
2021 comes to the end and as last year, it's a great moment to summarize what happened and what will happen in 2022!
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Blog in 2021
I blogged less (92 blog posts) than in 2020 (105). But I'm happy about that because I spent that time with my newborn daughter! And by the way, the article you're currently reading, is the number 800 on the blog! I hope to write you about a 1000th in 2 years 🤞.
Among these 92 blog posts, surprisingly I wrote the most (26) about Data engineering on the cloud. You will find Apache Spark only at the 2nd (17 for Spark SQL) and 3rd places (16 for Structured Streaming).
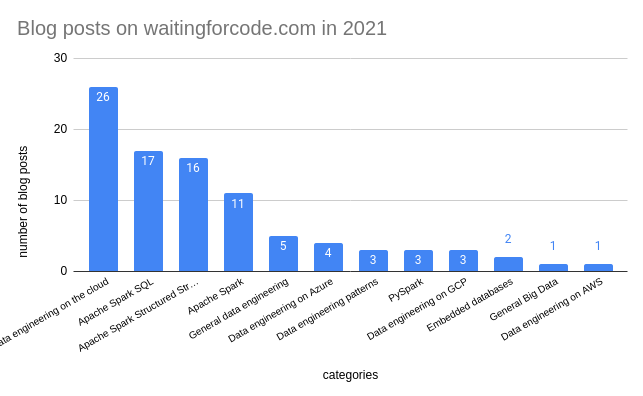
The diagram proves that for the first time I reached the goal set in 2020 which was to learn more about Apache Spark and data engineering on the cloud, and start building a Pi-shaped profile. Although I had been having multiple temptations, such as ACID-compatible file formats, Apache Flink for streaming processing, or Open Source data governance projects, this time I succeeded to respect the contract signed with myself last year in December.
For the most read blog posts, the Top 5 is:
- PySpark schema inference and 'Can not infer schema for type str' error
- Stack operation in Apache Spark SQL
- Performance optimization lessons from Spark+AI and Data+AI Summits
- GCP BigTable or AWS DynamoDB, yet another comparison
- What's new in Apache Spark 3.1 - JDBC (WIP) and DataSource V2 API
I'm quite surprised with the popularity of the first article. It's not the one I'm the most proud of but somehow it referenced pretty good and happens to be the most popular in 2021.
Changes in 2022
To start, a "new" country. After spending my whole adult life in France (almost 15 years), with my wife we decided to return to Poland. We don't know if it's the best choice. All we know is that it's the moment to try and live closer to the family. Our daughter doesn't go to school and although moving out with a small child is hard, it's easier than moving out and changing schools with an older one. Hence, if it was not now, it would probably never happen.
The moving out decision brings another change. I will leave my employee status and become a freelance data engineer. I'm a bit scared of potential administrative work to do as an entrepreneur and especially, the precious time I'll take. To overcome that, I'll probably need to learn tasks delegation and keep my energy for what makes me happy every morning.
I didn't mention freelancing without reason. It'll impact my organization and routine. I can't assume anymore to regularly get paid every month, so I'll have to find another income that at worse, could "pay the bills". That's why in 2022 I'll be working on extending my e-learning portfolio which probably will impact the blogging schedule.
Due to these changes, I'm not sure of being able to release 2 new blog posts each week. Probably sometimes it will be more, sometimes less, and for sure, sometimes I will have no-posts periods. Anyway, I will continue to inform you about the new blog posts on Twitter and newsletter.
Blogging topics for 2022
What about the topics you can expect next year on the blog? This time, I'll put the answer as a list:
- Apache Spark - there is no reason for me to stop. Although I had a pretty pleasant experience with Dataflow pipelines recently, I still enjoy writing Apache Spark jobs and exploring its implementation details! If possible, I'd like to cover a few PySpark topics this time.
- Data engineering on the cloud - it's a part of my Pi-shaped profile and I will definitely stay with this topic. But maybe a bit differently. In 2022 I'll continue writing comparison blog posts of data services on AWS, Azure, and GCP, but besides that, I'll also try to focus on a particular service and leverage as much as I can the power of video to demo it.
- Data engineering - I had some blog posts ideas last year but I put them aside to stay focused on the 2 aforementioned topics. Next year I'd like to write more about data engineering without necessarily connecting it to the cloud each time.
- Nice to have - I'm not signing a contract between them and myself but if somehow I manage to learn & share them, I'll be more than happy:
- Apache Flink or Apache Beam - I don't know yet. On one hand I know the latter a bit and could gain better expertise. But on the other hand, I'm very curious on how continuous streaming processing was implemented in Apache Flink.
- ACID file formats - there are a lot of things going on. Delta Lake, Apache Iceberg, or Apache Hudi, with an increased support on the cloud services, all this makes me think that it's better to start exploring them right now. As for the previous point, I don't know which one to choose. I'm tempted by exploring them all in the series of blog posts comparing their implementations for a given ACID file format feature.
As you can see, things will be different for me next year and will impact the blogging activity. Nonetheless, I hope you'll still be able to find interesting things on the blog. Thank you for being with me in 2021 and hopefully, see you next year!
Wishing you all a happy, healthy and successful 2022!
Best,
Bartosz
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- 2025 retrospective on waitingforcode.com
- 2024 retrospective on waitingforcode.com
- 2023 retrospective on waitingforcode.com
With 2021 coming to its end, it's a great time to do a retrospective on the blog. The new blog post summarizes what happened in 2021 and what are my plans for the next year ? https://t.co/cn7SFNdxU0
— Bartosz Konieczny (@waitingforcode) December 30, 2021
Happy, healthy and successful 2022!