
Sometimes I come back to the topics I already covered, often because by mistake I discover something new that can improve them. And that's the case for my today's article about idempotence in stateful processing.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
I based my proposal for solving sessionization problem on the logs ordered by the event time. The idea was to use the properties of the first arrived log to generate a session id that will always be the same, even after the reprocessing. This approach will probably work most of the time but it will not guarantee the idempotence in the following situation::
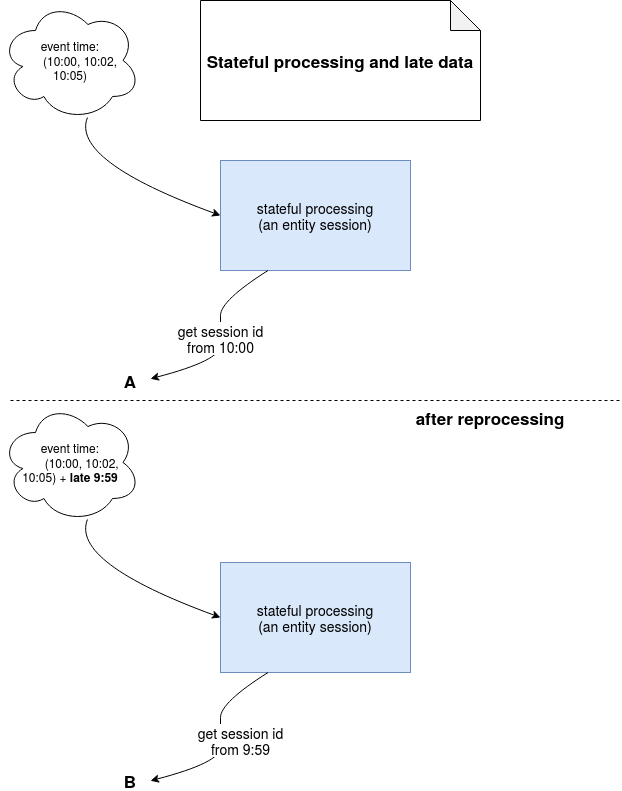
As you can notice, after the reprocessing we included one more log arrived late and this new log changes our id. Is it problematic? As often, it depends. It depends on where you write the data. If you replace the whole dataset generated previously by the new one, that's fine. If you write the data to a Kafka topic and you have a consumer writing them directly to a K/V store where the partition key is the generated id, the consumer will be in trouble because it will write the duplicates. Of course, there are other ways to solve that duplicates problem, like the ones you could discover in my blog post about slowly changing dimensions types and Apache Spark SQL examples, but let's try to be as simple as possible and use data properties for that idempotent guarantee.
Why it can happen?
To answer this question, I will use Apache Kafka source. Let's suppose that after the first execution we checkpointed the following offsets in the processed files:

Now, if for whatever reason we need to reprocess the data from the last successfully executed micro-batch, we'll need to remove it and let Apache Spark recover the state and the offsets to read. Apache Kafka source, unless you set the maxOffsetsPerTrigger property, will try to get as many data as it can, by going to the last offset on each partition at the query time (How Spark knows how many offsets to read?). In the reprocessed micro-batch, you will then get some late data that was not there at the previous execution. And if you based your logic on the event time, you will break the idempotence contract and generate different things. That's only a concrete example using Structured Streaming but it may also happen if you use other frameworks.
To mitigate this issue you can always define the maxOffsetsPerTrigger or, use one of Apache Kafka "metadata" properties to reinforce your idempotency logic.
Offset trap
Initially I thought about offsets. They represent a position of every record quite naturally. But the drawback is they won't work in every configuration. If you don't partition your record on the same key used in your processing, you may get wrong results too. The offset of the late record can come from a smaller partition (another bad luck, your input data store is not evenly balanced!), and it will be promoted as the first event to generate the idempotent id.
Arrival time
Aside from the offset, every record in a Kafka topic has a property called timestamp and it fits better than offsets to strengthen the idempotence. Depending on the used configuration, it defines either when the producer sent this record or when the partition appended it. The former case is called CreateTime and the latter one LogAppendTime, and I already described them in Kafka timestamp as the watermark, so I will not cover the details here. Instead, I will show you some code by using MemoryStream with the same schema as Apache Kafka source:
val inputStream = new MemoryStream[(String, Timestamp)](1, sparkSession.sqlContext)
inputStream.addData(
("""{"entityId": 1, "eventTime": "2020-03-01T10:05:00+00:00", "value": "D"}""", new Timestamp(6L)),
("""{"entityId": 1, "eventTime": "2020-03-01T10:03:45+00:00", "value": "C"}""", new Timestamp(5L)),
("""{"entityId": 1, "eventTime": "2020-03-01T10:03:00+00:00", "value": "B"}""", new Timestamp(3L)),
("""{"entityId": 1, "eventTime": "2020-03-01T10:00:00+00:00", "value": "A"}""", new Timestamp(1L)),
// Let's suppose that we missed this entry in the previous execution
// Here in the reprocessing we include it and it can break the idempotence effort
// if we used eventTime as the sort field
("""{"entityId": 1, "eventTime": "2020-03-01T09:57:00+00:00", "value": "E"}""", new Timestamp(10L))
)
val inputSchema = ScalaReflection.schemaFor[IdempotentIdGenerationValue].dataType.asInstanceOf[StructType]
val inputData = inputStream.toDS().toDF("value", "timestamp")
val mappedEntities = inputData.select(
functions.from_json($"value", inputSchema),
$"timestamp"
).as[(IdempotentIdGenerationValue, Timestamp)]
.groupByKey(valueWithTimestamp => valueWithTimestamp._1.entityId)
.mapGroups((_, groupValues) => {
val sortedEvents = groupValues.toSeq.sortBy(valueWithTimestamp => valueWithTimestamp._2.getTime)
val idKey = s"${sortedEvents.head._2.getTime}-${sortedEvents.head._1.entityId}"
val sessionId = MurmurHash3.stringHash(idKey)
IdempotentIdGenerationSession(sessionId, startTime=sortedEvents.head._1.eventTime,
endTime=sortedEvents.last._1.eventTime)
})
val writeQuery = mappedEntities.writeStream.trigger(Trigger.Once).foreachBatch((dataset, _) => {
IdempotentIdGenerationContainer.session = dataset.collect().head
})
writeQuery.start().awaitTermination()
IdempotentIdGenerationContainer.session shouldEqual IdempotentIdGenerationSession(
-949026733, Timestamp.valueOf("2020-03-01 11:00:00.0"), Timestamp.valueOf("2020-03-01 10:57:00.0")
)
case class IdempotentIdGenerationValue(entityId: Long, eventTime: Timestamp, value: String)
case class IdempotentIdGenerationSession(sessionId: Int, startTime: Timestamp, endTime: Timestamp)
object IdempotentIdGenerationContainer {
var session: IdempotentIdGenerationSession = _
}
Despite a stronger idempotence guarantee, this method also has its drawbacks. The biggest one is the lack of control on the timestamp field that can be set by the producer and in that case, using a timestamp field may not be enough.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Idempotent logic for stateful processing and late data here:
- Structured Streaming + Kafka Integration Guide (Kafka broker version 0.10.0 or higher) Is Kafka timestamp order corresponding to the offset?
Related blog posts:
- Spark Declarative Pipelines internals
- Spark Declarative Pipelines, going further
- Spark Declarative Pipelines 101
How to enforce the idempotency of an #ApacheSpark #StructuredStreaming stateful application? Recently I figured out ? that technical information like ingestion time can help to improve the idempotent generation logic https://t.co/PP4AeOlp8W
— Bartosz Konieczny (@waitingforcode) May 23, 2020