
Even though the Project Lightspeed is not there yet, Apache Spark Structured Streaming 3.3.0 has several interesting features that should make your daily life easier.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Trigger.Once in multiple batches
The first important feature is a new trigger called AvailableNow. It sounds mysterious but if we compare it with the Once trigger, you should get the purpose immediately:
- AvailableNow and Once triggers run only once. Their execution takes all data available at the moment of query execution.
- However, as spotted by Bo Zhang who is the author of the feature, the Once trigger processes all the data in the single micro-batch. It leads to several problems, such as scalability or operational complexity. The AvailableNow trigger behaves differently. It still processes all the available data but with respect to the rate limit, such as maxFilesPerTrigger for file stream, or maxOffsetsPerTrigger for Apache Kafka.
How does it work? Besides the new trigger, Apache Spark 3.3.0 has a new interface called SupportsTriggerAvailableNow. Any source supporting the trigger must implement it to return the data available for processing within the trigger scope. Apache Kafka returns the last available offset:
private[kafka010] class KafkaMicroBatchStream
// ...
override def prepareForTriggerAvailableNow(): Unit = {
allDataForTriggerAvailableNow = kafkaOffsetReader.fetchLatestOffsets(
Some(getOrCreateInitialPartitionOffsets()))
}
Next, the MicroBatchExecution running the streaming job uses a MultiBatchExecutor that remains active as long as there is data left to process:
case class MultiBatchExecutor() extends TriggerExecutor {
override def execute(batchRunner: () => Boolean): Unit = while (batchRunner()) {}
}
The difference with the Trigger.Once is visible pretty clearly if you compare the MultiBatchExecutor with SingheBatchExecutor:
case class SingleBatchExecutor() extends TriggerExecutor {
override def execute(batchRunner: () => Boolean): Unit = batchRunner()
}
And why does Trigger.Once ignore the rate limits? Because of this condition applied while planning the Structured Streaming job:
class MicroBatchExecution(
// ...
override lazy val logicalPlan: LogicalPlan = {
// ...
uniqueSources = triggerExecutor match {
case _: SingleBatchExecutor =>
sources.distinct.map {
case s: SupportsAdmissionControl =>
val limit = s.getDefaultReadLimit
if (limit != ReadLimit.allAvailable()) {
logWarning(
s"The read limit $limit for $s is ignored when Trigger.Once is used.")
}
s -> ReadLimit.allAvailable()
case s =>
s -> ReadLimit.allAvailable()
}.toMap
Rate per micro-batch source
Another high-level change concerns a new data source called rate micro-batch. Why this new input looking similar at first glance to the rate data source? Jungtaek Lim, who is the author of the feature, explained that in the JIRA ticket:
The "rate" data source has been known to be used as a benchmark for streaming query.
While this helps to put the query to the limit (how many rows the query could process per second), the rate data source doesn't provide consistent rows per batch into stream, which leads two environments be hard to compare with.
To solve the issue, Jungtaek added a new data source that:
- generates a consistent number of rows per micro-batch
- supports a custom event time; you can define the start time of the job and time change by each micro-batch
Do you want to see the difference with the classical rate source? Watch the fragment of the video below:
RocksDB improvements
RocksDB, which is the state store added in the 3.2.0 release, also improved in the most recent version of Apache Spark. First, Jungtaek Lim added a new configuration entry to control the tracking of the writing operations. The feature addresses the double lookup on the key for the write operations made by RocksDB. If you prefer the performance over the observability, you can set false to the spark.sql.streaming.stateStore.rocksdb.trackTotalNumberOfRows. Unfortunately, you can't have both.
Another change related to the monitoring is a bug fix for the RocksDB memory usage in the state store's metrics. Before, the metric missed the block-cache-usage data which is was included by Yun Tang in the 3.3.0 release.
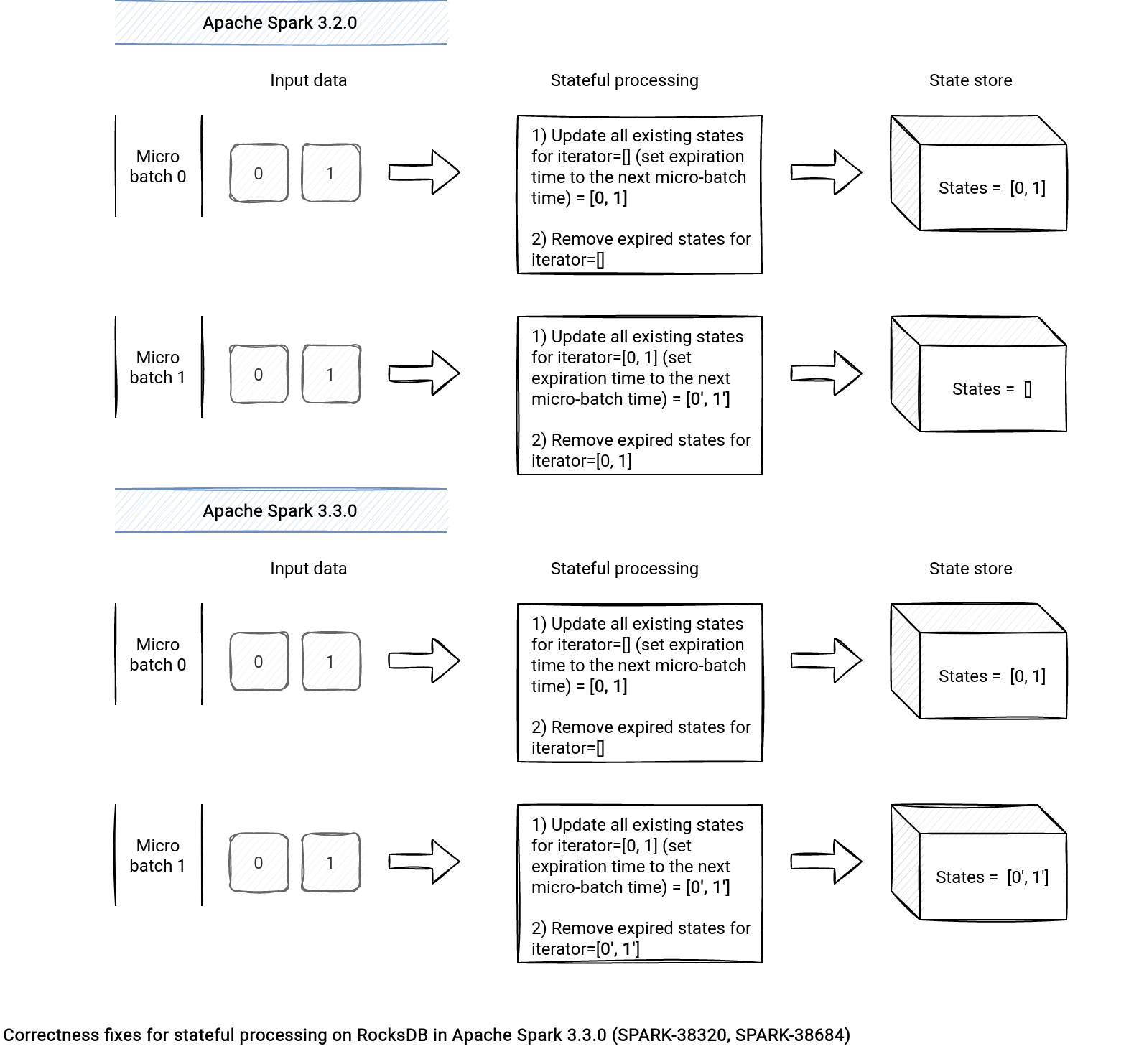
Lastly, Alexander Balikov and Jungtaek Lim solved a correctness issue for stream-to-stream joins and arbitrary stateful processing. Why? In the previous version the state store used the same iterator under-the-hood for both update and delete steps. In consequence, the rows updated in the micro-batch that were about to expire, were removed in the same micro-batch. Now, the delete phase works on the updated iterator. An example of the issue in the following picture:
Distribution and ordering for DataSource V2 writes
In addition to the RocksDB improvements, Apache Spark 3.3.0 also includes some catch-up for the RequiresDistributionAndOrdering interface I described in the What's new in Apache Spark 3.2.0 - Data Source V2 article.
As a reminder, this interface is present when the data source requires a specific ordering or partitioning on the writing side. So far, it only has been implemented for the batch workloads. The 3.3.0 release extends the scope to the streaming writers with this addition to the V2Writes logical rule:
object V2Writes extends Rule[LogicalPlan] with PredicateHelper {
override def apply(plan: LogicalPlan): LogicalPlan = plan transformDown {
// ...
case WriteToMicroBatchDataSource(
relation, table, query, queryId, writeOptions, outputMode, Some(batchId)) =>
val writeBuilder = newWriteBuilder(table, writeOptions, query.schema, queryId)
val write = buildWriteForMicroBatch(table, writeBuilder, outputMode)
val microBatchWrite = new MicroBatchWrite(batchId, write.toStreaming)
val customMetrics = write.supportedCustomMetrics.toSeq
val newQuery = DistributionAndOrderingUtils.prepareQuery(write, query, conf)
WriteToDataSourceV2(relation, microBatchWrite, newQuery, customMetrics)
// ...
The highlighted line is the method where Apache Spark adds an extra RepartitionByExpression and Sort node if any of them is required by the data source.
Structured Streaming has several interesting changes in the 3.3.0 release. But other Apache Spark modules too and we'll try to see it in the next parts of the series!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.3.0 - Structured Streaming here:
- Allow streaming queries with Trigger.Once run in multiple batches DataSource V2: Support required distribution and ordering in SS Introduce a new data source for providing consistent set of rows per microbatch Optimize write path on RocksDB state store provider Correct the logic to measure the memory usage of RocksDB Stream-stream outer join has a possible correctness issue due to weakly read consistent on outer iterators (flat)MapGroupsWithState can timeout groups which just received inputs in the same microbatch
Related blog posts:
- What's new in Apache Spark 3.3.0 - PySpark
- What's new in Apache Spark 3.3.0 - Data Source V2
- What's new in Apache Spark 3.3 - new functions
- What's new in Apache Spark 3.3 - joins
A trigger once with throughput rate semantic and a predictable rate data source, what is their common point? Both are new features added in Apache Spark #StructuredStreaming 3.3.0. But they're not alone and you can get two others in this blog post ? https://t.co/5H8L9mrvuq
— Bartosz Konieczny (@waitingforcode) July 24, 2022