
That's probably one of the most common questions you may have heard in preliminary job interviews. What's the difference between coalesce and repartition? Many answers exist, but instead of repeating them, I will try to dig a bit deeper in this blog post and see how the coalesce works.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Coalesce - plan resolution
When you call coalesce method, Apache Spark adds a logical node called Repartition(numPartitions: Int, shuffle: Boolean, child: LogicalPlan) to the logical plan with the shuffle attribute set to false. It means that whatever value you put as the numPartitions, the physical planner will not shuffle the data:
def coalesce(numPartitions: Int): Dataset[T] = withTypedPlan {
Repartition(numPartitions, shuffle = false, logicalPlan)
}
Starting from this point, the engine knows that the partitions distribution has to change and depending on the shuffle flag, it transforms the Repartition logical node into ShuffleExchangeExec (when shuffle is true) or CoalesceExec otherwise:
case logical.Repartition(numPartitions, shuffle, child) =>
if (shuffle) {
ShuffleExchangeExec(RoundRobinPartitioning(numPartitions),
planLater(child), noUserSpecifiedNumPartition = false) :: Nil
} else {
execution.CoalesceExec(numPartitions, planLater(child)) :: Nil
}
Coalsce will then delegate the execution to the CoalesceExec which, depending on the number of partitions, will either return an empty RDD or delegate the execution to RDD's coalesce function. Since the former case will happen only when the child node has 1 or less (!) partitions, so it's something quite rare, let's focus on RDD's coalesce part:
protected override def doExecute(): RDD[InternalRow] = {
if (numPartitions == 1 && child.execute().getNumPartitions < 1) {
// Make sure we don't output an RDD with 0 partitions, when claiming that we have a
// `SinglePartition`.
new CoalesceExec.EmptyRDDWithPartitions(sparkContext, numPartitions)
} else {
child.execute().coalesce(numPartitions, shuffle = false)
}
}
RDD's coalesce
The call to coalesce will create a new CoalescedRDD(this, numPartitions, partitionCoalescer) where the last parameter will be empty. It means that at the execution time, this RDD will use the default org.apache.spark.rdd.DefaultPartitionCoalescer. While analyzing the code, you will see that the coalesce operation consists on merging various partitions:
private[spark] class CoalescedRDD[T: ClassTag](
@transient var prev: RDD[T],
maxPartitions: Int,
partitionCoalescer: Option[PartitionCoalescer] = None)
extends RDD[T](prev.context, Nil) {
override def getPartitions: Array[Partition] = {
val pc = partitionCoalescer.getOrElse(new DefaultPartitionCoalescer())
pc.coalesce(maxPartitions, prev).zipWithIndex.map {
case (pg, i) =>
val ids = pg.partitions.map(_.index).toArray
CoalescedRDDPartition(i, prev, ids, pg.prefLoc)
}
}
The coalesce magic is hidden behind the pc variable which returns the array containing all merged partitions transformed at the end to the CoalescedRDDPartition instances. It's quite simple, isn't it? Apparently, yes! But the coalesce algorithm provided by the used DefaultPartitionCoalescer class is a bit more complex than that.
Coalesce algorithm
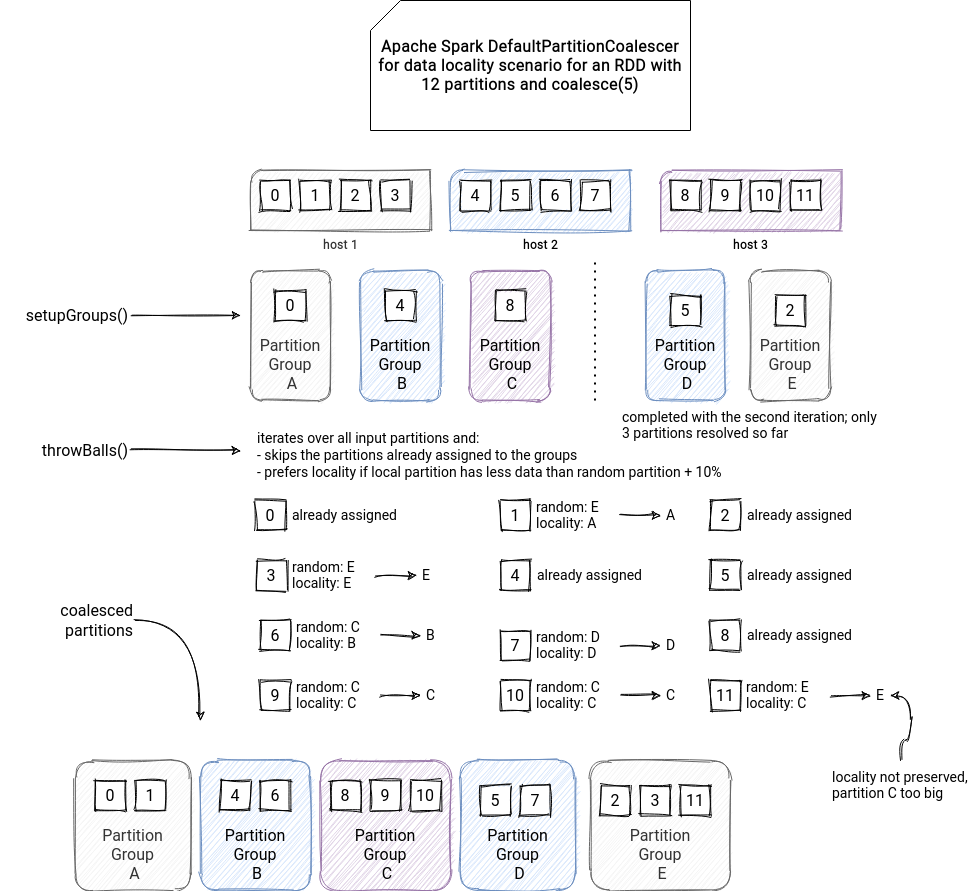
It's complicated because the algorithm includes the data locality concept, i.e., whether a specific partition is associated with a particular executor or not. We could then think that all partitions located on the node will be put to the same coalesced partition, but it's not true.
Let's try to understand why by analyzing the algorithm. It starts by generating a list composed of executor, partition pairs (partsWithLocs in the snippet). If the data locality information is missing for all or some of the partitions, the algorithm will generate a simple list of not locality-aware partitions (partsWithoutLocs in the snippet):
def getAllPrefLocs(prev: RDD[_]): Unit = {
val tmpPartsWithLocs = mutable.LinkedHashMap[Partition, Seq[String]]()
// first get the locations for each partition, only do this once since it can be expensive
prev.partitions.foreach(p => {
val locs = currPrefLocs(p, prev)
if (locs.nonEmpty) {
tmpPartsWithLocs.put(p, locs)
} else {
partsWithoutLocs += p
}
}
)
// convert it into an array of host to partition
for (x <- 0 to 2) {
tmpPartsWithLocs.foreach { parts =>
val p = parts._1
val locs = parts._2
if (locs.size > x) partsWithLocs += ((locs(x), p))
}
}
}
}
After this step, the coalescer creates PartitionGroups composed of the preferred location and the list of stored partitions. Of course, If the data locality information is missing, the PartitionGroups are empty objects, like in the snippet below:
def setupGroups(targetLen: Int, partitionLocs: PartitionLocations): Unit = {
// deal with empty case, just create targetLen partition groups with no preferred location
if (partitionLocs.partsWithLocs.isEmpty) {
(1 to targetLen).foreach(_ => groupArr += new PartitionGroup())
return
}
// ...
An interesting thing to notice here is that not all input partitions are put to the PartitionGroups! The coalescer stops when the number of processed input partitions is equal to the new number of partitions. So, after this step, we have a partial list of PartitionGroup objects referencing executor nodes and some of the associated input partitions.
The next step is the final coalesce, where the coalescer merges input partitions. The coalescer iterates over all input partitions and associates each of them to one of the previously initialized PartitionGroups. The association logic is as follows:
- no preferred locations - get randomly 2 PartitionGroups and assign the partition to the group with fewer partitions (= no data locality)
- preferred locations defined - if there is a data locality involved, the coalescer can ignore this aspect if the local partition is imbalanced (= bigger than the random PartitionGroup + 10%). In that case, the partition goes to the smaller (randomly chosen) group. Otherwise, it goes to the preferred location.
if (prefPart.isEmpty) { // if no preferred locations, just use basic power of two return minPowerOfTwo } val prefPartActual = prefPart.get // more imbalance than the slack allows if (minPowerOfTwo.numPartitions + slack <= prefPartActual.numPartitions) { minPowerOfTwo // prefer balance over locality } else { prefPartActual // prefer locality over balance }
As you can see then, the data locality aspect may be ignored! Even "worse", if all the input partitions don't have it, the algorithm does a simple even split like in the snippet below:
if (noLocality) { // no preferredLocations in parent RDD, no randomization needed
if (maxPartitions > groupArr.size) { // just return prev.partitions
for ((p, i) <- prev.partitions.zipWithIndex) {
groupArr(i).partitions += p
}
} else { // no locality available, then simply split partitions based on positions in array
for (i <- 0 until maxPartitions) {
val rangeStart = ((i.toLong * prev.partitions.length) / maxPartitions).toInt
val rangeEnd = (((i.toLong + 1) * prev.partitions.length) / maxPartitions).toInt
(rangeStart until rangeEnd).foreach{ j => groupArr(i).partitions += prev.partitions(j) }
}
}
}
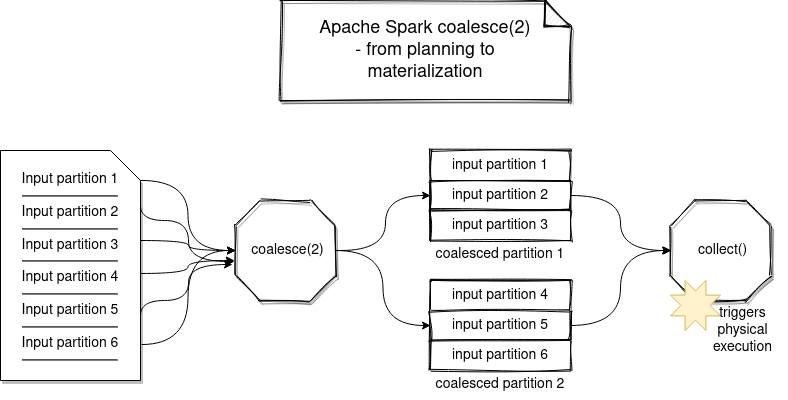
The following schemas summarize the workflow of both operations:
Metadata operation
When I first analyzed the default coalesce algorithm, I thought that the shuffle will still happen if the data locality is not preserved nor defined. However, if you verify the implementation of CoalesceRDD's compute method, you will see that not necessarily. In fact, the coalesce operation is a metadata operation; i.e. Apache Spark simply groups multiple partitions together and delegates the physical execution to the parent's input partitions from the group:
private[spark] class CoalescedRDD[T: ClassTag](
@transient var prev: RDD[T],
maxPartitions: Int,
partitionCoalescer: Option[PartitionCoalescer] = None)
extends RDD[T](prev.context, Nil) { // Nil since we implement getDependencies
// ...
override def compute(partition: Partition, context: TaskContext): Iterator[T] = {
partition.asInstanceOf[CoalescedRDDPartition].parents.iterator.flatMap { parentPartition =>
firstParent[T].iterator(parentPartition, context)
}
}
So technically there is no shuffle; i.e. no extra stage is added to the plan. It's even more visible if you analyze CoalescedRDD more in detail, you will see that it returns a NarrowDepepdency for all its parent partitions:
/**
* :: DeveloperApi ::
* Base class for dependencies where each partition of the child RDD depends on a small number
* of partitions of the parent RDD. Narrow dependencies allow for pipelined execution.
*/
@DeveloperApi
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
// ...
}
private[spark] class CoalescedRDD[T: ClassTag](
@transient var prev: RDD[T],
maxPartitions: Int,
partitionCoalescer: Option[PartitionCoalescer] = None)
extends RDD[T](prev.context, Nil) { // Nil since we implement getDependencies
override def getDependencies: Seq[Dependency[_]] = {
Seq(new NarrowDependency(prev) {
def getParents(id: Int): Seq[Int] =
partitions(id).asInstanceOf[CoalescedRDDPartition].parentsIndices
})
}
// ...
Remember, Apache Spark evaluates lazily, so if you are reading a JSON file and do a coalesce just after, it simply means that one Coalesce partition may read the chunks initially reserved to different input partitions! A little bit as in the image below:
However, what happens if the underlying RDD has the data locality concept? Nothing different! If you verify, for example, the HadoopRDD, you will notice that the compute method always downloads the file. The difference is that this operation can involve data network transfer if the locality is not preserved but technically speaking, it's still not a shuffle operation.
And what if the partition was cached in another executor node? If you analyze the RDD's getOrCompute(partition: Partition, context: TaskContext) method, you will see that it will first try to load the cached data locally and if it's missing, remotely:
private[spark] class BlockManager( // ...
def get[T: ClassTag](blockId: BlockId): Option[BlockResult] = {
val local = getLocalValues(blockId)
if (local.isDefined) {
logInfo(s"Found block $blockId locally")
return local
}
val remote = getRemoteValues[T](blockId)
if (remote.isDefined) {
logInfo(s"Found block $blockId remotely")
return remote
}
None
}
To summarize this quite long blog post, we can classify the coalesce operation like a metadata transformation merging multiple input partitions without involving shuffle. It's then the opposite for repartition that I will explain in the next article.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
You certainly know the difference between coalesce and repartition in #ApacheSpark #SparkSQL. But do you know how it prevents shuffling? If not, maybe the new blog post can help ? https://t.co/X0pjpxpkJ5
— Bartosz Konieczny (@waitingforcode) March 6, 2021