): CatalogPlugin = {
Catalogs.load(SESSION_CATALOG_NAME, conf) match {
case extension: CatalogExtension =>
extension.setDelegateCatalog(defaultSessionCatalog)
extension
case other => other
}
}
Loading a catalog
The CatalogManager is also the class called when you switch the namespace with the USE NAMESPACE or USE operations:
case class SetCatalogAndNamespaceExec(
catalogManager: CatalogManager, catalogName: Option[String],
namespace: Option[Seq[String]]) extends LeafV2CommandExec {
override protected def run(): Seq[InternalRow] = {
catalogName.foreach(catalogManager.setCurrentCatalog)
namespace.foreach(ns => catalogManager.setCurrentNamespace(ns.toArray))
Seq.empty
}
During this operation, the manager also changes its current catalog instance. Internally, the CatalogManager keeps a map of the catalogs and updates this container each time it has to load a new catalog:
class CatalogManager(defaultSessionCatalog: CatalogPlugin, val v1SessionCatalog: SessionCatalog) extends SQLConfHelper with Logging {
// ...
private val catalogs = mutable.HashMap.empty[String, CatalogPlugin]
def catalog(name: String): CatalogPlugin = synchronized {
if (name.equalsIgnoreCase(SESSION_CATALOG_NAME)) {
v2SessionCatalog
} else {
catalogs.getOrElseUpdate(name, Catalogs.load(name, conf))
}
}
The Catalogs.load method initializes a new instance of the catalog (CatalogPlugin) from the config prefixed with the spark.sql.catalog.:
def load(name: String, conf: SQLConf): CatalogPlugin = {
val pluginClassName = try {
conf.getConfString("spark.sql.catalog." + name)
} catch {
case _: NoSuchElementException =>
throw QueryExecutionErrors.catalogPluginClassNotFoundError(name)
}
val loader = Utils.getContextOrSparkClassLoader
try {
val pluginClass = loader.loadClass(pluginClassName)
if (!classOf[CatalogPlugin].isAssignableFrom(pluginClass)) {
throw QueryExecutionErrors.catalogPluginClassNotImplementedError(name, pluginClassName)
}
val plugin = pluginClass.getDeclaredConstructor().newInstance().asInstanceOf[CatalogPlugin]
plugin.initialize(name, catalogOptions(name, conf))
plugin
} catch {
// ...
}
}
You certainly see here the initialize method from the beginning of the blog post.
In a nutshell:
- The catalog is used in DDL operations and the plan analysis stage.
- Apache Spark has an "old" V1 Catalog interface that is not adapted to the modern data sources, though.
- The operations not supporting V2 pluggable catalog still needs V1's catalog (SessionCatalog).
- V2SessionCatalog is the bridge between the V1 and V2 world. It's the default implementation that can be overridden by a custom class from spark.sql.catalog.spark_catalog.
- CatalogPlugin is the entrypoint for the V2 catalogs.
- You'll see the proof in other blog posts, but the CatalogPlugin is widely used in the new ACID file formats.
The new pluggable catalog is intended to facilitate things and better integrate with modern V2 data sources. However, it has to still live alongside the V1 catalog, as long as the remaining operations don't support the CatalogPlugin implementations.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
Apache Spark 3 has brought a new catalog API. I somehow had missed it in the "What's new ..." series and decided to present the feature this week, in this blog post ? https://t.co/g5UyQ52RuL
— Bartosz Konieczny (@waitingforcode) April 16, 2022