
Joins are probably the most popular operation for combining datasets and Apache Spark supports multiple types of them already! In the new release, the framework got 2 new strategies, the storage-partitioned and row-level runtime filters.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Storage-partitioned join
At first glance, the storage-partitioned join might look like the local bucket-based join. However, both have different implementations. The bucket-based join strategy generates the partition number using the division modulo method and requires the number of buckets to be the same on both datasets. On the other hand, the storage-partitioned join strategy relies on the storage layout and expects the datasets to expose this partitioning information.
How? To start, Chao Sun who is the author of the feature, added a new DataSource V2 interface called HasPartitionKey. The data sources supporting the storage-partitioned join should implement it alongside the already existing SupportsReportPartitioning interface to inform Apache Spark about the required data distribution and ordering. The new interafe returns the partition key(s):
public interface HasPartitionKey extends InputPartition {
InternalRow partitionKey();
}
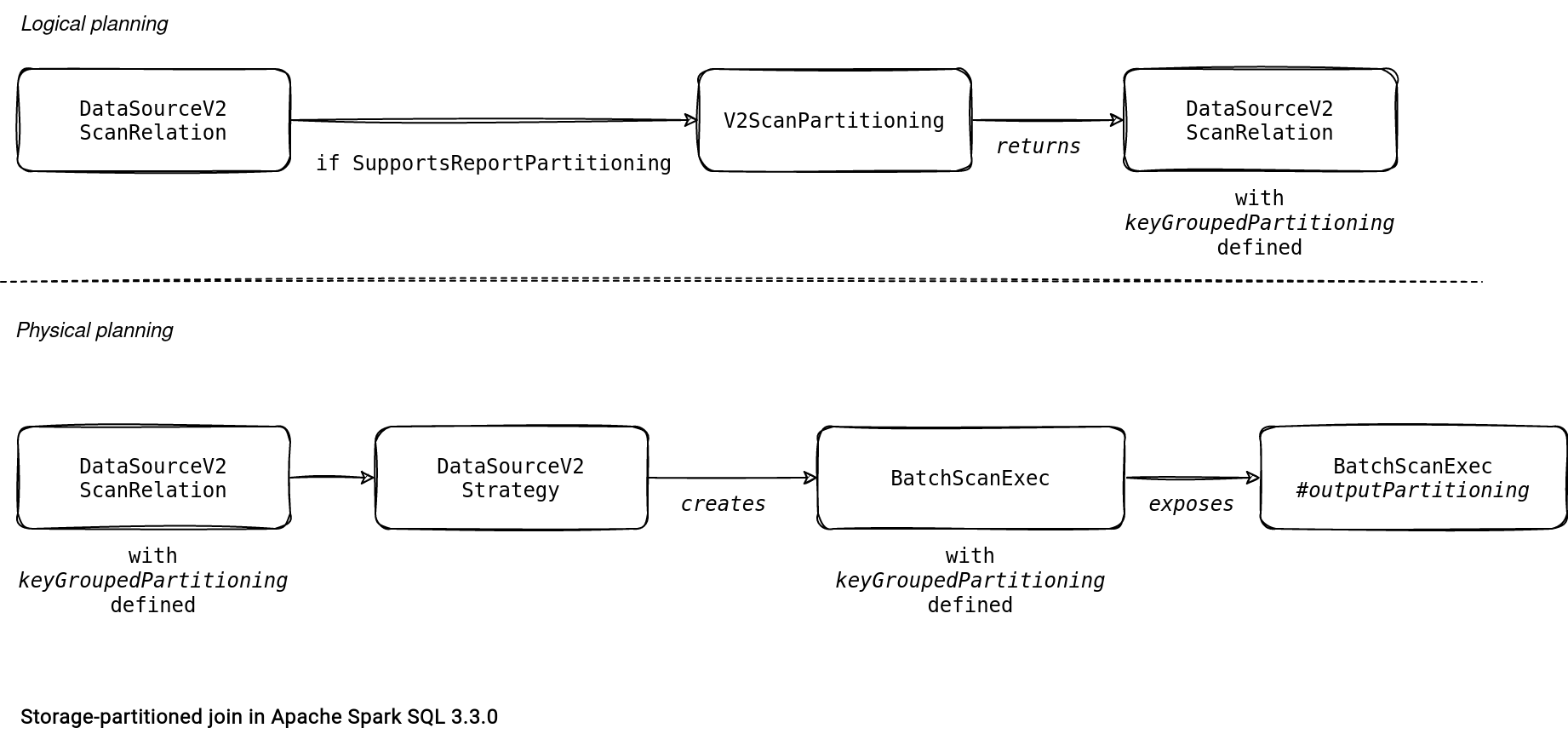
Logical planner uses this partition key information later to enrich the basic DataSourceV2Relation from a new logical rule called V2ScanPartitioning. The partitioning expression goes to the physical planning as the keyGroupedPartitioning attribute of the DataSourceV2Relation.
The physical planner gets this information to build a BatchScanExec that exposes the partitioning as an instance of KeyGroupedPartitioning from outputPartitioning method.
Later, the planner verifies the datasets distribution. To take advantage of the local join without shuffle, a new method from the EnsureRequirements verifies its feasibility. As you can see in the snippet below, it compares the dataset with the required distribution:
case class EnsureRequirements(optimizeOutRepartition: Boolean = true,
requiredDistribution: Option[Distribution] = None) extends Rule[SparkPlan] {
// ...
private def checkKeyGroupedSpec(shuffleSpec: ShuffleSpec): Boolean = {
def check(spec: KeyGroupedShuffleSpec): Boolean = {
val attributes = spec.partitioning.expressions.flatMap(_.collectLeaves())
val clustering = spec.distribution.clustering
if (SQLConf.get.getConf(SQLConf.REQUIRE_ALL_CLUSTER_KEYS_FOR_CO_PARTITION)) {
attributes.length == clustering.length && attributes.zip(clustering).forall {
case (l, r) => l.semanticEquals(r)
}
} else {
true // already validated in `KeyGroupedPartitioning.satisfies`
}
}
shuffleSpec match {
case spec: KeyGroupedShuffleSpec => check(spec)
case ShuffleSpecCollection(specs) => specs.exists(checkKeyGroupedSpec)
case _ => false
}
}
When the method above returns true, the execution plan remains unchanged and doesn't contain the shuffle:
case class EnsureRequirements(
// ...
private def ensureDistributionAndOrdering(
// ...
val allCompatible = childrenIndexes.sliding(2).forall {
case Seq(a, b) =>
checkKeyGroupedSpec(specs(a)) && checkKeyGroupedSpec(specs(b)) &&
specs(a).isCompatibleWith(specs(b))
}
children = children.zip(requiredChildDistributions).zipWithIndex.map {
case ((child, _), idx) if allCompatible || !childrenIndexes.contains(idx) =>
child
// ...
One important point to keep in mind about this storage-partitioned join is that it's not implemented in the data sources yet but you can find an example below. It's a fragment of the InMemoryBatchScan test class of the Apache Spark project:
case class InMemoryBatchScan(
var data: Seq[InputPartition],
readSchema: StructType,
tableSchema: StructType)
extends Scan with Batch with SupportsRuntimeFiltering with SupportsReportStatistics
with SupportsReportPartitioning {
override def outputPartitioning(): Partitioning = {
InMemoryTable.this.distribution match {
case cd: ClusteredDistribution => new KeyGroupedPartitioning(cd.clustering(), data.size)
case _ => new UnknownPartitioning(data.size)
}
}
override def planInputPartitions(): Array[InputPartition] = data.toArray
Row-level runtime filters
The second join types, this time added by Abhishek Somani, is row-level runtime filters enabled with spark.sql.optimizer.runtime.bloomFilter.enabled and spark.sql.optimizer.runtimeFilter.semiJoinReduction.enabled properties. Why these 2? Because they introduce different optimizations.
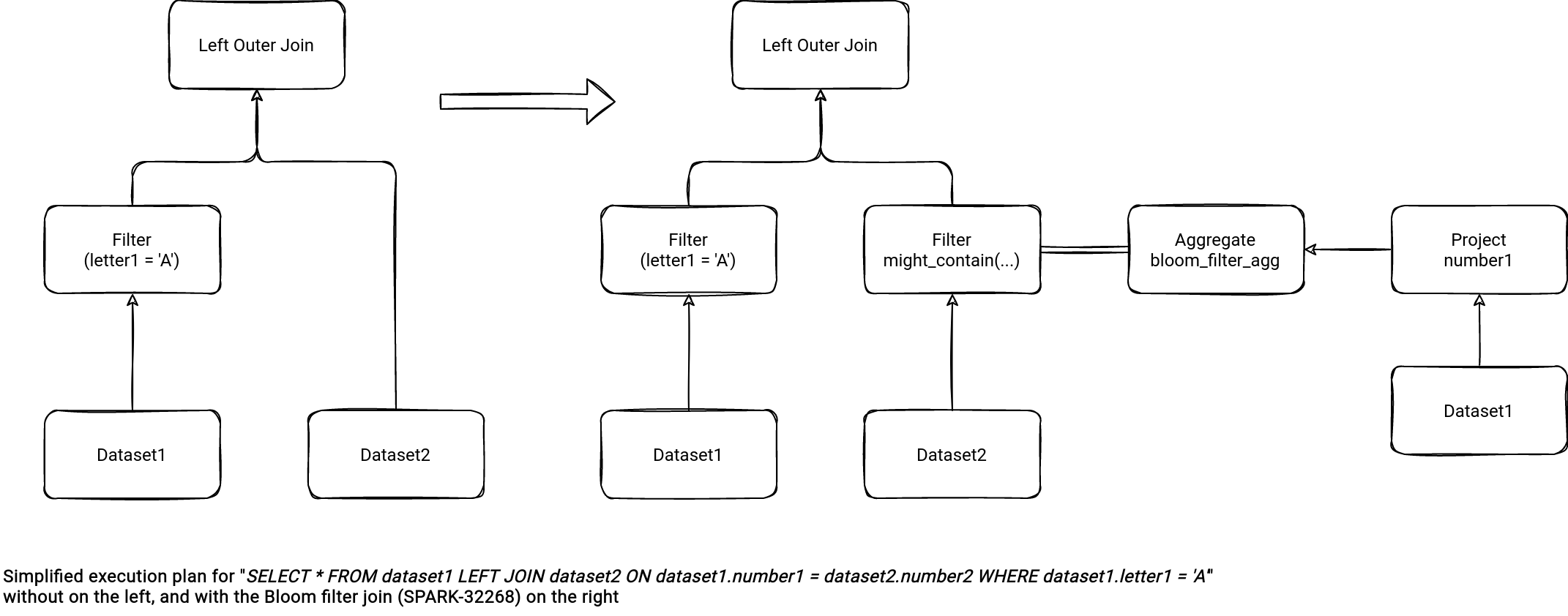
The bloomFilter.enabled is responsible for the Bloom filter aggregate transforming a join to an aggregate-based join, as in the schema below for the left outer join:
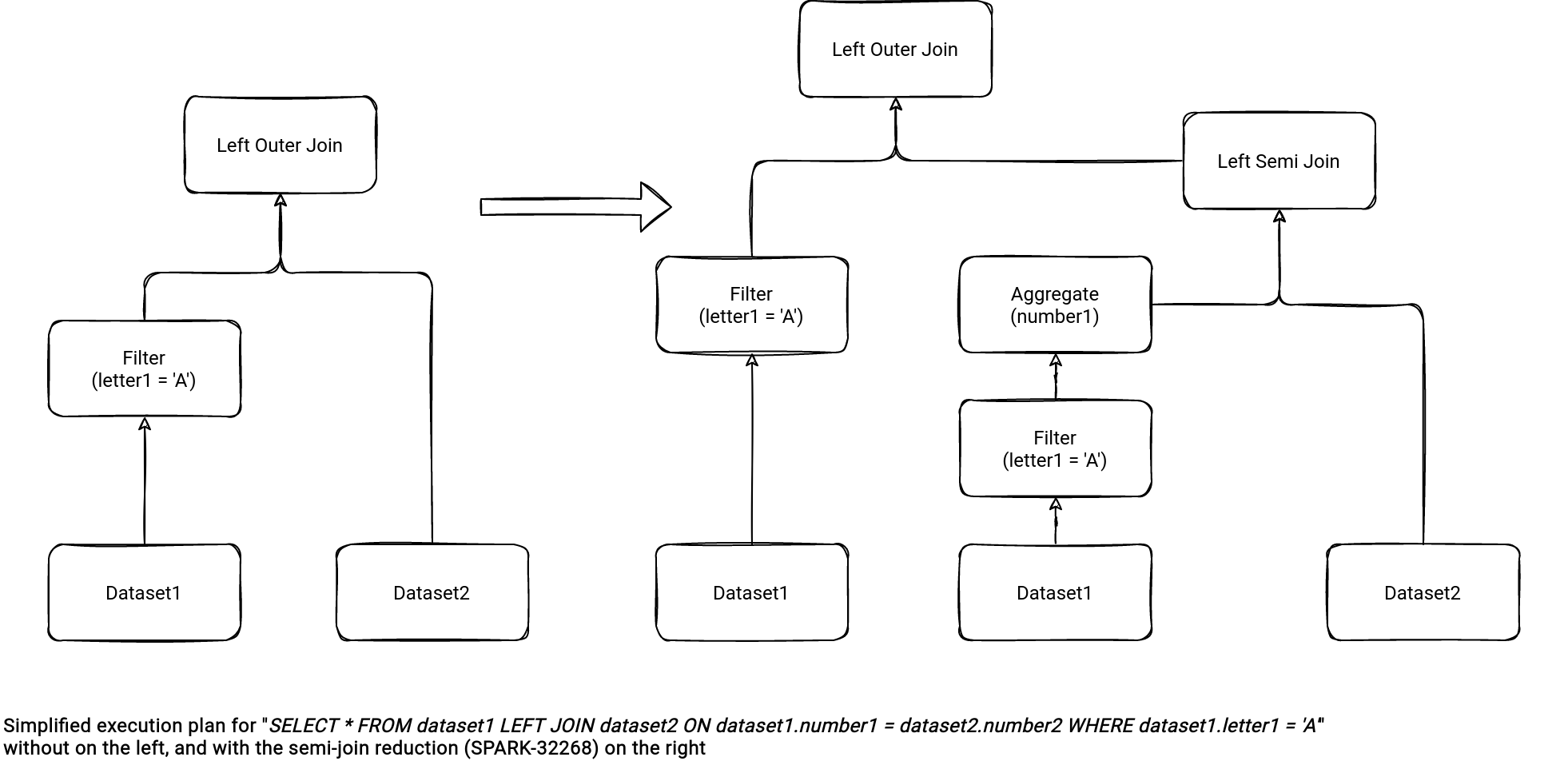
When it comes to the semiJoinReduction.enabled, it transforms the join to a semi-join with a subquery, as in the illustration below for the left outer join:
You certainly notice the duplicated filtering. As per the design doc, it's a recognized but accepted drawback of the approach:
Cons.:
- Redundant computation
- Possibly run the build side scan and filter twice, one for the join and the other for the Bloom filter creation. But we argue this is currently protected by (a) only creating Bloom filters for small inputs, and can be improved by (b) optimizations to dedup plan subtrees.
InjectRuntimeFilter logical rule
The row-level runtime filters brings a new logical rule called InjectRuntimeFilter that might transform the join if all of the following conditions are met:
- The number of already injected filters is lower than the number defined in the spark.sql.optimizer.runtimeFilter.number.threshold property (10 by default). The reason for limiting them is avoiding the OOM problems.
- The Dynamic Partition Pruning is not present in the logical plan optimized so far.
- Neither the Bloom filter nor semi-join filter is present on the left or right side keys of the join.
- The left and right side join keys are simple expressions, so a not expensive compute operation matching this pattern: !e.containsAnyPattern(PYTHON_UDF, SCALA_UDF, INVOKE, JSON_TO_STRUCT, LIKE_FAMLIY, REGEXP_EXTRACT_FAMILY, REGEXP_REPLACE). limiting them is avoiding the OOM problems
When all these conditions are true, the logical rule enters the next stage to detect the join side to apply the runtime filter on. It starts with the left side and evaluates to true if the join type isInner | LeftSemi | RightOuter and adding the runtime filter is beneficial for the query (I'm going to focus on it further). If both are not true, the rule checks the right side and also evaluates the join type (if Inner | LeftSemi | LeftOuter) and the transformation impact on the query. If this time too, both don't return true, the join remain unchanged. Otherwise, one side of the join gets transformed.
Before going to this transformation step, let's focus on this "beneficial impact" I mentioned before. The transformation is considered beneficial for the query if:
- If the input of the filter application side originates from a single leaf node. A filter application side is the join side that will use the runtime filter.
- The filtering expression for the filter creation side has a selective predicate, such as "=", "<=", "IN", ... The full list is available in the PredicateHelper#isLikelySelective method.
- The current join tree is a shuffle join or a broadcast join with a shuffle join below it.
- The size of the filter application side is bigger than spark.sql.optimizer.runtime.bloomFilter.applicationSideScanSizeThreshold (10GB by default).
The filter injection depends on the enabled option. That's why I'll detail it in the next sections.
Bloom filter
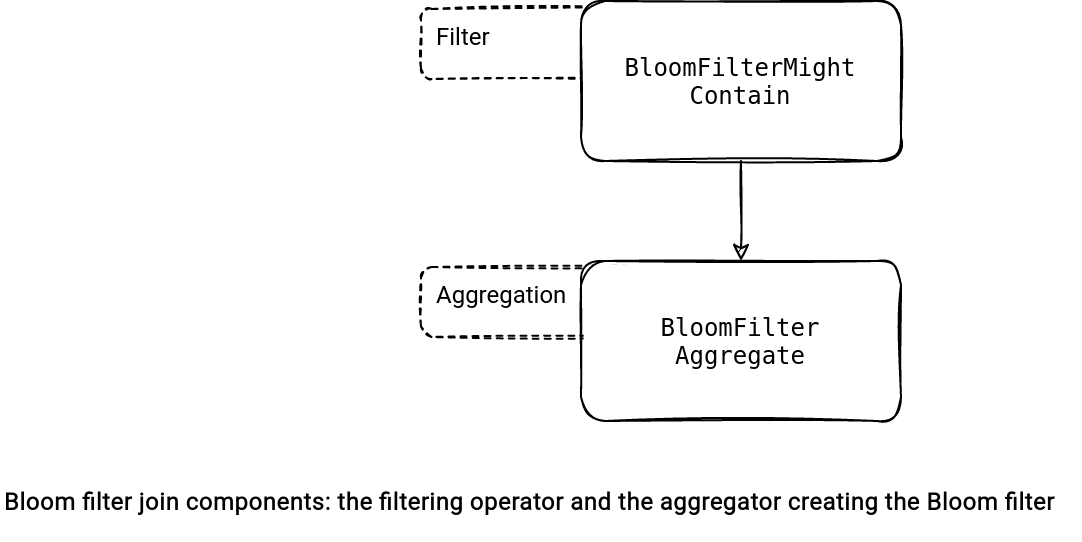
For the Bloom filter enabled, the rule adds a BloomFilterAggregate node. The aggregation leverages the spark-sketch library to create a Bloom filter. The filter will contain at most spark.sql.optimizer.runtime.bloomFilter.maxNumItems items and spark.sql.optimizer.runtime.bloomFilter.maxNumBits bits.
Once the aggregation executed, the presence of a row in the Bloom filter is evaluated from BloomFilterMightContain expression.
If the size of the side creating the Bloom filter is greater than spark.sql.optimizer.runtime.bloomFilter.creationSideThreshold (10MB by default), the optimization won't apply.
Semi-join reduction
Here too, the runtime filter can be invalidated if the aggregate size is bigger than the broadcast threshold. In that case, the semi-join would become a shuffle join which is not worthwhile.
Otherwise, the rule injects an aggregation of the join key after executing the filtering on the dataset:
private def injectInSubqueryFilter(
filterApplicationSideExp: Expression, filterApplicationSidePlan: LogicalPlan,
filterCreationSideExp: Expression, filterCreationSidePlan: LogicalPlan): LogicalPlan = {
require(filterApplicationSideExp.dataType == filterCreationSideExp.dataType)
val actualFilterKeyExpr = mayWrapWithHash(filterCreationSideExp)
val alias = Alias(actualFilterKeyExpr, actualFilterKeyExpr.toString)()
val aggregate = Aggregate(Seq(alias), Seq(alias), filterCreationSidePlan)
if (!canBroadcastBySize(aggregate, conf)) {
return filterApplicationSidePlan
}
val filter = InSubquery(Seq(mayWrapWithHash(filterApplicationSideExp)),
ListQuery(aggregate, childOutputs = aggregate.output))
Filter(filter, filterApplicationSidePlan)
}
You can see these 2 runtime filters in action just below:
And I meantime, feel invited for the next part of Apache Spark 3.3.0 features that will present new SQL functions!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.3 - joins here:
Related blog posts:
- What's new in Apache Spark 3.3.0 - PySpark
- What's new in Apache Spark 3.3.0 - Structured Streaming
- What's new in Apache Spark 3.3.0 - Data Source V2
- What's new in Apache Spark 3.3 - new functions
Finally cracked the WiFi connection issue at the hotel on my Ubuntu and can share the blog posts planned for the weekend ? To start, the "What's new in #ApacheSpark 3.3.0..." series with join types is here ? https://t.co/PzeAsPVdZi
— Bartosz Konieczny (@waitingforcode) June 27, 2022