
One of the reasons why I like my blogging activity is that from time to time the exchange is bidirectional. It happens mostly on Github but also on the comments under the post and I appreciate the situation when I don't know the answer and must dig a little to explain it in a blog post :) I wrote this one thanks to bithw1 issue created on my Spark playground repository (thank you for another interesting question btw :)).
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
In the post I wrote 3 years ago about Spark SQL operator optimizations - part 2, I briefly mentioned the existence of reorder join optimization. In this and next week's article, I will extend this short information. Here I'll focus only on the fact of transforming a query involving columns equity from different datasets into join. In the next one, that I'll probably publish next week, I'll focus on the cost-based optimization in reordering joins.
Reordering joins - the logical
Reorder join is a logical plan optimization rule. It's triggered to convert an unordered join, ie. a JOIN expressed with a SELECT...WHERE clause from multiple tables or an explicit JOIN with WHERE clause instead of the ON one. It can work with 2 different strategies. The first one can be called logical since the optimizer only transforms the initial query into a query based on JOIN...ON operations. The second strategy estimates cost for every possible join and chooses the cheapest one. In this article, I will cover only the first one.
Before deepening delve into the execution details, let's see first how the logical reordering works, without the cost-based optimization. The first of optimizable queries is a JOIN-SELECT of 3 temporary tables:
it should "apply to 3 tables joined from a SELECT clause" in {
val logAppender = InMemoryLogAppender.createLogAppender(
Seq("Applying Rule org.apache.spark.sql.catalyst.optimizer.ReorderJoin"))
val users = (0 to 100).map(nr => (nr, s"user#${nr}")).toDF("id", "login")
users.createTempView("users_list")
val actions = (0 to 100).flatMap(userId => {
(0 to 100).map(actionNr => (userId, s"action${actionNr}"))
}).toDF("action_user", "action_name")
actions.createTempView("users_actions")
val usersLogged = (0 to 100 by 2).map(nr => (nr, System.currentTimeMillis())).toDF("logged_user", "last_login")
usersLogged.createTempView("users_logged")
sparkSession.sql(
"""
|SELECT ul.*, ua.*, ulo.*
|FROM users_list AS ul, users_actions AS ua, users_logged AS ulo
|WHERE ul.id = ua.action_user AND ulo.logged_user = ul.id
""".stripMargin).explain(true)
logAppender.getMessagesText() should have size 1
logAppender.getMessagesText()(0).trim should startWith("=== Applying Rule org.apache.spark.sql.catalyst.optimizer.ReorderJoin ===")
}
As you can see from the assertion, the plan was correctly transformed. And to be even more precise, it was transformed from a JOIN without ON clause into 2 JOINs with an ON clause:
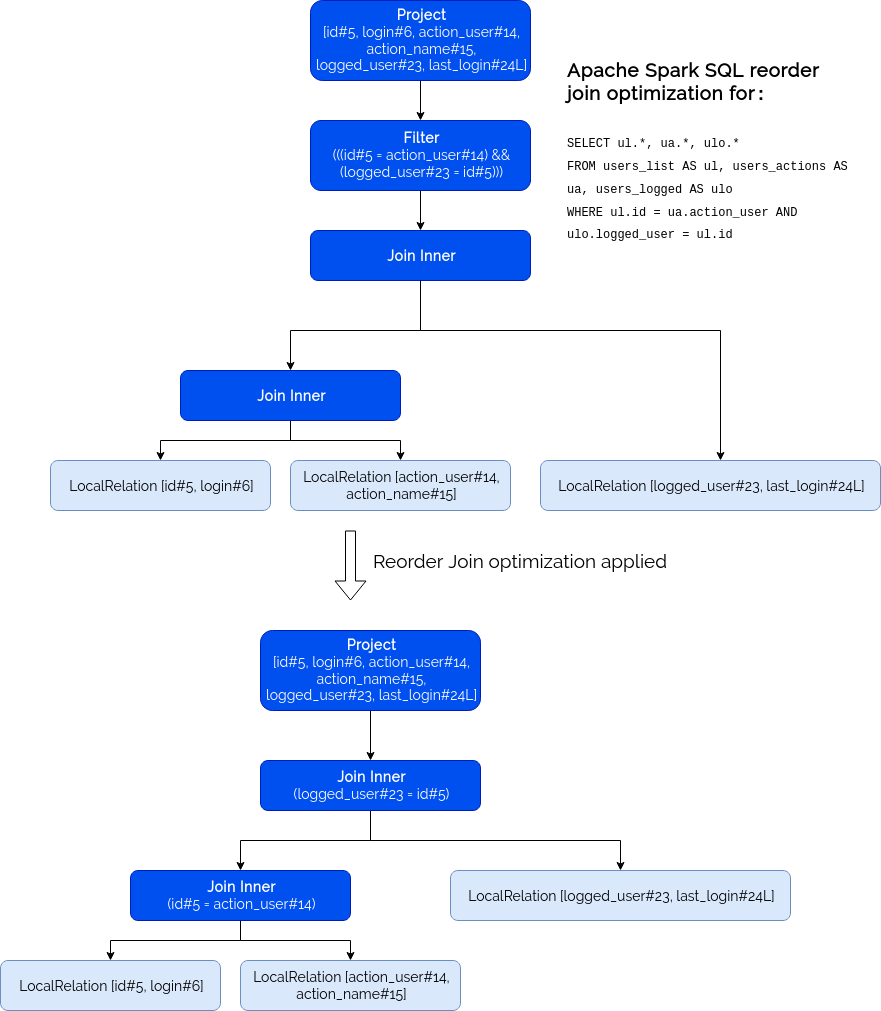
The second query using reorder join is a JOIN with WHERE clause instead of the ON one:
it should "apply to 2 tables joined with a WHERE clause" in {
val logAppender = InMemoryLogAppender.createLogAppender(
Seq("Applying Rule org.apache.spark.sql.catalyst.optimizer.ReorderJoin"))
val users = (0 to 100).map(nr => (nr, s"user#${nr}")).toDF("id", "login")
users.createTempView("users_list")
val actions = (0 to 100).flatMap(userId => {
(0 to 100).map(actionNr => (userId, s"action${actionNr}"))
}).toDF("action_user", "action_name")
actions.createTempView("users_actions")
val usersLogged = (0 to 100 by 2).map(nr => (nr, System.currentTimeMillis())).toDF("logged_user", "last_login")
usersLogged.createTempView("users_logged")
sparkSession.sql(
"""
|SELECT ul.*, ua.*, ulo.*
|FROM users_list AS ul JOIN users_actions AS ua JOIN users_logged AS ulo
|WHERE ul.id = ua.action_user AND ulo.logged_user = ul.id
""".stripMargin).explain(true)
logAppender.getMessagesText() should have size 1
logAppender.getMessagesText()(0).trim should startWith("=== Applying Rule org.apache.spark.sql.catalyst.optimizer.ReorderJoin ===")
}
Since its query plan transformation is the same as for the above use case, I will omit the illustration to save some space for other details :) Just before closing this part, let's see if the reorder join doesn't apply for 2 tables:
it should "not apply to 2 tables joined with a WHERE clause" in {
val logAppender = InMemoryLogAppender.createLogAppender(
Seq("Applying Rule org.apache.spark.sql.catalyst.optimizer.ReorderJoin"))
val users = (0 to 100).map(nr => (nr, s"user#${nr}")).toDF("id", "login")
users.createTempView("users_list")
val actions = (0 to 100).flatMap(userId => {
(0 to 100).map(actionNr => (userId, s"action${actionNr}"))
}).toDF("action_user", "action_name")
actions.createTempView("users_actions")
sparkSession.sql(
"""
|SELECT ul.*, ua.*
|FROM users_list AS ul JOIN users_actions AS ua
|WHERE ul.id = ua.action_user
""".stripMargin).explain(true)
logAppender.getMessagesText() shouldBe empty
}e
As you can see, this time the log messages captured during the query execution are empty. The reason why it happens is defined in the optimization logic which applies to at least 3 joined tables:
object ReorderJoin extends Rule[LogicalPlan] with PredicateHelper {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
case ExtractFiltersAndInnerJoins(input, conditions)
if input.size > 2 && conditions.nonEmpty =>
ReorderJoin operator
Under-the-hood, reordering operation is performed by org.apache.spark.sql.catalyst.optimizer.ReorderJoin logical optimization rule. The operator starts by extracting all tables and filters involved in the query, to 2 separate objects. Later, it calls its internal createOrderedJoin(input: Seq[(LogicalPlan, InnerLike)], conditions: Seq[Expression]) that recursively transforms multiple joined datasets into a LogicalPlan composed of JOIN operations with ON clauses.
The method responsible for extracting tables and conditions is flattenJoin from ExtractFiltersAndInnerJoins extractor (learn more about Scala extractors). It works by recursively applying this pattern matching on the initial logical plan:
case Join(left, right, joinType: InnerLike, cond) =>
val (plans, conditions) = flattenJoin(left, joinType)
(plans ++ Seq((right, joinType)), conditions ++
cond.toSeq.flatMap(splitConjunctivePredicates))
case Filter(filterCondition, j @ Join(left, right, _: InnerLike, joinCondition)) =>
val (plans, conditions) = flattenJoin(j)
(plans, conditions ++ splitConjunctivePredicates(filterCondition))
case _ => (Seq((plan, parentJoinType)), Seq.empty)
As you can see, the idea here is to separate plans from conditions. For example, in the case of that plan:
Filter ((id#5 = action_user#14) && (logged_user#23 = id#5)) +- Join Inner :- Join Inner : :- LocalRelation [id#5, login#6] : +- LocalRelation [action_user#14, action_name#15] +- LocalRelation [logged_user#23, last_login#24L]
This method will generate:
- (LocalRelation [action_user#14, action_name#15], Inner), (LocalRelation [id#5, login#6], Inner) and (LocalRelation [logged_user#23, last_login#24L], Inner) as the plans, where Inner is the join type from the initial query
- (id#5 = action_user#14) (logged_user#23 = id#5) as the conditions
After that, the optimizer rewrites the initial query. It does it by recursively calling createOrderedJoin, as long as there are at least 2 logical operators to merge. The method starts with the leftmost operator (LocalRelation [action_user#14, action_name#15] in our case). Inside this method, it starts by looking for plans that can be joined with the current operator. Once it finds the match, it builds a Join node composed of both nodes and starts another recursion with remaining elements:
val (right, innerJoinType) = conditionalJoin.getOrElse(rest.head)
val joinedRefs = left.outputSet ++ right.outputSet
val (joinConditions, others) = conditions.partition(
e => e.references.subsetOf(joinedRefs) && canEvaluateWithinJoin(e))
val joined = Join(left, right, innerJoinType, joinConditions.reduceLeftOption(And))
// should not have reference to same logical plan
createOrderedJoin(Seq((joined, Inner)) ++ rest.filterNot(_._1 eq right), others)
When the number of elements is equal to 2, it means that the recursion can stop by creating the final Join node in the plan. The plan created at this moment should be a Join(remaining node, joins computed previously), except in one situation. The exception happens when not all remaining conditions are used in the final join. In such a case, the optimized plan will be composed of a Filter(filter expression, last join), like in the following example:
it should "leave a predicate that cannot be pushed into ON clause as a separate filter" in {
val logAppender = InMemoryLogAppender.createLogAppender(
Seq("Applying Rule org.apache.spark.sql.catalyst.optimizer.ReorderJoin"))
val users = (0 to 100).map(nr => (nr, s"user#${nr}")).toDF("id", "login")
users.createTempView("users_list")
val actions = (0 to 100).flatMap(userId => {
(0 to 100).map(actionNr => (userId, s"action${actionNr}"))
}).toDF("action_user", "action_name")
actions.createTempView("users_actions")
val usersLogged = (0 to 100 by 2).map(nr => (nr, System.currentTimeMillis())).toDF("logged_user", "last_login")
usersLogged.createTempView("users_logged")
(0 to 100).toDF("number").createTempView("xyz")
sparkSession.sql(
"""
|SELECT ul.*, ua.*, ulo.*
|FROM users_list AS ul, users_actions AS ua, users_logged AS ulo
|WHERE ul.id = ua.action_user AND ulo.logged_user = ul.id AND ul.id IN (SELECT number FROM xyz)
""".stripMargin).explain(true)
logAppender.getMessagesText() should have size 1
logAppender.getMessagesText()(0).trim should include("+- Filter id#5 IN (list#32 [])")
}
The reordered query for that case, which later fallback into a semi-left join, looks like:
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.ReorderJoin ===
Project [id#5, login#6, action_user#14, action_name#15, logged_user#23, last_login#24L] Project [id#5, login#6, action_user#14, action_name#15, logged_user#23, last_login#24L]
!+- Filter (((id#5 = action_user#14) && (logged_user#23 = id#5)) && id#5 IN (list#32 [])) +- Filter id#5 IN (list#32 [])
: +- LocalRelation [number#30] : +- LocalRelation [number#30]
! +- Join Inner +- Join Inner, (logged_user#23 = id#5)
! :- Join Inner :- Join Inner, (id#5 = action_user#14)
: :- LocalRelation [id#5, login#6] : :- LocalRelation [id#5, login#6]
: +- LocalRelation [action_user#14, action_name#15] : +- LocalRelation [action_user#14, action_name#15]
+- LocalRelation [logged_user#23, last_login#24L] +- LocalRelation [logged_user#23, last_login#24L]
(org.apache.spark.sql.internal.BaseSessionStateBuilder$$anon$2:62)
The remaining filter conditions are the ones which cannot be evaluated inside the ON clause of the final JOIN and it's resolved in PredicateHelper#canEvaluateWithinJoin an IN operation:
protected def canEvaluateWithinJoin(expr: Expression): Boolean = expr match {
// Non-deterministic expressions are not allowed as join conditions.
case e if !e.deterministic => false
case _: ListQuery | _: Exists =>
// A ListQuery defines the query which we want to search in an IN subquery expression.
// Currently the only way to evaluate an IN subquery is to convert it to a
// LeftSemi/LeftAnti/ExistenceJoin by `RewritePredicateSubquery` rule.
// It cannot be evaluated as part of a Join operator.
// An Exists shouldn't be push into a Join operator too.
false
case e: SubqueryExpression =>
// non-correlated subquery will be replaced as literal
e.children.isEmpty
case a: AttributeReference => true
case e: Unevaluable => false
case e => e.children.forall(canEvaluateWithinJoin)
}
Reorder join limitation
The optimization applies on the INNER JOINs, as illustrated in the blog post. Reordering OUTER JOINs is very dangerous because it can produce unexpected results. You can learn more about it in Tagar's answer
That's the simplest version of join reorder in Apache Spark. In the next 2 follow-up posts you'll see that there are also a little bit more complicated optimizations based on star schema and query cost estimations.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- Reorder JOIN optimizer - star schema
- Reorder JOIN optimizer - cost-based optimization
- Spark SQL Cost-Based Optimizer
- Spark SQL operator optimizations - part 1
- Predicate pushdown in Spark SQL
To start this new week I've begun the series about join reorders in #ApacheSpark #SparkSQL. The first blog post covers "logical" (query reorganization) aspect of this feature https://t.co/NF8aJA0fsC
— Bartosz Konieczny (@waitingforcode) February 15, 2020