
A new year is coming and it's a great moment to summarize what has happened in the blog and around!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Blog in 2022
This year I blogged less. I wrote only 67 blog posts. It's almost 30% less than last year and 50% than 2 years ago:
| Year | Blog posts |
|---|---|
| 2022 | 67 |
| 2021 | 92 |
| 2020 | 104 |
| 2019 | 111 |
You see the trend, don't you 🥺 ? I love blogging and the number has decreased almost by x2 in 4 years... Is it bad? Not at all. Despite my geeky and introverted nature I also love people and especially my little family and friends. Last year my lovely daughter was born and instead of writing blog posts, we simply spend time together 🙂 These 67 blog posts + fully remote work + family time + sport activity are more a sign of almost reaching a work-life balance. I still have some things to improve, but it's much better than it was!
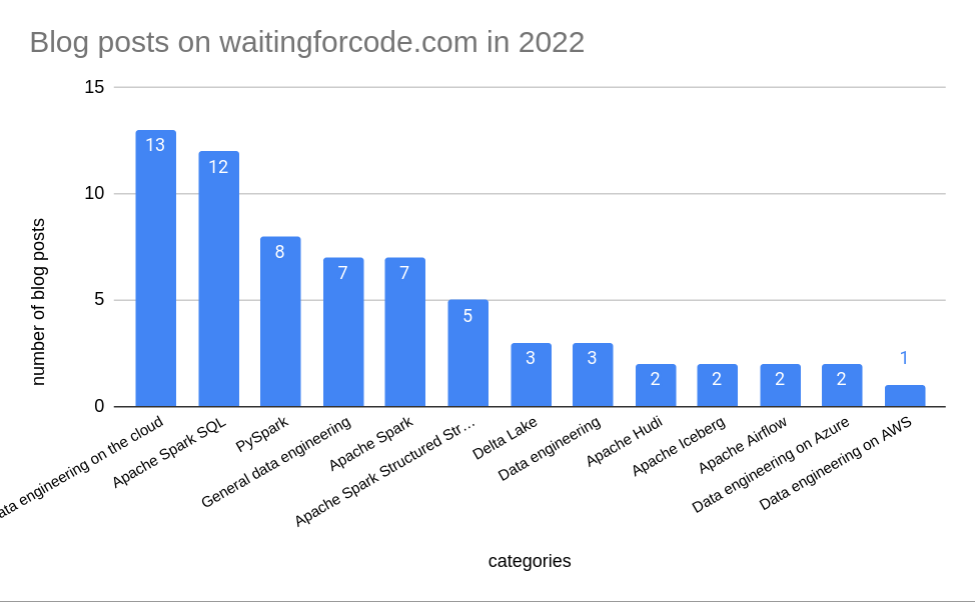
Among these 67 blog posts I wrote the most (13) for the Data engineering on the cloud category. Just behind there are 12 blog posts about Apache Spark SQL. The 3rd of the top 3 popular categories is ... PySpark! Understanding it was a missing piece in my Apache Spark exploration and I'm happy to finally start this part.
Among other things, I'm also very happy to start writing about table file formats. They all have roughly the same number of blog posts and the journey will continue next year. What could I have done better? I'm a little bit disappointed by the number of blog posts about Apache Spark Structured Streaming (5) but with Project Lightspeed, I should have much more work to do next year!
In a more fine-grained level, the most read blog posts were:
- Distinct vs group by key difference - 4762 views, published on 01/01/2022
- Task retries in Apache Spark Structured Streaming - 2958 views, published on 08/01/2022
- Shuffle configuration demystified - part 1 - 2855 views, published on 12/03/2022
- Reverse ETL - 2365 views, published on 09/01/2022
- Kubernetes concepts for Apache Spark - 2172 views, published on 08/01/2022
Blog and social media in 2022
In 2022 I also have made a decision to post regular updates on LinkedIn. I transformed my bi-weekly updates to update per blog post and the top 3 most engaging articles are:
- Serialization in PySpark - 86 engagements
- Shuffle in PySpark - 56 engagements
- Data contract - 46 engagements
I have a whole year history on Twitter and the top 3 are:
- Data+AI Summit retrospective, 50 engagements (comments + likes + retweets)
Want to hear about Apache Spark, data engineering and Delta Lake from the last #DataAISummit ? I watched several talks on these topics, took some notes and shared them in the new blog post ? https://t.co/Biz4mB3xgw
— Bartosz Konieczny (@waitingforcode) July 17, 2022 - Introduction to table file formats, 40 engagements
ACID file formats are one of my most important learning topics this year. Today I've published the first blog post of the series introducing the API with some code snippets ? https://t.co/dtvZGd8uHd
— Bartosz Konieczny (@waitingforcode) March 27, 2022 - Task retries in Structured Streaming, 38 engagements
How does Apache Spark handle task retries in #StructuredStreaming? That's the question I tried to answer in the new blog post ? https://t.co/D3ZjqHGsIt
— Bartosz Konieczny (@waitingforcode) January 15, 2022
Other projects
Blogging was not my single knowledge sharing activity last year. I also opened Become a Data Engineer classes and released my first ebook Data engineering patterns on the cloud.
Plans for 2023
Blogging:
- Apache Spark and cloud data engineering will remain my Pi-shaped profile topics.
- Develop the Table file formats series. Although I've written 8 blog posts last year, I'm not satisfied because I could only cover some of the most basic features. Hopefully, in 2023 I will do better!
- More pure data engineering topics. For sure, I've presented data contracts in 2022 but I have many more items in my backlog. Hopefully, I'll be able to integrate them either with Apache Spark or cloud data engineering branch.
- Rust. The last programming language I've learned on purpose was Scala. I even wrote a series to illustrate my journey called One Scala feature per week. I'm definitely not a Scala master but feel a need to learn something new. In the blog post about Python alternatives to PySpark I learned about Polars and was intrigued enough to add it to my topics for 2023.
- Apache Arrow. Polars, PySpark and Ray are 3 libraries mentioning Apache Arrow. So far I know it's a columnar memory format for efficient analytic operations but as for Rust, I'd like to know more!
Become a Data Engineer:
- One big update. I'm preparing a V2 of the course with some changes in the content and organization.
Data engineering patterns on the cloud:
- The first release has 84 patterns but I already added 20 other pattern candidates. There should be one or two updates including them in 2023.
Speaker:
- Even though I deliberately left this part aside, I missed it in 2022 a lot. Now, when my life seem to regain calm, it's probably the good moment to start again!
- I'm happy to share that I got my first CfP accepted! In March I'm going to speak at Big Data Warsaw about challenges of delivering streaming data at scale. I've plans to submit 2 other CfP I've been always dreaming about, so fingers crossed 🤞
Cloud data engineer:
- My data engineering certifications for AWS, Azure and GCP expire soon. It'll be time to renew them and why not share something more helpful to prepare them than a blog post?
All the above are just the plans. I know from the past that I might not fully succeed in reaching them. I may discover another exciting thing in 2023, take more time than expected for preparing the certification, or simply speak not at 3 but 6 conferences and have less time to check all the boxes. Anyway, I will share all the defeats and victories with you. Thank you for being with me in 2022 and hope you'll enjoy the next year too!
Wishing you all a happy, healthy and successful 2023!
Best,
Bartosz
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- 2025 retrospective on waitingforcode.com
- 2024 retrospective on waitingforcode.com
- 2023 retrospective on waitingforcode.com
Almost 3 days and we'll start a new year. That's a perfect time to write a short retrospective on what happened and what will happen on the blog ? https://t.co/TI8S2Puopl
— Bartosz Konieczny (@waitingforcode) December 29, 2022