
I bet you know it already. You can limit the max throughput for Apache Spark Structured Streaming jobs for popular data sources such as Apache Kafka, Delta Lake, or raw files. Have you known that you can also control the lower limit, at least for Apache Kafka?
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Admission control
I already covered the max throughput configuration control in the Does maxOffsetsPerTrigger guarantee idempotent processing?, so let me complete the picture and focus on the opposite configuration which is minOffsetsPerTrigger.
Data source V2
Even though V1 sources are still supported, I'm focusing the analysis on the V2 Kafka data source which is KafkaMicroBatchStream.
Apache Spark 3.0.0 has got a new interface, the SupportsAdmissionControl. It's a structure dedicated to streaming data sources which the role is the throughput control:
public interface SupportsAdmissionControl extends SparkDataStream {
default ReadLimit getDefaultReadLimit() { return ReadLimit.allAvailable(); }
Offset latestOffset(Offset startOffset, ReadLimit limit);
default Offset reportLatestOffset() { return null; }
}
Since it's the key for further understanding, let's see how a SupportsAdmissionControl implementation interacts with Apache Spark micro-batches:
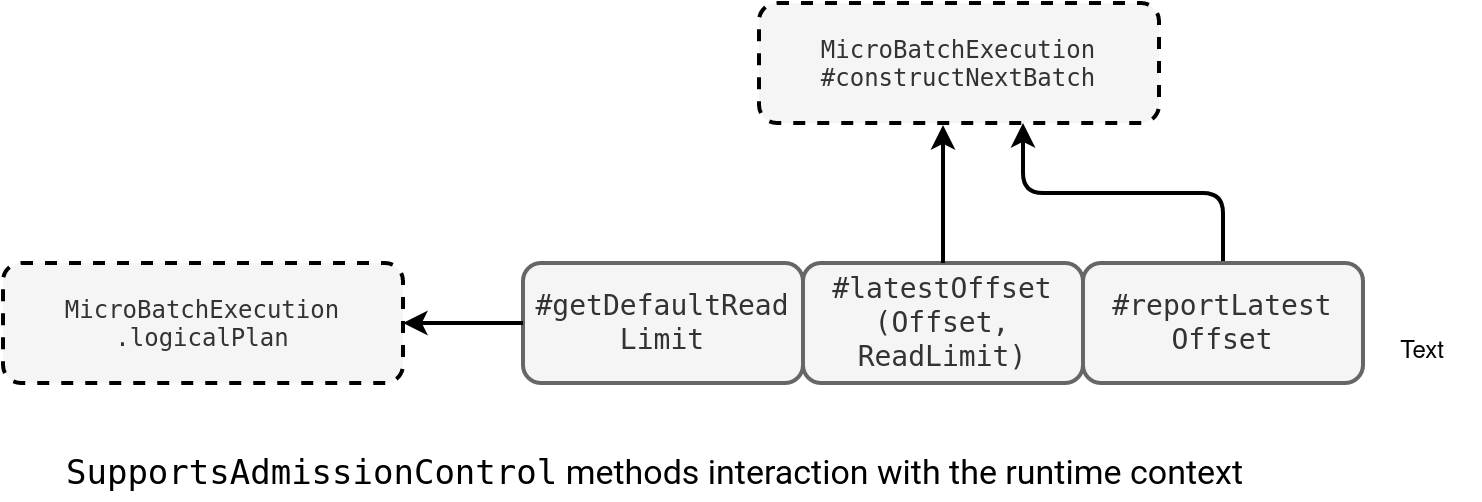
The first interaction takes place when the engine builds the logical plan. It calls the getDefaultReadLimit function for each data source present in the plan and gets corresponding throughput configuration. Later, in the execution stage, MicroBatchExecution calls two other methods, latestOffset to get the offsets available given the rate limit, and reportLatestOffset to get the latest available offset independently on the limits configuration.
To sum-up, the interface provides everything to know what and how much data to read in each micro-batch run. Let's now delve into the implementation part in KafkaMicroBatchStream.
Min offsets
When it comes to the getDefaultReadLimit, it handles three scenarios: both max and min limits defined, only max limit defined, only min limit defined, none of the limits defined. For the first use case, it creates a composite limit instance composed of:
min=ReadLimit.minRows(minOffsetPerTrigger.get, maxTriggerDelayMs), max=ReadLimit.maxRows(maxOffsetsPerTrigger.get)
As you can notice, the min control has an extra trigger delay that you gonna see in the next section. When it comes to the next two scenarios, they use either the minRow or maxRows from the snippet above. The last configuration for missing throughput controls uses the construct taking all data available at the reading time:
ReadLimit.allAvailable()
The configured limits are used in the offsets retrieval method. The min control is a simple subtraction of last processed and most recent offsets in the Kafka partition:
// KafkaMicroBatchStream#delayBatch
val newRecords = latestOffsets.flatMap {
case (topic, offset) =>
Some(topic -> (offset - currentOffsets.getOrElse(topic, 0L)))
}.values.sum.toDouble
if (newRecords < minLimit) true else {
lastTriggerMillis = clock.getTimeMillis()
false
}
As you can see, if there is not enough data, the function returns true to skip the micro-batch and log the following message for you:
// KafkaMicroBatchStream#latestOffset(start: Offset, readLimit: ReadLimit)
val skipBatch = delayBatch(
limit.minRows, latestPartitionOffsets, startPartitionOffsets, limit.maxTriggerDelayMs)
if (skipBatch) {
logDebug(
s"Delaying batch as number of records available is less than minOffsetsPerTrigger")
Some(startPartitionOffsets)
}
Max trigger delay
But the implementation is not that simple because it involves another variable, the maxTriggerDelay. This option is there to avoid an issue when your query never runs because it simply doesn't get enough data for a long time. You can configure a maximal allowed idleness time, hence apply your processing logic even if the min throughput control is not met:
// KafkaMicroBatchStream#delayBatch
if ((clock.getTimeMillis() - lastTriggerMillis) >= maxTriggerDelayMs) {
logDebug("Maximum wait time is passed, triggering batch")
lastTriggerMillis = clock.getTimeMillis()
false
}
Rate limit and available now trigger
The feature looks easy, doesn't it? You define some limits and later Kafka data source controls how many records can be returned. Indeed, but there is maybe something more complex, the available now trigger. Remember, this new addition in Apache Spark 3 that processes all available data at the given moment with the respect of offsets limitations.
At first glance, it should work without issues. KafkaMicroBatchStream implements the prepareForTriggerAvailableNow() that fetches the last offsets available for each partition:
// KafkaMicroBatchStream
override def prepareForTriggerAvailableNow(): Unit = {
allDataForTriggerAvailableNow = kafkaOffsetReader.fetchLatestOffsets(
Some(getOrCreateInitialPartitionOffsets()))
}
This preparation method is called by the micro-batch while preparing the logical plan:
// MicroBatchExecution
override lazy val logicalPlan: LogicalPlan = {
case _: MultiBatchExecutor =>
sources.distinct.map {
case s: SupportsTriggerAvailableNow => s
case s: Source => new AvailableNowSourceWrapper(s)
case s: MicroBatchStream => new AvailableNowMicroBatchStreamWrapper(s)
}.map { s =>
s.prepareForTriggerAvailableNow()
s -> s.getDefaultReadLimit
}.toMap
Apache Spark respects the limits, sounds great! However, you'll see that it doesn't really apply to the available now trigger. Let's see an example. We have a Kafka topic with four records: 1, 2, 3, 4. The job is configured as follows:
println(s"Starting time ${LocalDateTime.now()}")
val kafkaSource = sparkSession.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9094")
.option("subscribe", "numbers")
.option("minOffsetsPerTrigger", 2000)
.option("maxTriggerDelay", "30m")
.option("startingOffsets", "EARLIEST")
.load().withColumn("current_time", functions.current_timestamp())
val writeQuery = kafkaSource.selectExpr("CAST(value AS STRING) AS value_key" , "current_time")
.writeStream
.trigger(Trigger.AvailableNow())
.format("console")
.option("truncate", false)
Therefore, you might be expecting to get the results only 30 minutes later. But surprisingly, you'll get them directly in the first micro-batch:
Starting time 2024-01-28T16:09:49.664896 ------------------------------------------- Batch: 0 ------------------------------------------- +---------+-----------------------+ |value_key|current_time | +---------+-----------------------+ |1 |2024-01-28 16:09:52.666| |2 |2024-01-28 16:09:52.666| |3 |2024-01-28 16:09:52.666| |4 |2024-01-28 16:09:52.666| +---------+-----------------------+
Is it weird? No because the code doesn't delay the micro-batch for the first execution:
private def delayBatch(
minLimit: Long, latestOffsets: Map[TopicPartition, Long], currentOffsets: Map[TopicPartition, Long], maxTriggerDelayMs: Long): Boolean = {
// Checking first if the maxbatchDelay time has passed
if ((clock.getTimeMillis() - lastTriggerMillis) >= maxTriggerDelayMs) {
logDebug("Maximum wait time is passed, triggering batch")
lastTriggerMillis = clock.getTimeMillis()
false
}
Since the lastTriggerMillis is unknown in the first micro-batch, the function simply returns false without checking the min configuration in the else case.
Despite this last surprising point, the min rate limit can be useful when you don't want to trigger a micro-batch when there is no data. It could be useful for example to optimize the DataFrame size written to your data sink. Too small writes could result in an increased I/O overhead and under optimized resource usage.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩