
Tomorrow I will publish the 600th post on waitingforcode.com! At the very beginning of my blogging adventure in English I spent several months on Spring & Play Framework and only later I moved to the data engineering topics. From the time perspective, it was a good choice. I still enjoy writing about data engineering, its patterns, frameworks and cloud services. In this special article, I will share with you what happened last year and what are the plans for 2020.
What would it take for you to trust your Databricks pipelines in production?
A 3-day bug hunt on a 3-person team costs up to €7,200 in lost engineering time. This workshop teaches you to prevent that — unit tests, data tests, and integration tests for PySpark and Databricks Lakeflow, including Spark Declarative Pipelines.

Konieczny
Blog posts
First, some stats about the articles. In 2019 I published 111 blog posts (2 planned for the last weekend of 2019 aren't included) which gives approximately 2 blog posts per week. And that's the "contract" I signed with myself when I was launching waitingforcode.com.
Regarding the most popular categories, the winner is Apache Spark SQL with its 32 blog posts. Together with the runner-up, Apache Spark Structured Streaming (19 posts), they can make you think that the blog is exclusively about Apache Spark, but in fact, it's not. The next 3 positions show that I also try to cover more general concepts like data engineering patterns or data cloud services. I also wrote 5 posts about SQL, mainly because I experienced that SQL for a data engineer is like Java for a Spring programmer 4 years ago, the time I was still coding with that framework. The following chart shows the number of articles per category added in 2019:
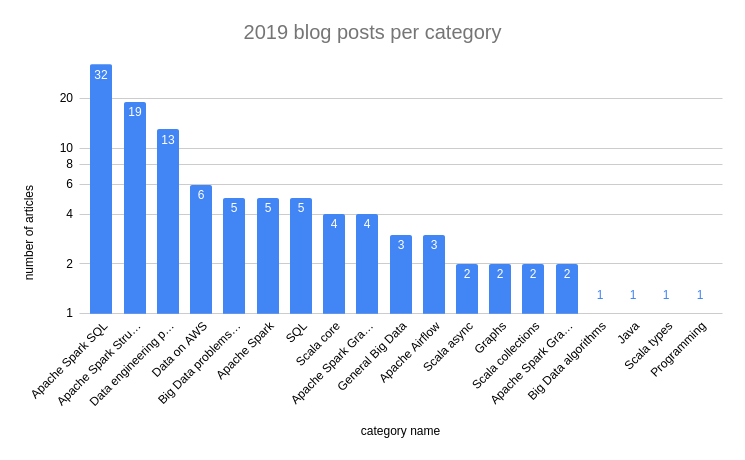
Even though waitingforcode.com is not only about Apache Spark, the 3 most read blog posts in 2019 were about Apache Spark. Overall, the most successful series was about Apache Spark 2.4.0 features. In the following list you can see that 5 of the 10 most popular articles belong to it:
- Apache Spark 2.4.0 features - array and higher-order functions
- Apache Spark 2.4.0 features - EXCEPT ALL and INTERSECT ALL
- Monotonically increasing id function in Apache Spark SQL
- Sealed keyword in Scala
- Doing data on AWS - overview
- Range partitioning in Apache Spark SQL
- Apache Spark 2.4.0 features - foreachBatch
- Memory and Apache Spark classes
- Apache Spark 2.4.0 features - barrier execution mode
- Apache Spark 2.4.0 features - Avro data source
Next year I will still write about Apache Spark but I will also try to vary a little by presenting you different frameworks, data stores and data concepts.You will learn more about my plans in the last section.
Social media
Before I explain you the plans for 2020, I'd like to share what happened on social media. The top 3 most liked articles from Twitter perspective are:
#SparkSQL custom optimization learning ongoing. This time I tried a reverse engineering approach to understand the API better: https://t.co/4GGjHGis6c
— Bartosz Konieczny (@waitingforcode) April 3, 2019Some time ago, I was analyzing the query plan generated by my #ApacheSpark app and found a mysterious partial operations. I decided then to investigate ?️♀️ and today's post starts a series about aggregations in #SparkSQL https://t.co/4VgaFJqxK5
— Bartosz Konieczny (@waitingforcode) October 12, 2019I'm still amazed by the features of #ApacheSpark #SparkSQL. Today I've just published a post about less known aggregation functions. If kurtosis sounds like a football player, var_pop like a JS variable, the post can shed light on it ? https://t.co/hc6fLSkgVW
— Bartosz Konieczny (@waitingforcode) September 21, 2019
Apart from them, I'm also proud of being quoted on Data Eng Weekly which for me is one of the best curated data engineering newsletters. The blog was present in 6 newsletters between January and March: Data Eng Weekly Issue #296, Data Eng Weekly Issue #297, Data Eng Weekly Issue #298, Data Eng Weekly Issue #301, Data Eng Weekly Issue #302, Data Eng Weekly Issue #306.
Next year
This not technical blog post is also a good occasion to share and challenge my plans for 2020. I'm very curious what do you think about them. Among the existent categories, as stated before, I will keep working on Apache Spark and with the brand new 3.0 release, I'm sure to have a lot of features to discover :) I will also try to reserve a little bit more time to Apache Kafka. You will see the first results of that next month!
In addition to the already present topics, I'll also cover new things. I will put a stronger accent on cloud data services, with a special focus on AWS and GCP. My "the Open Source project of the year" will be Apache Pulsar. A few months ago I saw different talks about the basics of this messaging system and they intrigued me sufficiently to add Pulsar to my backlog :) Finally, I will explore Kubernetes on the context of the data processing framework. Shame on me but after the years spent on YARN, I still don't feel comfortable with it because I've never felt interested by deepening delve like I did for Spark. This time it'll be different since I will try to learn more ops part at work and Kubernetes is automatically a part of that domain. Among general data concepts, I will do my best to learn more about data security, as well for the storage as for the processing parts.
And it wouldn't be possible without you ? I always appreciate your feedback. When you ask me some extra questions, when you create an issue on my Github with an article's suggestion, and of course when you say that the article was somewhat useful in your life ? It helps not only to keep my writing motivation up but also to learn new things. So, thank you very much for all that involvement!
Since the new year is coming closer, I wish you all the best in 2020 ? Make this new year to be better than 2019 but worse than 2021 :)
Data Engineering Design Patterns

Looking for a book that defines and solves most common data engineering problems? I wrote
one on that topic! You can read it online
on the O'Reilly platform,
or get a print copy on Amazon.
I also help solve your data engineering problems contact@waitingforcode.com 📩
Related blog posts:
- 2025 retrospective on waitingforcode.com
- 2024 retrospective on waitingforcode.com
- 2023 retrospective on waitingforcode.com
Yesterday was my birthday ? and tomorrow I will publish the 600th post on https://t.co/FBcfWSMrS9 ? I think it's a good time to write a short summary of what happened in 2019 and what will happen in 2020?https://t.co/maIxGNV9t1
— Bartosz Konieczny (@waitingforcode) December 27, 2019