
I didn't know that join reordering is quite interesting, though complex, topic in Apache Spark SQL. The queries not only can be transformed into the ones using JOIN ... ON clauses. They can also be reordered accordingly to the star schema which we'll try to see in this post.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In the first section I will define star schema and show a pretty classic example of it. In the next part, I will deep delve into the star schema optimization code. In the last section, I will play with an example to see star schema optimization in action.
Star schema
Star schema is a data modeling approach which identifies 2 kinds of source tables called dimensions table or fact table. The fact table stores the information referencing parameters stored inside dimensions tables. A popular example to illustrate that uses sales information. In that context, the fact table, so the table with events or observations, contains all sales made for a particular store, by a given employee, for a particular product(s) and at a specific date (dimension tables) by a specific customer. The difference between fact and dimension tables is that the dimension tables usually contain less data. You can see that by analyzing the sale date table. As you can deduce, one or multiple orders can be made for one specific day. Star schema can be easily summarized as:
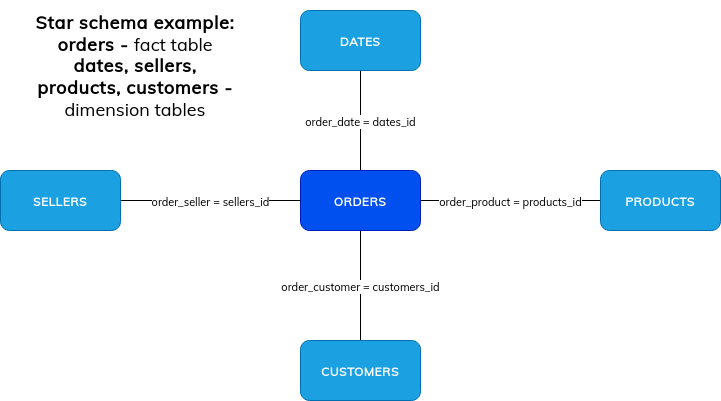
Star schema optimization in Apache Spark
Internally, the class responsible for star schema optimization is org.apache.spark.sql.catalyst.optimizer.StarSchemaDetection. It exposes 2 methods, findStarJoins(input: Seq[LogicalPlan], conditions: Seq[Expression]) responsible for a sequence of LogicalPlans where the head corresponds to a fact table and the rest to all involved dimension tables. The second exposed method is reorderStarJoins(input: Seq[(LogicalPlan, InnerLike)], conditions: Seq[Expression]) that reorder joins based on heuristics when CBO is disabled. Here, I'll focus on findStarJoins because under-the-hood reorderStarJoins uses it to figure out the fact and dimension tables.
findStarJoins considers that there is any possible star schema if there are at least 2 joined tables having counted rows number and being the logical plan nodes without children. In other words, anything else than *Relation or *RelationV2 will be invalid. Among the examples of valid nodes, you will find for instance HiveTableRealtion or DataSourceV2Relation. To find all eligible implementations, check the children classes for LeafNode.
Once all these criteria are met, star schema detector sorts all tables in descending order by the number of rows. Later it checks if the 2 biggest tables are sufficiently different to be involved in a star schema. The sufficiency is controlled by table#2 rows count > table#1 rows count * spark.sql.cbo.starJoinFTRatio. It means that if the number of rows is comparable (10% difference, e.g. 100 rows for the biggest and 90 rows for the 2nd biggest table), then the star schema won't be created.
But since we want to understand star schema optimization, let's suppose that the difference is big enough. The next step of the algorithm consists of finding all ON clauses joining the fact and dimension tables. Once this is done, the engine checks again the availability of the statistics. This time the check is made on the columns used in join operations on the dimension tables side. Column statistics are represented by this class and as you can see, they contain basic math statistics but also more advanced information like values distinctiveness or distribution:
case class ColumnStat(
distinctCount: Option[BigInt] = None,
min: Option[Any] = None,
max: Option[Any] = None,
nullCount: Option[BigInt] = None,
avgLen: Option[Long] = None,
maxLen: Option[Long] = None,
histogram: Option[Histogram] = None)
If at least one column from the join doesn't have generated statistics, the star join will be aborted. Otherwise, the final filtering happens. In this stage, the algorithm filters are joins that are not equi-joins, so it will keep the queries like JOIN x ON x.id = y.id and not the queries like JOIN x ON x.id > y.id. At the same time, the algorithm ensures that the column from the dimension table is unique. It means that the relationship between distinct and total number of rows fits into abs((# distinct/# all) - 1) <= spark.sql.statistics.ndv.maxError * 2 where the maxError property is the max estimation error allowed for HyperLogLog++ algorithm during the column statistics generation.
If after the last filtering there are at least 2 dimension tables, they're added to the fact table and returned as the final sequence:
if (eligibleDimPlans.isEmpty || eligibleDimPlans.size < 2) {
// An eligible star join was not found since the join is not
// an RI join, or the star join is an expanding join.
// Also, a star would involve more than one dimension table.
emptyStarJoinPlan
} else {
factTable +: eligibleDimPlans
}
Star joins
Star join optimization is a part of CBO reorder join covered previous week. That's the reason why to show you how Apache Spark handles star schema optimization, I will use this short video with debugging code for:
override def beforeAll(): Unit = {
if (!new File(baseDir).exists()) {
val veryBigTable = "very_big_table"
val bigTable = "big_table"
val smallTable1 = "small_table1"
val smallTable2 = "small_table2"
val smallTable3 = "small_table3"
val configs = Map(
veryBigTable -> 5000,
bigTable -> 1500,
smallTable1 -> 800,
smallTable2 -> 200,
smallTable3 -> 300
)
configs.foreach {
case (key, maxRows) => {
val data = (1 to maxRows).map(nr => nr).mkString("\n")
val dataFile = new File(s"${baseDir}${key}")
FileUtils.writeStringToFile(dataFile, data)
val id = s"${key}_id"
sparkSession.sql(s"DROP TABLE IF EXISTS ${key}")
sparkSession.sql(s"CREATE TABLE ${key} (${id} INT) USING hive OPTIONS (fileFormat 'textfile', fieldDelim ',')")
sparkSession.sql(s"LOAD DATA LOCAL INPATH '${dataFile.getAbsolutePath}' INTO TABLE ${key}")
sparkSession.sql(s"ANALYZE TABLE ${key} COMPUTE STATISTICS FOR COLUMNS ${id}")
}
}
}
}
sparkSession.sql(
"""
|SELECT vb.*, b.*, s1.*, s2.*
|FROM very_big_table AS vb
|JOIN big_table AS b ON vb.very_big_table_id = b.big_table_id
|JOIN small_table1 AS s1 ON vb.very_big_table_id = s1.small_table1_id
|JOIN small_table2 AS s2 ON s1.small_table1_id = s2.small_table2_id
|JOIN small_table3 AS s3 ON s2.small_table2_id = s3.small_table3_id
""".stripMargin).explain(true)
As you can see, the query has one star join between (vb - b - s1) and on non-star join between (s2 - s3). Its execution plan was reordered to keep all star joins in a single place and all non-star joins in another branch. The query transformation from its analyzed to optimized version looks like:
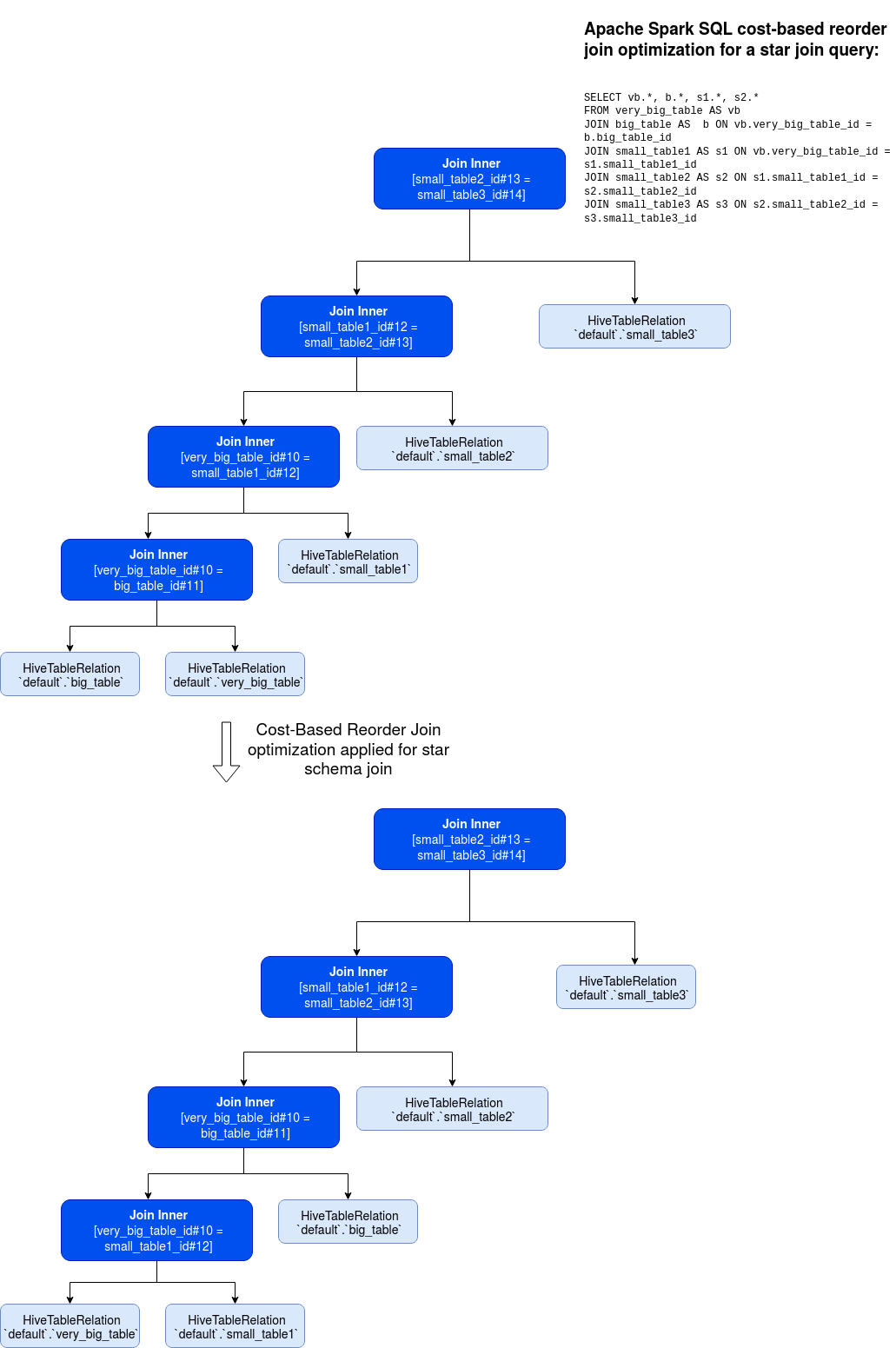
Regarding our star schema optimization, please check this short video:
Star schema detection is included in the reorder join optimization. Its implementation uses statistics to figure out the biggest tables involved in the query. After sorting the tables, it finds the fact and dimension tables and the tables not being part of the star schema and passes all of that to the reorder join algorithm. The algorithm uses the dynamic programming algorithm covered last week in Reorder JOIN optimizer - cost-based optimization to reorder joins in the optimized plan. It will also apply to the not CBO-based reorder but it will be used only when the statistics are computed for every eligible table.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Reorder JOIN optimizer - star schema here:
- Join reordering using star schema detection TPC-DS performance improvements using star-schema heuristics
Related blog posts:
- Reorder JOIN optimizer - cost-based optimization
- Reorder JOIN optimizer
- Spark SQL Cost-Based Optimizer
- Spark SQL operator optimizations - part 1
- Predicate pushdown in Spark SQL
The final part of my #ApacheSpark #SparkSQL series about join reorders is online. This time, it's about star schema optimization ? https://t.co/y4yq67n69Y
— Bartosz Konieczny (@waitingforcode) February 29, 2020