
Aside from the joins presented in the previous blog post, Structured Streaming also got a few other interesting new features that I will present here.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
The post is organized into 4 sections, presenting one category of changes each.
State store
To start, two configuration properties changed at the state store level. The first of them is more a refactoring of the already existing code since the property to configure the state store maintenance interval exists since Apache Spark 2. However, so far it was hidden in the StateStore class and in Apache Spark 3.1.1 it moved to the usual configuration class, the SQLConf.
The second configuration change is a new feature. Starting from Apache Spark 3.1.1 you can set the state store compression codec. You can set it in the spark.sql.streaming.stateStore.compression.codec property. By default, the property is set to the LZ4 algorithm used in the previous Apache Spark versions.
To terminate this category, Apache Spark UI got some extra information regarding the state store! This new feature about the state store metrics (number of updated rows, state store memory size, watermark gap )completes the metrics added in Apache Spark 3.0:
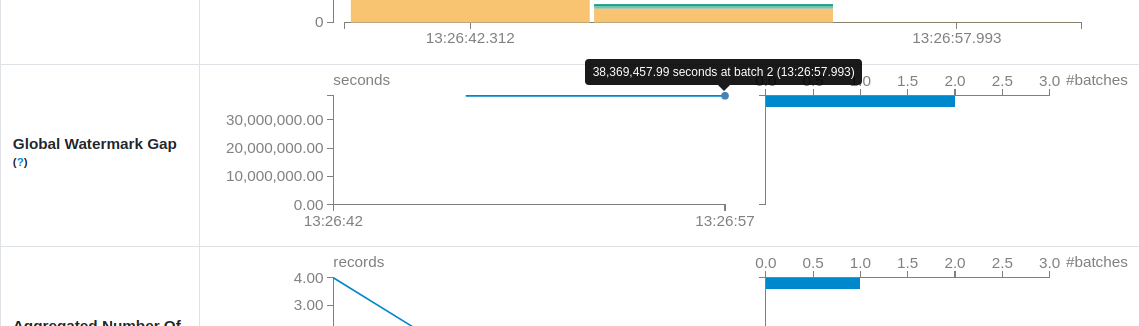
What the watermark gap is?
Watermark gap represents the difference between the global watermark of the query and the micro-batch execution timestamp. Below you can find a picture illustrating this difference between a watermark set to 2020-01-01T10:16:00.000Z and the current time 2021-03-20T13:28:00.000Z:
Besides these visual changes, Apache Spark 3.1 also evolved at the API level.
DataStreamReader and DataStreamWriter APIs
The first thing regarding the API is the tables support with toTable(tableName: String) and table() methods added, respectively, to DataStreamWriter and DataStreamReader classes. To explain the mechanism behind this feature, I have to take a step back and cover the topic I missed in my Apache Spark 3.0 update study - the table API!
If you check the classes annotated with @since 3.0.0, you will certainly found one called Table exposing the following API:
public interface Table {
String name();
StructType schema();
default Map<String, String> properties() {
return Collections.emptyMap();
}
default Transform[] partitioning() {
return new Transform[0];
}
Set<TableCapability> capabilities();
}
The 3 first methods are quite obvious because they identify the table by the name and additional properties. The next method, partitioning(), defines the partitioning for the written records. Among the implementations, you will find the classes like YearsTransform, DaysTransform or BucketTransform. The final method, capabilities(), defines the scope supported by the table. And the scope is organized inside a TableCapability enum with the entries like:
public enum TableCapability {
BATCH_READ,
MICRO_BATCH_READ,
CONTINUOUS_READ,
BATCH_WRITE,
STREAMING_WRITE,
TRUNCATE,
OVERWRITE_BY_FILTER,
OVERWRITE_DYNAMIC,
ACCEPT_ANY_SCHEMA,
V1_BATCH_WRITE
}
Did one entry catch your eye? Maybe STREAMING_WRITE? Yes, it's the most important one regarding the toTable method added in the 3.1.1 release. Any table having this capability automatically supports append writes in Structured Streaming. It's by the way the prerequisite verified in the toTable method itself for V2 sinks:
def toTable(tableName: String): StreamingQuery = {
// ...
import org.apache.spark.sql.execution.datasources.v2.DataSourceV2Implicits._
tableInstance match {
case t: SupportsWrite if t.supports(STREAMING_WRITE) => startQuery(t, extraOptions)
case t: V2TableWithV1Fallback =>
writeToV1Table(t.v1Table)
case t: V1Table =>
writeToV1Table(t.v1Table)
case t => throw new AnalysisException(s"Table $tableName doesn't support streaming " +
s"write - $t")
}
But wait a minute. Does it apply to V1 sinks? No. STREAMING_WRITE didn't exist when they're created and the V1 sinks will use a simple format(...)...start() writer, under some conditions though:
def writeToV1Table(table: CatalogTable): StreamingQuery = {
if (table.tableType == CatalogTableType.VIEW) {
throw new AnalysisException(s"Streaming into views $tableName is not supported.")
}
require(table.provider.isDefined)
if (source != table.provider.get) {
throw new AnalysisException(s"The input source($source) is different from the table " +
s"$tableName's data source provider(${table.provider.get}).")
}
format(table.provider.get)
.option("path", new Path(table.location).toString).start()
}
And what about reading? Here too, Apache Spark relies on the classes shared with the batch abstraction. Under-the-hood, the table(tableName: String) method creates an UnresolvedRelation but for our streaming use case, this node will have the isStreaming attribute set to true. During the resolution step, the analyzer will lookup for the table and later map it to an appropriate, batch or streaming, abstraction:
object ResolveTables extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = ResolveTempViews(plan).resolveOperatorsUp {
case u: UnresolvedRelation =>
lookupV2Relation(u.multipartIdentifier, u.options, u.isStreaming)
.map { relation =>
val (catalog, ident) = relation match {
case ds: DataSourceV2Relation => (ds.catalog, ds.identifier.get)
case s: StreamingRelationV2 => (s.catalog, s.identifier.get)
}
SubqueryAlias(catalog.get.name +: ident.namespace :+ ident.name, relation)
}.getOrElse(u)
// ...
private def lookupV2Relation(
identifier: Seq[String],
options: CaseInsensitiveStringMap,
isStreaming: Boolean): Option[LogicalPlan] =
expandRelationName(identifier) match {
case NonSessionCatalogAndIdentifier(catalog, ident) =>
CatalogV2Util.loadTable(catalog, ident) match {
case Some(table) =>
if (isStreaming) {
Some(StreamingRelationV2(None, table.name, table, options,
table.schema.toAttributes, Some(catalog), Some(ident), None))
} else {
Some(DataSourceV2Relation.create(table, Some(catalog), Some(ident), options))
}
case None => None
}
case _ => None
}
The StreamingRelationV2 is composed of multiple attributes and one of them is the Table interface. If you check its usage, you will notice that like for the writing, Apache Spark relies on the capabilities to know whether the table works in streaming mode:
class MicroBatchExecution(
sparkSession: SparkSession,
// ...) extends StreamExecution(
sparkSession, name, checkpointRoot, analyzedPlan, sink,
trigger, triggerClock, outputMode, deleteCheckpointOnStop) {
override lazy val logicalPlan: LogicalPlan = {
val _logicalPlan = analyzedPlan.transform {
// ...
case s @ StreamingRelationV2(src, srcName, table: SupportsRead, options, output, _, _, v1) =>
val dsStr = if (src.nonEmpty) s"[${src.get}]" else ""
val v2Disabled = disabledSources.contains(src.getOrElse(None).getClass.getCanonicalName)
if (!v2Disabled && table.supports(TableCapability.MICRO_BATCH_READ)) {
// ...
Curious about the runtime effect? Let's move to the demo!
Table API was something I missed in my Apache Spark exploration, but it was not the case of the next update.
Code base consistency fixes
I remember when I was exploring file sink in Structured Streaming and was surprised when I found the not used DELETE_ACTION in the file sink log. The entry was added in the first version of the sink to physically remove all files marked as "deleted" in the compaction phase. However, 5 years later, this feature was still not implemented and appeared to be quite confusing for the code base readers. Fortunately, it's not the case anymore since Michał Wieleba removed it in SPARK-32648.
The second code base fix concerns the SupportsStreamingUpdate trait. To avoid any confusion, in Apache Spark 3.1, it was renamed to SupportsStreamingUpdateAsAppend. In reality, the "update" in the name represents the "update as an append" and to make it more understandable, Apache Spark contributors decided to rename it. Also, the renamed trait lost the update() method and got a new TODO comment to define the update behavior:
/**
* An internal `WriteBuilder` mixin to support UPDATE streaming output mode. Now there's no good
* way to pass the `keys` to upsert or replace (delete -> append), we do the same with append writes
* and let end users to deal with.
*
* This approach may be still valid for streaming writers which can't do the upsert or replace.
* We can promote the API to the official API along with the new API for upsert/replace.
*/
// TODO: design an official API for streaming output mode UPDATE which can do the upsert
// (or delete -> append).
trait SupportsStreamingUpdateAsAppend extends WriteBuilder {
}
And before I terminate this blog post, I would like to complete the list of the updates with the changes impacting Apache Kafka.
Apache Kafka
To start this section, I found a quite challenging bug impacting the previous release, solved with SPARK-33635. However, finding the root case was not easy! It happens that the regression was caused by too many calls for a method checking the delegation token update method. Jungtaek Lim implemented a short-term solution backported to 3.0.2, which reorders the check condition so that the real verification happens only when the application really uses the delegation token. In other words, this snippet from Spark 3.0...
if (HadoopDelegationTokenManager.isServiceEnabled(sparkConf, "kafka") && clusterConfig.isDefined && params.containsKey(SaslConfigs.SASL_JAAS_CONFIG)) {
...changes to this one in the 3.1:
if (clusterConfig.isDefined && params.containsKey(SaslConfigs.SASL_JAAS_CONFIG) && HadoopDelegationTokenManager.isServiceEnabled(sparkConf, "kafka")) {
The author of the bug fix also spotted that there was a noticeable change in Apache Kafka logger, which promoted some "debug" logs from a past version to the "info" log in the new version used in Structured Streaming. If you observe some extra latency and more logs than before, you can try to configure the logger with log4j.logger.org.apache.kafka.clients.consumer.KafkaConsumer=WARN.
Among other changes impacting Apache Kafka, Gabor Somogyi implemented a new version for Kafka's poll(long) method deprecated since Kafka 2.0. The deprecation was mostly due to the risk of an infinitive lock when the broker became unavailable at the moment of polling - and so despite having the timeout parameter in the method! At first glance, changing a method by another looks easy, but in fact, it had a wider scope and required a bit more effort. You can notice that on the driver's side where the offsets fetching mechanism based on KafkaConsumer was replaced by AdminClient:
private[kafka010] object KafkaOffsetReader extends Logging {
def build(
consumerStrategy: ConsumerStrategy,
driverKafkaParams: ju.Map[String, Object],
readerOptions: CaseInsensitiveMap[String],
driverGroupIdPrefix: String): KafkaOffsetReader = {
if (SQLConf.get.useDeprecatedKafkaOffsetFetching) {
logDebug("Creating old and deprecated Consumer based offset reader")
new KafkaOffsetReaderConsumer(consumerStrategy, driverKafkaParams, readerOptions,
driverGroupIdPrefix)
} else {
logDebug("Creating new Admin based offset reader")
new KafkaOffsetReaderAdmin(consumerStrategy, driverKafkaParams, readerOptions,
driverGroupIdPrefix)
}
}
private[kafka010] class KafkaSourceProvider extends DataSourceRegister {
// ...
override def createSource(
sqlContext: SQLContext,
metadataPath: String,
schema: Option[StructType],
providerName: String,
parameters: Map[String, String]): Source = {
// ...
val startingStreamOffsets = KafkaSourceProvider.getKafkaOffsetRangeLimit(
caseInsensitiveParameters, STARTING_OFFSETS_BY_TIMESTAMP_OPTION_KEY,
STARTING_OFFSETS_OPTION_KEY, LatestOffsetRangeLimit)
val kafkaOffsetReader = KafkaOffsetReader.build(
strategy(caseInsensitiveParameters),
kafkaParamsForDriver(specifiedKafkaParams),
caseInsensitiveParameters,
driverGroupIdPrefix = s"$uniqueGroupId-driver")
new KafkaSource(
sqlContext,
kafkaOffsetReader,
kafkaParamsForExecutors(specifiedKafkaParams, uniqueGroupId),
caseInsensitiveParameters,
metadataPath,
startingStreamOffsets,
failOnDataLoss(caseInsensitiveParameters))
}
The 3.1 release of Apache Spark brought a lot of exciting features for Structured Streaming. Aside from the joins presented previously, you can see that the state store evolved, the API was enriched, and finally, some tricky bugs were fixed. But Structured Streaming is not the single impacted component in this new release. Another one is PySpark, and it will be the topic of the next blog post!
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about What's new in Apache Spark 3.1 - Structured Streaming here:
- A Kafka app which tests consumer assignment. KIP-266: Fix consumer indefinite blocking behavior Make state store maintenance interval as SQL config Configurable StateStore compression codec Add DataStreamReader.table API Add DataStreamWriter.toTable API Remove unused DELETE_ACTION in FileStreamSinkLog Refactor SupportsStreamingUpdate to represent actual meaning of the behavior Performance regression in Kafka read Kafka connector infinite wait because metadata never updated Expose missing information (graphs) on SS UI
Related blog posts:
- What's new in Apache Spark 3.1.1 - new built-in functions
- What's new in Apache Spark 3.1 - JDBC (WIP) and DataSource V2 API
- What's new in Apache Spark 3.1 - Kubernetes Generally Available!
- What's new in Apache Spark 3.1 - nodes decommissioning
- What's new in Apache Spark 3.1 - predicate pushdown for JSON, CSV and Apache Avro
Refactoring, Spark UI, table API, some tricky bug fixes and AdminClient for Apache Kafka are the remaining changes in #ApacheSpark #StructuredStreaming 3.1.1 I wanted to cover before presenting updates of other modules next weeks ? https://t.co/e7HPzssmU9
— Bartosz Konieczny (@waitingforcode) March 27, 2021