
Streaming processing is great because it guarantees low latency and quite fresh insight. But on the other side, we won't always need such latency and for these situations, a batch processing will often be a better fit because of apparently simpler semantics. In data architectures, batch layer is perceived differently. Kappa, which is a streaming-based model, makes it optional when the streaming broker can guarantee long data retention. But if it's not the case, the data must be copied into some more persistent storage like a distributed file system.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Transforming the data at motion into the data in rest is not an easy task and through this post, I will try to show why and how to implement it with Apache Kafka.
"Too small and too many" problem
The problem of moving the records from a streaming broker to file system static sink can be reformulated as a problem of transforming data in motion into data at rest. At first glance, this transformation seems easy because we can simply read the data in micro-batches and write them to some directory. It would be fine for all use cases which don't involve event-time partitioned data. But it's not the case because the partitioned data has the advantage of reducing the volume of data to read, especially in time-series oriented computations.
A sensible point of this transformation concerns data quality. Streaming data may be late, e.g. one device may be offline for long hours before it will be able to send locally buffered records. If you accept such records, you risk to end up with a lot of small files in your batch layer because of these out-of-order messages. That's what I called this section "too small, too many".
If you have a lot of small files, they will have a negative impact of the batch processing side because of increased I/O rate. And if you have some I/O constraints, you shouldn't neglect that fact. There are also historical reasons for the systems like HDFS where a big number of small files will negatively impact the node storing the file system organization (NameNode in HDFS; see Handling small files in HDFS).
Even though the streaming broker is the main component of modern data-architectures, not all use cases require high latency and not all are able to process the data in small micro-batches. Because of that the batch storage layer is an indissociable part of such systems. Fortunately, the solutions exist to consolidate real-time events into static partitioned blocks of data. None of them is perfect though. You will always have a risk to have some small files from time to time because of very late events. But generally, they should provide quite correct results. In the next sections, I will show 3 possible solutions to solve the problem of moving data from streaming to file system.
Solution 1: Kafka Connect
Through Kafka Connect connectors, Apache Kafka supports natively what we want to achieve here. A connector is a scalable and fault-tolerant plugin able to move the data in 2 directions (in/out). The nice thing is that there are a lot of available connectors which are maintained by Confluent and the community. Moreover, the connectors are released with Confluent Community Licence and their code is open. Here I will focus on the HDFS connector but I invite you to check the list of all available ones (there are plenty of them working with cloud providers storage layers).
At first glance, HDFS connector has everything we need to transform our data at motion into the data at rest. It provides exactly-once delivery with the concept that you maybe already know from Apache Spark, which is Write Ahead Log (I talked about it in Spark Streaming checkpointing and Write Ahead Logs). The connector also offers the possibility to partition the data with the event's value. And the last but not least advantage is the extendability. You can customize the connector's partitioner and output format by simply extending appropriate classes.
To test this solution I used Confluent's platform and Hadhoop Docker images combined in a single docker-compose for simplicity:
# all up to Hadoop's declaration comes from https://github.com/confluentinc/cp-docker-images/tree/5.1.2-post/examples/cp-all-in-one
---
version: '2'
services:
zookeeper:
image: confluentinc/cp-zookeeper:5.1.2
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-enterprise-kafka:5.1.2
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "9092:9092"
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker:9092
CONFLUENT_METRICS_REPORTER_ZOOKEEPER_CONNECT: zookeeper:2181
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
schema-registry:
image: confluentinc/cp-schema-registry:5.1.2
hostname: schema-registry
container_name: schema-registry
depends_on:
- zookeeper
- broker
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL: 'zookeeper:2181'
connect:
image: confluentinc/kafka-connect-datagen:latest
build:
context: .
dockerfile: Dockerfile
hostname: connect
container_name: connect
depends_on:
- zookeeper
- broker
- schema-registry
ports:
- "8083:8083"
environment:
CONNECT_BOOTSTRAP_SERVERS: 'broker:9092'
CONNECT_REST_ADVERTISED_HOST_NAME: connect
CONNECT_REST_PORT: 8083
CONNECT_GROUP_ID: compose-connect-group
CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000
CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter
CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONNECT_INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_ZOOKEEPER_CONNECT: 'zookeeper:2181'
# Assumes image is based on confluentinc/kafka-connect-datagen:latest which is pulling 5.1.2 Connect image
CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-5.1.2.jar
CONNECT_PRODUCER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor"
CONNECT_CONSUMER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor"
CONNECT_PLUGIN_PATH: "/usr/share/java,/usr/share/confluent-hub-components"
CONNECT_LOG4J_LOGGERS: org.apache.zookeeper=ERROR,org.I0Itec.zkclient=ERROR,org.reflections=ERROR
control-center:
image: confluentinc/cp-enterprise-control-center:5.1.2
hostname: control-center
container_name: control-center
depends_on:
- zookeeper
- broker
- schema-registry
- connect
- ksql-server
ports:
- "9021:9021"
environment:
CONTROL_CENTER_BOOTSTRAP_SERVERS: 'broker:9092'
CONTROL_CENTER_ZOOKEEPER_CONNECT: 'zookeeper:2181'
CONTROL_CENTER_CONNECT_CLUSTER: 'connect:8083'
CONTROL_CENTER_KSQL_URL: "http://ksql-server:8088"
CONTROL_CENTER_KSQL_ADVERTISED_URL: "http://localhost:8088"
CONTROL_CENTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
CONTROL_CENTER_REPLICATION_FACTOR: 1
CONTROL_CENTER_INTERNAL_TOPICS_PARTITIONS: 1
CONTROL_CENTER_MONITORING_INTERCEPTOR_TOPIC_PARTITIONS: 1
CONFLUENT_METRICS_TOPIC_REPLICATION: 1
PORT: 9021
ksql-server:
image: confluentinc/cp-ksql-server:5.1.2
hostname: ksql-server
container_name: ksql-server
depends_on:
- broker
- connect
ports:
- "8088:8088"
environment:
KSQL_CONFIG_DIR: "/etc/ksql"
KSQL_LOG4J_OPTS: "-Dlog4j.configuration=file:/etc/ksql/log4j-rolling.properties"
KSQL_BOOTSTRAP_SERVERS: "broker:9092"
KSQL_HOST_NAME: ksql-server
KSQL_APPLICATION_ID: "cp-all-in-one"
KSQL_LISTENERS: "http://0.0.0.0:8088"
KSQL_CACHE_MAX_BYTES_BUFFERING: 0
KSQL_KSQL_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
KSQL_PRODUCER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor"
KSQL_CONSUMER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor"
ksql-cli:
image: confluentinc/cp-ksql-cli:5.1.2
container_name: ksql-cli
depends_on:
- broker
- connect
- ksql-server
entrypoint: /bin/sh
tty: true
ksql-datagen:
image: confluentinc/ksql-examples:5.1.2
hostname: ksql-datagen
container_name: ksql-datagen
depends_on:
- ksql-server
- broker
- schema-registry
- connect
command: "bash -c 'echo Waiting for Kafka to be ready... && \
cub kafka-ready -b broker:9092 1 40 && \
echo Waiting for Confluent Schema Registry to be ready... && \
cub sr-ready schema-registry 8081 40 && \
echo Waiting a few seconds for topic creation to finish... && \
sleep 11 && \
tail -f /dev/null'"
environment:
KSQL_CONFIG_DIR: "/etc/ksql"
KSQL_LOG4J_OPTS: "-Dlog4j.configuration=file:/etc/ksql/log4j-rolling.properties"
STREAMS_BOOTSTRAP_SERVERS: broker:9092
STREAMS_SCHEMA_REGISTRY_HOST: schema-registry
STREAMS_SCHEMA_REGISTRY_PORT: 8081
rest-proxy:
image: confluentinc/cp-kafka-rest:5.1.2
depends_on:
- zookeeper
- broker
- schema-registry
ports:
- 8082:8082
hostname: rest-proxy
container_name: rest-proxy
environment:
KAFKA_REST_HOST_NAME: rest-proxy
KAFKA_REST_BOOTSTRAP_SERVERS: 'broker:9092'
KAFKA_REST_LISTENERS: "http://0.0.0.0:8082"
KAFKA_REST_SCHEMA_REGISTRY_URL: 'http://schema-registry:8081'
hadoop:
image: sequenceiq/hadoop-docker:2.7.1
expose:
- 9000
hostname: hadoop-hdfs
container_name: hadoop-hdfs
After starting the containers, I accessed to the Schema Registry container (confluentinc/cp-schema-registry:5.1.2 in docker ps list) in order to start Avro producer and define the schema this way:
# docker exec -ti 553049905f84 bin/bash
kafka-avro-console-producer --broker-list broker:9092 --topic test-hdfs-connector --property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"first_name","type":"string"}]}'
After that, I sent the connector's definition via the REST endpoint:
curl -d '{
"name": "test-hdfs-sink",
"config": {
"connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schemas.enable": "true",
"key.converter.schemas.enable": "false",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"tasks.max": "1",
"topics": "test-hdfs-connector",
"hdfs.url": "hdfs://hadoop-hdfs:9000",
"format.class": "io.confluent.connect.hdfs.avro.AvroFormat",
"flush.size": "5",
"partitioner.class": "io.confluent.connect.storage.partitioner.FieldPartitioner",
"partition.field.name": "first_name",
"name": "test-hdfs-sink"
}
}' -H "Content-Type: application/json" -X POST http://localhost:8083/connectors
Some minutse after, I used the tasks endpoint http://localhost:8083/connectors/test-hdfs-sink/tasks/0/status to ensure that the connector started correctly:
{"id":0,"state":"RUNNING","worker_id":"connect:8083"}
When everything was fine, I sent some simple messages in the Schema Registry's Avro producer:
{"first_name": "name 1"}
{"first_name": "name 2"}
{"first_name": "name 1"}
{"first_name": "name 1"}
{"first_name": "name 1"}
{"first_name": "name 1"}
And at the end I checked whether the data was copied and partitioned in HDFS:
bartosz:~$ docker exec -ti 3ef33a679420 bin/bash bash-4.1# cd $HADOOP_PREFIX bash-4.1# bin/hdfs dfs -ls /topics/test-hdfs-connector 19/03/13 12:42:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 2 items drwxr-xr-x - root supergroup 0 2019-03-13 12:41 /topics/test-hdfs-connector/first_name=name 1 drwxr-xr-x - root supergroup 0 2019-03-13 12:41 /topics/test-hdfs-connector/first_name=name 2 bash-4.1# bin/hdfs dfs -ls /topics/test-hdfs-connector/first_name=name\ 1 19/03/13 12:42:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 1 items -rw-r--r-- 3 root supergroup 228 2019-03-13 12:41 /topics/test-hdfs-connector/first_name=name 1/test-hdfs-connector+0+0000000000+0000000004.avro
For the sake of simplicity, the output was only based on the number of records but you can also add the configuration for the time-based rotated commits where the new files will be created after some specific period of time independently on the accumulated number of records.
Solution 2: partitioned data source
Kafka Connect is undoubtedly the best solution - maintained by Confluent and the community, fault-tolerant and scalable. But as an exercise, I will see how to do it differently and provide the most similar semantics.
The first idea uses a different intermediary buffer for each of the partitioned data. The events are read by one consumer and forwarded to the topic corresponding to the partition value. For instance, for the data partitioned at hourly basic, we'll need 24 buffers every day. Each of buffers will be read by one long-running consumer during some specific period of time. Each consumer will group the events in micro-batches and write them to the file system in an idempotent manner (always the same name). After writing the files, it will commit its offsets to the broker:
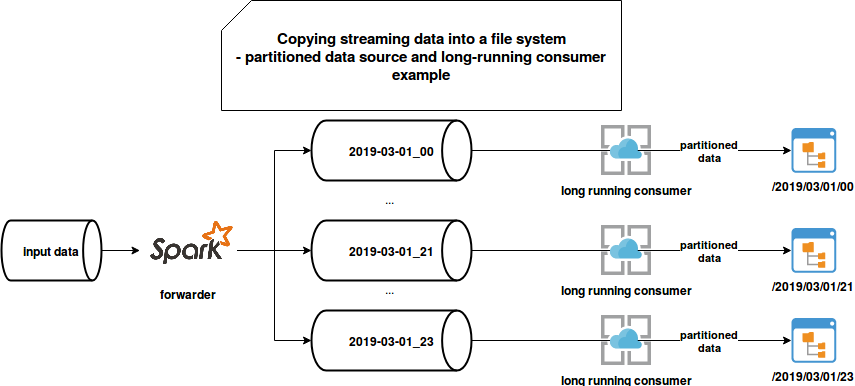
At the end of the day the 24 topics are deleted and replaced with the 24 topics for the next day. You can also optimize that approach and give a shorter expiration time for each topic. But all this orchestration adds some extra operational work.
This solution can be also simplified with the topic partitions storing hourly data. Unfortunately, it may negatively impact the latency since every partition can be consumed only by 1 consumer. The proposed schema mitigates it because every hourly topic can have as many partitions as we want.
In addition to the operational costs, the architecture also has other drawbacks, like increased costs because of the data duplication in 2 places (network, computation, storage). It also requires some extra monitoring effort because at given moment t we can have multiple hourly topics.
Among the good points, we can list the scalability. Since every partition is treated particularly, we can apply different scaling strategies to it in order to reduce the processing latency. But still, it's more complex overall than the Kafka Connector.
Solution 3: real-time + batch
In this approach, the data is continuously read from the input topic and written independently on the partitioning to a staging directory. Later, the small and unordered files are partitioned and grouped by a batch job:
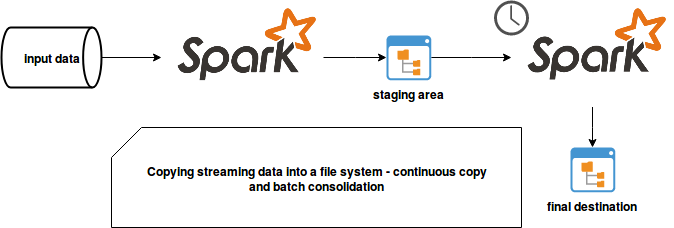
The consolidation job can be triggered at a fixed interval or dynamically, for instance after accumulating some specific volume of data:
"all produced files" should "be processed and some of them compressed" in {
val maxExecutionTime = System.currentTimeMillis() + 40000L
new Thread(new ArchivesProducer(JobConfig.StagingDir, maxExecutionTime)).start()
val sparkSession: SparkSession = SparkSession.builder()
.appName("Spark SQL files compression test")
.master("local[2]").getOrCreate()
val schema = StructType(Seq(StructField("id", IntegerType, false), StructField("time", LongType, false)))
var batchId = 0
while (System.currentTimeMillis() < maxExecutionTime) {
// Move files from the previous generation to the final output - only when they have a valid size
val checkTime = System.currentTimeMillis()
val newCompressedFiles = FileUtils.listFiles(new File(s"${JobConfig.IntermediaryDir}"),
Array("json"), true).asScala.toSeq
val classifiedFiles = classifyFilesToFinalAndNot(checkTime, newCompressedFiles)
moveBigEnoughFilesToFinalDirectory(classifiedFiles.getOrElse(true, Seq.empty))
val newFilesToCompress = FileUtils.listFiles(new File(JobConfig.StagingDir), Array("json"), true).asScala.toSeq
val filesToCompress = (classifiedFiles.getOrElse(false, Seq.empty) ++ newFilesToCompress)
import sparkSession.implicits._
val batchOutputDir = s"${JobConfig.IntermediaryDir}/${batchId}"
val fileNamesToCompress = filesToCompress.map(file => file.getAbsolutePath)
sparkSession.read.schema(schema).json(fileNamesToCompress: _*).withColumn("partition_column", $"id")
.write.partitionBy("partition_column").mode(SaveMode.Overwrite).json(batchOutputDir)
IdleStateController.removeTooOldPartitions(checkTime)
updatePartitionsState(checkTime, batchOutputDir)
deleteAlreadyProcessedFiles(filesToCompress)
batchId += 1
}
val linesFromAllFiles = FileUtils.listFiles(new File(JobConfig.BaseDir), Array("json"), true).asScala
.flatMap(file => {
val fileJsonLines = FileUtils.readFileToString(file).split("\n")
fileJsonLines
})
linesFromAllFiles.foreach(line => {
Store.allSavedLines should contain(line)
})
linesFromAllFiles should have size Store.allSavedLines.size
FileUtils.listFiles(new File(JobConfig.FinalOutputDir), null, true).asScala.nonEmpty shouldBe true
}
private def classifyFilesToFinalAndNot(checkTime: Long, filesToClassify: Seq[File]): Map[Boolean, Seq[File]] = {
filesToClassify.groupBy(file => {
file.length() >= JobConfig.OutputMinSize1KbInBytes ||
IdleStateController.canBeTransformedToFinal(checkTime, file.getParentFile.getName)
})
}
private def moveBigEnoughFilesToFinalDirectory(files: Seq[File]): Unit = {
val allRenamed = files.forall(file => {
file.renameTo(new File(s"${JobConfig.FinalOutputDir}/${System.nanoTime()}-${file.getName}"))
})
assert(allRenamed, "All files should be moved to the target directory but it was not the case")
}
private def updatePartitionsState(checkTime: Long, partitionsDir: String) = {
val createdPartitions =
FileUtils.listFilesAndDirs(new File(partitionsDir), FalseFileFilter.INSTANCE, DirectoryFileFilter.DIRECTORY).asScala
createdPartitions
.filter(partitionDir => partitionDir.getName.startsWith("partition_"))
.foreach(partitionDir => {
IdleStateController.updatePartition(checkTime, partitionDir.getName)
})
}
private def deleteAlreadyProcessedFiles(files: Seq[File]) = {
files.foreach(file => {
if (!file.delete()) {
throw new IllegalStateException(s"An error occurred during the delete of ${file.getName}. " +
s"All files to delete were: ${files.map(file => file.getAbsolutePath).mkString(", ")}")
}
})
}
object IdleStateController {
private val MaxIdleTimeMillis = TimeUnit.MINUTES.toMillis(2)
private var PartitionsWithTTL: Map[String, Long] = Map.empty
def updatePartition(checkTime: Long, partition: String) = {
if (!PartitionsWithTTL.contains(partition)) {
PartitionsWithTTL += (partition -> (checkTime + MaxIdleTimeMillis))
}
}
def canBeTransformedToFinal(checkTime: Long, partition: String) = {
false // checkTime > PartitionsWithTTL(partition)
}
def removeTooOldPartitions(checkTime: Long) = {
PartitionsWithTTL = PartitionsWithTTL.filter {
case (_, expirationTime) => checkTime < expirationTime
}
}
}
object JobConfig {
val BaseDir = "/tmp/archiver"
val StagingDir = s"${BaseDir}/staging"
val FinalOutputDir = s"${BaseDir}/test_output"
val IntermediaryDir = s"${BaseDir}/test_temporary"
val OutputMinSize1KbInBytes = 1000
}
class ArchivesProducer(outputDir: String, maxExecutionTime: Long) extends Runnable {
override def run(): Unit = {
while (System.currentTimeMillis() < maxExecutionTime - 5000) {
val jsons = (0 to 10).map(message => s"""{"id":${message},"time":${System.currentTimeMillis()}}""")
val jsonsRandom = (0 to ThreadLocalRandom.current().nextInt(10))
.map(message => s"""{"id":${message},"time":${System.currentTimeMillis()+10}}""")
Store.addLines(jsons)
Store.addLines(jsonsRandom)
FileUtils.write(new File(s"${outputDir}/${System.currentTimeMillis()}.json"), Seq(jsons.mkString("\n"),
jsonsRandom.mkString("\n")).mkString("\n"))
Thread.sleep(200)
}
}
}
object Store {
private var jsonLines: Seq[String] = Seq.empty
def addLines(newLines: Seq[String]): Unit = {
jsonLines = jsonLines ++ newLines
}
def allSavedLines = jsonLines
}
This solution also has some bad points. Depending on the trigger frequency, it can slightly increase data latency. It can lead to the situation when the hourly-based batch consumers will miss some part of the data. Of course, the archiver can also write them immediately but it would increase the number of small files.
On the other side, the risk of small files exists with Kafka Connect as well. If you define too aggressive rotation-based commits, the files will be generated independently on the number of accumulated records.
In this article I wanted to show different methods to transform data at motion into data at rest, in other terms, moving data from streaming to a static source. I wanted also to prove that the perfect solution, i.e. the one not generating small files, is very hard to achieve because of the late data. But despite that fact, we should always tend to minimize that risk and optimize the static storage layer part for batch consumers.
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Read also about Batch layer in streaming-based architectures - approaches here:
Related blog posts:
- Project Oryx - Lambda architecture for data science
- Data validation frameworks - Great Expectations and orchestration
- Data validation frameworks - Great Expectations classes
Implementing batch layer is often hard because of "too many, too small" files problem . In https://t.co/3M41rd9rI9 I propose a survey of 3 solutions with #ApacheKafka or #ApacheSpark apps.
— Bartosz Konieczny (@waitingforcode) April 25, 2019